Location CNN and Pygame Learning Environment in Ray
Two recent papers came out that discussed the same issue: how to utilize location information in Convolutional Neural Networks. Basic CNNs are useful for their ability to pick out the similar objects at different locations in the image (translational invariance). However this translational invariance means that the location information is largely ignored. The location image of an object can be useful in some situations. The two papers, Location Augmentation for CNN and An intriguing failing of convolutional neural networks and the CoordConv solution, demonstrate a simple change to the CNN input can lead to the CNN better utilizing location information. The latter paper applies this location CNN to a Reinforcement Learning (RL) problem and achieves some modest results.
As a small mini project I implemented the TensorFlow code provided in the latter paper to the RL library ray. I tested the implementation on Pygame Learning Environment (PLE). PLE is a simple OpenAI gym like environment that contains some simple games like Flappy Bird, Snake, and more. I hope this post will be useful to those who are interested in seeing a simple implementation of a paper to code and looking to extend ray to custom environments.
Both papers had the same general takeaways when it came to location CNNs:
- Adding an x-coordinate channel (explained below) and a y-coordinate channel to the model is enough to produce results.
- Adding a third channel that is a distance transform can sometimes help.
- Only adding one channel of combined x-y coordinates does not produce results.
Let’s say you are working with images that are 100 by 100 pixels. An x coordinate channel would be a 100 by 100 matrix that goes from 1 to 100 in every row. The rows increase in value as you move horizontally through the matrix but every row is the same. A y coordinate channel would be a 100 by 100 matrix that goes from 1 to 100 in every column. Every column is the same. An x-y coordinate channel has a unique value at each point based on the x and y coordinate. Some images from the papers:


The CoordConv paper provides the TensorFlow code at the end of the paper. I added this to ray by modifying the default CNN ray uses when it detects that the input is a visual observation. My modified version is here. I added the paper’s code to ray’s misc.py file here. An excerpt of the modified code from my visionnet.py file:
In the file where I ran ray from I added some custom options. In the visionnet.py file if those options are found, the paper’s AddCoords code is loaded from misc.py and the x, y and optional distance transform channels are added to the CNN. Inputs observed from the RL environment will have those channels appended to the end observations and the CNN will be applied to the augmented observations.
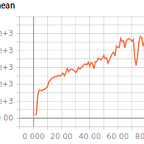
I used this location CNN on PLE and the game Catcher. In Catcher the agent moves a paddle left or right to catch fruit falling from the ceiling. The game ends if you miss three pieces of fruit. Since there is no victory condition, I added an end condition if the RL agent successfully catches 100 pieces of fruit. Without this a well trained agent would have episodes of infinite length and training statistics would be hard to calculate.

The file I used to run ray uses PLE rather than a default OpenAI gym environment. This requires some custom environment creation and preprocessing code. ray’s guide to preprocessing is straightforward:
- import Preprocessor
- inherit the Preprocessor class with your own custom preprocessor
- override _init (with your observation shape) and transform (with how you want to alter the observation)
- register the custom Preprocessor with ModelCatalog
- in your config file, set the “custom_preprocessor” argument
From the file I used to solve catcher:
from ray.rllib.models import ModelCatalog
from ray.rllib.models.preprocessors import Preprocessorclass PLEPreprocessor(Preprocessor):
def _init(self):
self.shape = self._obs_space.shape def transform(self, observation):
observation = observation / 255.0
return observationModelCatalog.register_custom_preprocessor("ple_prep", PLEPreprocessor)'config': {
...
'model':{ "custom_preprocessor": "ple_prep",
'custom_options':{
'add_coordinates': True,
'add_coordinates_with_r':False
}
...
To define a custom environment in ray see the custom ‘class PLEEnv(gym.env):’ that I defined. ray needs to be able to access the expected methods and values that a typical gym env would have. In my custom PLEEnv I defined the env, action space, observation space, and added frame stacking (so the last 4 screens from the game would make up an observation space). Since PLE defines their step (PLE uses act) and reset (PLE uses reset_game) functions differently I had to define custom methods in PLEEnv to handle the differences.
Also of interest is the rollout file used to see the trained model in action. To use the ray train and rollout files with other PLE games some modifications can be made to the ‘game = Catcher()’ the ‘from ple.games.catcher import Catcher lines.
It’s unclear how useful the location CNN actually is to solving RL problems. The Coord paper had modest results on 9 Atari games using A2C (6 showed improvement, 2 the same, 1 had worst results) and inconclusive results using Ape-X. In my limited experiments Catcher is simple enough to be solved with and without the location CNN. A more rigorous experiment with PLE and location CNNs would involve more games, more algorithms, track wall time and timesteps to along with performance.