Doğrusal Regresyon Algoritmasının Mantığı ve Uygulanması

Tıbbi masrafların tahmin edilmesi zordur çünkü onu tahmin ederken kullanılan birçok farklı değişken bulunmaktadır. Yine de, bazı koşullarda belirli kişiler için bu masraflar daha belirgin olabilir. Örneğin, akciğer kanseri sigara içenler arasında sigara içmeyenlere göre daha fazladır ve kalp hastalığı obezler arasında daha muhtemel olabilir gibi koşullar nüfusun belirli kesimleri için daha yaygın olarak kullanılabilir.
Bu projenin amacı, sağlanan nüfus segmentleri için regresyon kullanarak ortalama tıbbi bakım masraflarını tahmin etmek için hasta verilerini kullanmaktır. İşimizin bir kısmı, veri setindeki özelliklere sahip olan gelecekteki bir kişinin hangi tedavi masrafları olabileceğini tahmin etmektedir.
Aşağıda veri setine ait bazı özellikler verilmiştir:
· age (yaş): birincil yararlanıcının yaşı
· sex (cinsiyet): sigorta yüklenicisi cinsiyet: kadın, erkek
· bmi: Vücut kütle indeksi, vücut hakkında bir anlayış, boyuta göre nispeten yüksek veya düşük ağırlıklar, boy ağırlığına oranla objektif vücut ağırlığı endeksi (kg / m ^ 2), ideal olarak 18,5 ila 24,9
· childeren (çocuklar): Sağlık sigortası kapsamındaki çocuk sayısı / Bağımlı sayısı
· somoker (sigara bağımlılığı): evet, hayır
· region (bölge): yararlanıcının ABD’deki yerleşim bölgesi, kuzeydoğu, güneydoğu, güneybatı, kuzeybatı.
· charges (masraflar): Sağlık sigortası tarafından faturalandırılan bireysel sağlık masrafları
Bu veri seti göz önüne alındığında, bir kişinin tedavi masraflarını, kişinin yaşı, vücut kütle indeksi yada veri setinde bulunan herhangi bir özellikleri ile arasındaki ilişkiye yani korelasyona bakılarak tahmin edilebilir.
Doğrusal regresyon, iki veya daha fazla değişken arasındaki ilişkiyi tanımlamak için kullanılan doğrusal bir modelin yaklaşımıdır. Basit doğrusal regresyonda iki değişken vardır: bağımlı değişken ve bağımsız değişken.

Doğrusal regresyondaki kilit nokta, bağımlı değerimizin sürekli olmasıdır. Bununla birlikte, bağımsız değişkenler kategorik veya sürekli bir ölçüm ölçeğinde ölçülebilir olmalıdır. İki tür doğrusal regresyon modeli vardır. Bunlar: basit regresyon ve çoklu regresyon. Basit doğrusal regresyon, bağımlı bir
değişkeni tahmin etmek için bir bağımsız değişken kullanıldığında gerçekleşir. Örneğin, “yaş” değişkenini ile “sigara bağımlılığı” değişkeni arasındaki ilişkiye bakılarak ilgili yaşa sahip bir kişinin sigara kullanımı tahmin edilebilir. Birden fazla bağımsız değişken mevcut olduğunda, işleme çoklu doğrusal regresyon adı verilmektedir. Örneğin, “yaş” ve “cinsiyet” kullanarak “sigara bağımlılığı” tahmin etmek. Şimdi, doğrusal regresyonun nasıl çalıştığını görelim. Veri setimize tekrar bakalım. Doğrusal regresyonun anlaşılması için değişkenlerimizi buraya çizebiliriz.

“bmi (vücut kütle indeksi)” bağımsız bir değişken ve “charges” tahmin etmek istediğimiz hedef değer olarak gösteririz. Bir dağılım grafiği, bir değişkendeki değişikliklerin diğer değişkende “açıkladığı” veya muhtemelen “neden olduğu” değişkenlerin arasındaki ilişkiyi açıkça gösterir. Örneğin, “bmi” arttıkça, “charges” da artar. Doğrusal regresyon ile bu değişkenlerin ilişkisini modelleyebilirsiniz. Her bir kişinin yaklaşık “charges” ne kadar olduğunu tahmin etmek için iyi bir model kullanılabilir.
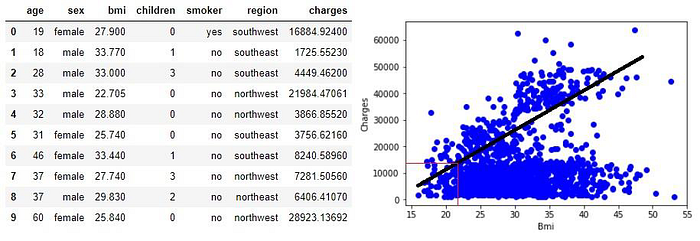
Şimdi bu çizgiyi tahmin için nasıl kullanırız? Bir an için bu çizginin iyi bir veri uyumu olduğunu varsayalım. Bilinmeyen bir kişinin masraflarını tahmin etmek için kullanabiliriz. Örneğin, vücut kütle indexsi “bmi” 23 olan bir kişinin masrafları 12000 olduğunu söyleyebiliriz.
Şimdi, bu hattının gerçekte ne olduğu hakkında konuşalım. Hedef değeri tahmin edeceğiz, “y”. Bizim durumumuzda, x1 ile temsil edilen bağımsız değişken olan “bmi” kullanılır. Uygun çizgi geleneksel olarak bir polinom olarak gösterilmektedir. Basit bir regresyon probleminde modelin şekli θ0 + θ1 * x1 olacaktır. Bu denklemde y dependent (bağımlı değişken) veya tahmin edilen değerdir ve x1 bağımsız değişkendir; θ0 ve θ1, ayarlamamız gereken satırın parametreleridir. θ1, fitting çizgisinin “eğimi” veya “gradyanı” olarak bilinir.
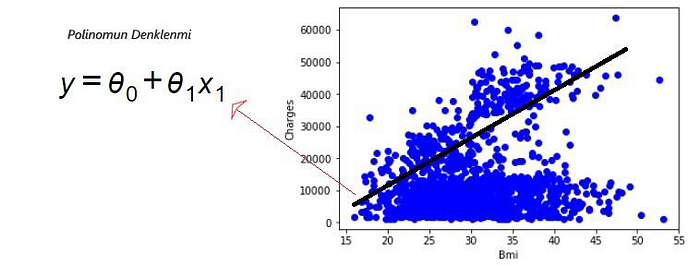
θ0 ve θ1 ayrıca lineer denklemin katsayıları olarak da adlandırılır. Şimdi soru şu: “Noktaların arasından nasıl bir çizgi çekersiniz?” Ve “Hangi çizginin” en uygun “olduğunu nasıl belirlersiniz?” Doğrusal regresyon, çizgi katsayılarını tahmin eder. Bu, verilere en uygun hattı bulmak için θ0 ve θ1 değerlerini hesaplamamız gerektiği anlamına gelir.
Bu çizgi, bilinmeyen veri noktalarının “charges” en iyi şekilde tahmin eder. Bu çizgiyi nasıl bulabileceğimizi veya çizgiyi verilere en uygun hale getirmek için parametreleri nasıl ayarlayabileceğimizi görelim. Bir an için, verilerimiz için en uygun hattı bulduğumuzu varsayalım. Şimdi tüm noktaları gözden geçirelim ve bu çizgiyle ne kadar iyi uyuştuklarını kontrol edelim. Buradaki en uygun yöntem, örneğin, grafiğe göre x1 = 23 vücut kitle indeksine sahip bir kişinin Charges = 10000 olması demektir. Bu değerlerde veri setimizdeki değerler ile örtüşmektedir. Fakat belirlenen çizgiyi kullanırsak x1 = 23 için Charges= 22000 çıkmaktadır.
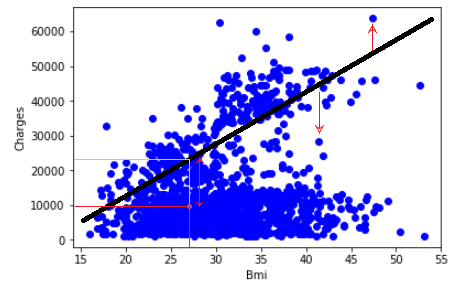
Şimdi, kişinin masraflarının gerçek değerini, modelimizi kullanarak tahmin ettiklerimizle karşılaştırırsanız, 1200 birimlik bir hatamız olduğunu göreceksiniz. Bu, tahmin çizgimizin doğru olmadığı anlamına gelir. Bu hataya “artık hata” da denir. Böylece, hatanın veri noktasından adapte edilmiş regresyon hattına olan mesafe olduğunu söyleyebiliriz.

Artık hataların ortalaması, çizginin tüm veri kümesine ne kadar uygun olduğunu gösterir. Amacımız, tüm bu hataların ortalamasının en aza indirildiği bir çizgi bulmak. Başka bir deyişle, fit çizgisini kullanan tahminin ortalama hatası en aza indirmektir. Daha teknik olarak söyleyelim. Doğrusal regresyonun amacı, bu MSE denklemini en aza indirmek ve en aza indirmek için en iyi , θ0 ve θ1 parametrelerini bulmaktır.
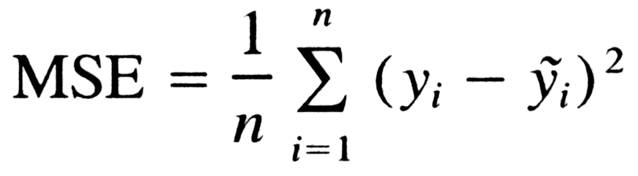
Şimdi, soru şu, θ0 ve θ1'i hatayı en aza indirecek şekilde nasıl bulabilirim? Böyle mükemmel bir çizgiyi nasıl bulabiliriz? Ya da, başka bir deyişle, hattımız için en iyi parametreleri nasıl bulmalıyız? Çizgiyi rastgele hareket ettirmeli ve her seferinde MSE değerini hesaplamalı mıyız ve minimum değerini mi seçmeliyiz? Aslında, doğru çizgiyi bulmak için burada iki seçeneğimiz var: 1. Matematiksel bir yaklaşım yada 2. Bir optimizasyon yaklaşımı kullanabiliriz.
θ1 ve θ0'i bulmak için matematik formülünü nasıl kolayca kullanabileceğimizi görelim. Daha önce de belirtildiği gibi, basit doğrusal regresyonda θ0 ve θ1, fit çizgisinin katsayılarıdır. Bu katsayıları tahmin etmek için basit bir denklem kullanabiliriz. Yani, sadece 2 parametreli basit bir doğrusal regresyon olduğu ve θ0 ve θ1'in hattın kesilmesi ve eğimi olduğunu bilerek, onları doğrudan verilerimizden tahmin edebiliriz.
Bağımsız ve bağımlı veya hedef sütunların ortalamasını veri kümesinden hesaplamamız gerekir. Tüm verilerin parametreler arasında geçiş yapmak ve hesaplamak için hazır olması gerektiğine dikkat edin. Kesişim ve eğimin bu denklemler kullanılarak hesaplanabileceği gösterilebilir. θ1 değerini tahmin ederek başlayabiliriz.

Veri setimizdeki verilere dayanarak bir çizginin eğimini bu şekilde bulabilirsiniz. X1, veri setimizdeki “bmi” için ortalama değerdir. Lütfen burada veri setimizin 10 satır olduğunu düşünün. İlk önce, x1'in ortalamasını ve y’nin ortalamasını hesapladık. Sonra θ1'i bulmak için eğim denklemine bağlarız. Denklemdeki xi ve yi, bu hesaplamaları veri setimizdeki tüm değerler arasında tekrarlamamız gerektiği ve i’nin x veya y’nin değeridir.
Tüm değerleri uygulayarak, θ1 = 397; bu bizim ikinci parametremiz. Çizginin kesiştiği ilk parametreyi hesaplamak için kullanılır. Şimdi θ1'i bulmak için θ1'i line denklemine bağlayabiliriz. Kolayca θ0 = 1012 olarak hesaplanır. Dolayısıyla, bunlar, θ0'ın yanlılık katsayısı olarak da adlandırıldığı ve θ1 “charges” sütunu için katsayısı olan çizgi için iki parametredir.
Şimdi çizginin polinomunu yazabiliriz. Böylece, verilerimize ve denklemine en uygun olanı nasıl bulacağımızı biliyoruz. Şimdi soru şu: “Yeni bir kişinin masraflarını vücut kütle indeksine göre tahmin etmek için nasıl kullanabiliriz?” Doğrusal denklemin parametrelerini bulduktan sonra, tahmin yapmak belirli bir girdi grubu için denklemi çözmek kadar kolaydır.
Bu problem için doğrusal regresyon modelinin gösterimi şöyle olacaktır: y = θ0 + θ1 * x1 veri setimizde birinci satırı baz alırsak charges = θ0 + θ1 * bmi olur. Gördüğümüz gibi, az önce konuştuğumuz denklemleri kullanarak θ0, θ1 değerini bulabiliriz. Bulduktan sonra, doğrusal model denklemini kullanabiliriz.
Örneğin, θ0 =1012 ve θ1 = 397 kullanalım. Böylece, lineer modeli charges = 1012 + 397 * bmi olarak yeniden yazabiliriz. Şimdi veri setimizin olmayan bizim değerlerini belirlediğimiz bir kişinin ücretlerini hesaplayalım. Bu kişin “bmi” değeri 34.770 olsun. Eğitim setimizdeki verilere göre çıkartılan linear doğrunun katsayılarını kullanarak ilgili “bmi” değerine sahip bir kişi için ücretleri hesaplayalım. charges = 1012 + 397 × 34.770 bu kişinin ücretleri 133.441.472 olarak çıkmaktadır.

Lineer Regresyonun neden bu kadar kullanışlı olduğu hakkında biraz konuşalım. Kullanımın oldukça basit olmasıdır. Aslında, Doğrusal Regresyonun bu kadar faydalı olmasının asıl nedeni hızlı olmasıdır. Ayrıca parametrelerin ayarlanması gerekmez. Bu nedenle, K-NN algoritmasında ki K parametresini ayarlamak veya Sinir Ağları’ndaki öğrenme oranı gibi yapıları Lineer Regresyonda dert etmeye gerek yoktur. Lineer Regresyon da kolayca anlaşılabilir ve yorumlanabilir.
