Implementing Unity Machine Learning into an Existing Game: Gridworld in Aurelian Tactics
I’m attempting to train an AI for a Unity game I made years ago called Aurelian Tactics. It’s a turn-based tactics game: imagine Chess except when pieces confront each other they uses attacks, abilities, and spells. Unity is a game engine that also has the Unity Machine Learning (Unity ML) package, which lets you use ML to train agents to perform tasks. Step 1 in this process was to learn the basics of Unity ML and implement tic-tac-toe in Unity ML, which I detailed in my last post. In this post I discuss how I implemented the Gridworld environment into my Aurelian Tactics game.
Gridworld is a classic Reinforcement Learning (RL) problem. In Gridworld an agent moves in a two dimension grid of squares. The agent tries to reach the goal in the minimum number of steps. Implementing Gridworld from scratch is straightforward. There are plenty of Python examples and even a Unity ML implementation.

The challenge here is making the Unity ML package work with the sprawling, often poorly written, mostly undocumented Aurelian Tactics code which was written years and years ago.
On the plus side, the idea of Gridworld is very compatible with Aurelian Tactics. In Aurelian Tactics characters move around a grid-like map trying to defeat enemies. Changing the goal from defeating enemies to reaching a certain grid square is simple to imagine. In theory, getting existing map production code and character movements to work with Gridworld is straightforward.

After a lot of thought and reviewing old code, I decided on the following rough outline:
- Create a new scene for Gridworld.
- Utilize existing code and scripts for creating a new map. Create new functions where necessary.
- Create Gridworld specific scripts for managing the Unity ML/RL parts.
- Train the agent.
Create a New Scene for Gridworld
I duplicated an existing Aurelian Tactics scene. This allowed me to take advantage of the camera controls and some existing scripts that make setting up the board and moving characters around easier. I deactivated parts of the scene that weren’t needed for Gridworld such as menus and dialogue boxes.
Utilize Existing Code
Most of this may be hard to follow since the code I modified isn’t very well written or documented. Hopefully my thought process will be helpful. I’ll include some links for those who want to see the actual code (not recommended). The Gridworld and Unity ML specific code is worth a quick look if you’re interested as that is much cleaner and could be useful if you’re working on your own Unity ML project.
CombatStateInit.cs is the old code for creating a map. Some minor alterations were needed to create a Gridworld specific map such as only creating one character and creating a goal. Most of this is written in InitGridworldLevel() where I create and load the map, create the character, and place the character and unit.
Board.cs is where Aurelian Tactics handles the map (the game board) information. I utilized existing functions to create a Gridworld specific board. A couple new functions here allowed me to place the goal and move the goal to a random place when the agent reached to goal.
PlayerManager.cs is where Aurelian Tactics handles many character related things like creating characters and moving characters. I utilized existing functions to create the unit. For the sake of simplicity and performance I added a new function to move the character, at the cost of not utilizing existing character animations.
Gridworld Specific Scripts
Most Unity ML examples and my tic-tac-toe implementation contain two Unity ML centric scripts. One script is called GridworldTacticsArea.cs. This script manages the Gridworld environment loop. The script resets the environment when the goal is reached, accepts actions from the agent and relays them to PlayerManager.cs to move the agent, assigns rewards (+1 for reaching the goal and -.1 for each move taken) and collects observations and sends them to the agent. Observations are necessary for training an agent to learn. My observations are in the form of an array with each part of the array corresponding to a square in the grid map. I mark the array with all 0’s (empty squares), a 1 for the square with the goal on it, and a -1 for the square with the agent on it. I wrote some simple functions in Board.cs to get the index for the goal square and PlayerManager.cs to get the index for the agent square.
The other Gridworld specific script inherits from Unity ML’s Agents.cs and is the script that drives the RL agent. In GridworldTacticsAgent.cs, the agent waits until RequestDecision() is triggered. Then the agent uses CollectObservation() to get observations, feeds them into a neural network, and produces an action which is relayed to OnActionReceived() which starts the process of moving the agent.
Once I wrote the scripts, I added them to the GridworldAT scene along with Unity ML’s required BehaviorParameters.cs script. The Unity ML documents describe how the BehaviorParameters work, such as how to set necessary things like the observation size (in my case the number of squares on the board) and the action space (no action, up, down, left, and right).
Train the Agent
Training the agent was incredibly simple this time. The code was almost completely bug free. I used the standard Unity ML process: create a config file (GridworldAT.yaml), run the script from the terminal, and then press play in the Unity application. To train the agent, I used the SAC algorithm with the same hyperparameters from Unity’s Gridworld.yaml file.
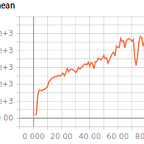
mlagents-learn GridworldAT.yaml --run-id=gwat3Tensorboard plots showed that the agent basically solved the game after 300,000 steps:

Here’s the trained agent in action:
Issues
- This is a stripped down version of Gridworld. I have a list of possible improvements to this version of Gridworld (different board size, obstacles, character animations, etc) that could be implemented but would require more flexibility in the code. For example, when a unit moves in Gridworld I simply move it rather than have it follow the character animations for moving and turning. This makes it much faster to train an agent since it doesn’t have to wait for moving to finish. Because this is an intermediate step in getting an RL agent working in the full Aurelian Tactics I went for simplicity rather than flexibility.
- Similar to tic-tac-toe, I had issues getting heuristic (human controlled) mode to work cleanly. Pressing a direction causes the agent to keep moving in that direction until a different direction is pressed. This didn’t effect the RL agent though so I ignored it.
- How I wrote Aurelian Tactics isn’t that friendly with Unity ML. One of the things Unity ML examples often do is duplicate the same environment in the scene multiple times for faster training. For example in tic-tac-toe I trained the 12 simultaneous tic-tac-toe boards at the same time while in this Gridworld implementation I only trained one. My existing code could be modified to allow multiple boards at the same time but it will take a lot of work.
- The observations space is not ideal. I would like to run a CNN over a two-dimensional observation space representation since the Gridworld information is spatial. However I’m not sure how to do that with Unity ML unless I use the actual visual observations, which generally are harder to train on and contains a lot of irrelevant information.
Up Next
To train an agent on the full Aurelian Tactics is going to require hundreds of millions of steps in the environment. A reasonable next goal is to try a one vs. one character duel version of Aurelian Tactics. However I’m not quite sure how I want do this. Increasing the simulation speed is important. I could make a ‘headless mode’ that simulates the game without updating anything graphically or modify the game code to allow multiple game boards to be run at the same time. Both look to be lengthy processes. I could try a stripped down, simplified version in the mean time but most of that code would be redundant if I do decide on a headless mode or multiple game boards.
I also think I may be starting to reach the limits of the existing Unity ML framework in some places. I’m not sure I can fit my ideal observation and action spaces for the game into the options that Unity ML asks for. I’ll have to see how flexible Unity ML can be or if I’ll have to use one of the Unity ML APIs to turn my environment into an environment more compatible with OpenAI’s gym.
Edit 1/12/21:
I tried a one vs. one game mode of AT but training was unsuccessful. The environment only managed 60k timesteps in a day of training. A much faster mode is needed, which I’ve been slowly working on. I’ll write a new post about it eventually.