Custom Models with Baselines: IMPALA CNN, CNNs with Features, and Contra 3 Hard Mode

Last month OpenAI had an interesting blog post and paper on generalization in Reinforcement Learning (RL). OpenAI created an environment called CoinRun to test the generalization capabilities of various agents. CoinRun is a video game like environment where the agent has to move a character past various obstacles to get a coin. The write up noted how much better performance was with the IMPALA Convolutional Neural Network (CNN) than the Nature CNN (default CNN in OpenAI Baselines). The code for CoinRun, the paper, and the IMPALA CNN is available on github. In this post I discuss setting up a custom model, using the IMPALA CNN with Baselines, and a customize model I use for beating level 1 of Contra 3 on hard mode.
Custom Model Setup
In an earlier post on basic Baselines usage I wrote about how to use custom models. The steps: define the model in a function, register the model, and call that name in the RL algorithm parameters. Example:
IMPALA CNN
I modified the CoinRun implementation of the IMPALA CNN to work with Baselines in this file. The IMPALA net in the image above is the one used in the original IMPALA paper and includes multiple residual blocks, a LSTM output layer, and a LSTM embedding component. The CoinRun implementation makes the LSTM output layer optional, does not have the LSTM embedding component, and adds batch norm and dropout (since CoinRun tests these techniques for their generalization effect). My Baselines implementation doesn’t have the LSTM output layer (though adding that is straightforward) and does not implement dropout (since I’m not testing for generalization). I did a simple test on Contra 3 (a Super Nintendo video game) to confirm that the IMPALA CNN works. Unfortunately, I put the wrong actions for the agent so I wasn’t able to do a fair comparison versus the Nature CNN on Contra 3 level 1. The agent learns to reach near the final boss on level 1 in easy mode which is kind of impressive since the agent isn’t able to jump or shoot in most directions. See the def impala_cnn() function in this file for more details.
Contra Custom Model
The hyperparameter settings I used for clearing level 1 on easy mode with the default Nature CNN also work on medium and hard mode. Medium is slightly harder than easy but still manages some 1 death episodes in under 30 million timesteps. In hard mode the agent struggles with the default CNN. The agent manages to clear some episodes in 6 or 7 deaths but not many. I added more features and modified the default CNN to greatly improve performance on the clearing level 1 in hard mode.
I added an additional layer for the CNN that contains the position of the player, enemies, enemy projectiles, invulnerable enemies, and enemies with health. Luckily someone had already done the work of finding where in the rom addresses all this information is stored. I modified the default WarpFrame wrapper to WarpFrameFeatures to include this additional layer. I basically scan the rom address for the information types, access the position information, and write that the positions to a series of 2D arrays. I have an array for each information type and at the end I add the arrays together and append it to the grayscale image.
I also added 15 scalar features that include things like what weapon is equipped in each slot and the number of bombs. However since Baselines doesn’t let us use dictionary observation spaces it is difficult to pass the 15 scalar features to the CNN. Instead I had to create a new 2D array, put the useful scalars in that array, and append it to the observation array. A bit of a waste and apparently there is a workaround in Stable Baselines but I haven’t tested it yet.
The new layers are passed to a modified Nature CNN. I wrote some bad TensorFlow code to split the scalar feature layer and concat those features to the output of the convolutional layers. See the contra_mixed_net function for the ugly details. I’m not sure of the ideal way to combine convolutional features and non-convolutional features in an RL model. That’s something I mean to research at some point. I also think the scalar features could be improved if I used a small embedding network for the weapon types rather than separately one hot encoding weapon 1 and weapon 2.
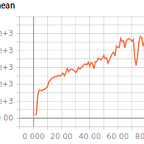
The new features help on level 1 hard mode. I tested the base model and the customized feature model on the same hyperparameters. While the wall time for the base model (23.1 hours) and feature model (22.6 hours) are roughly the same, the base model was able to perform roughly 50% more timesteps (30 million to 20 million) due to having less convolutional layers and parameters. Still the feature model had much better performance in terms of reward (peak of 1,400 episode mean reward versus 800 episode mean reward), median deaths (12 deaths versus 16 deaths), and minimum deaths (2 versus 6).
I’m also not sure how much of the difference in improvement is due to the scalar features and what part is due to the new CNN layer. I need to test the two separately. I should also test under different random seeds and different hyperparameter ranges, and try the IMPALA CNN and maybe try some more LSTM experiments… I’m not sure if I’m going to get around to running all those hours (2000?) of experiments but will hopefully have some more results at some point.
Here’s a video of the agent clearing level 1 on hard mode: