Setting Up Unity ML Agents with Ray and Stable Baselines
I’ve been using the Unity game/simulator engine for a Reinforcement Learning (RL) project. I’ve been playing with the Unity Machine Learning toolkit (ML agents) and using it with the RL libraries Ray and stable baselines. In this post I’ll go over the main steps to setting up the packages and some sample scripts that run some RL agents in Ray and stable baselines.
Overview
Unity ML agents is a plug in that lets you train RL agents on Unity environments. There are a few different ways to train with ML agents. You can either train on an open instance of Unity or build the Unity environment and train with that executable. Training with the environment can be through ML agents’ built in PPO algorithm, ML agents’ Python API, or ML agents’ gym wrapper. The gym wrapper takes the Unity environment and makes it behave like an OpenAI gym environment, which allows for easy integration with RL libraries like Ray and stable baselines. This example will use a built Unity environment executable and the Unity gym wrapper.
Installation
The Unity ML docs has all the details on installation. I was able to install Unity and Unity ML on a Windows and Ubuntu machine. I ran the RL parts on the Ubuntu machine — Ray is Linux only as far as I’m aware — though stable baselines may work with Windows.
Main steps:
- Install Anaconda
- Install Unity and ML Agents
- Install the Unity gym environment (link has RL examples for the Dopamine and baselines RL libraries)
- Build the Unity executable. The linked example is for the 3DBall environment, I use the Basic environment in the code below. The steps are pretty much the same.
- Optional: verify installation and executable by running this Jupyter notebook (may need to modify some code based on which executable you made)
- Install stable baselines
- Install Ray
The Basic Environment
Unity comes with some environments or you can make your own (which I am working on). For this example, I’m using the Basic environment. In Basic, if the agent moves left a few steps it receives a reward. If the agent moves right 7 steps it receives a large reward. The agent receives a small negative reward every step and the episode ends when the agent gets the small or large reward. The observation is a vector of 0’s for each possible agent position along the line and a 1 for the position the agent is in.

The Unity ML agents arxiv paper has the benchmarks for the environments. For Basic, the benchmark is 0.94 which is have the agent move right every step and receive the large reward every episode. The paper only has PPO results and encourages others to try different algorithms and benchmark their performance which is sort of what we’ll do the rest of this post.
Stable Baselines Benchmarks
Since Basic is such a simple environment, I was able to train an agent with most stable baselines algorithm with the default hyperparameters to solve Basic. Here’s a gist of the main parts, for the full scripts see the repo:
Pretty straight forward. The Unity gym wrapper takes the built Unity executable (env_id) and a worker_id (needed for multi env runs and Ubuntu issues). use_visual is False in this case since the env observations are vectors and not images. You can set no_graphics to True to render the env and see the agent in action. The next three lines are simple stable baselines code with no hyperparameter tuning need.
To run a multiple environments some slight modifications are needed:
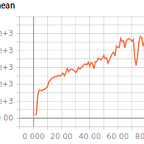
The worker_id argument is needed and each env needs its own unique one. The repo has scripts for the six stable baselines algorithms (PPO, DQN, A2C, ACER, TRPO, and ACKTR) I used to solve the Basic env. A training plot shows that all algorithms quickly reach the max reward with almost no hyperparameter tuning (I disabled entropy coefficient and increased the training timesteps for a couple of the algorithms).

As for the other stable baselines algorithms not in the above plot; DDPG, TD3, and SAC require continuous action spaces, I couldn’t get HER to work with the Unity env, and while I could train the expert for GAIL successfully I couldn’t get results with GAIL in very limited attempts.
A couple things to note:
- I couldn’t get a score higher than 0.93. I think the 0.94 benchmark is either a typo or using a prior version of Basic.
- The Unity ML Python API has a way to set the env seed but the gym wrapper hasn’t implemented it yet, though that seems like a quick pull request.
Ray Benchmarks
The Ray hyperparameters requires some adjustment since the default settings are for a such high number of iterations. Like for PPO I turned the train batch size from 4000 down to 500. The code is also straightforward:
For Ray I had to turn the UnityEnv into a custom environment and then register it with Ray. Once again note the need to increment the worker_id for multiple env usage.

I solved the basic env with DQN, IMPALA, PPO, PG, and A3C. I had issues with the ARS and ES working with the Unity environment and getting any results but didn’t look into it too thoroughly.
All the scripts can be found in this repo, though they are mostly the same as the above gists. At some point, I hope to do some posts on my custom env and maybe benchmarking some more difficult Unity envs.