[WEEK 2–ARTIFICIAL REAL ESTATE AGENT]
Theme: Image Classification and House Price Estimation with Visual and Textual Features
Team Members: Gökay Atay, Ilkin Sevgi Isler, Mürüvet Gökçen, Zafer Cem Özcan

REMINDER
The goal is to predict the values of the houses correctly. To do this we have to follow these steps.
We’ll use some features like location, number of rooms etc., but the main thing is adding the luxury levels of each house to these data, according to their photos. And to do that first we have to categorize the pictures as a bathroom, bedroom etc., because we think not all users are going to tag their photos depend on their types. With that, we would be able to compare the in-kind rooms with each other.
- We need to categorize the photos according to their types.
- We need to classify these rooms depending on their luxury levels.
- Using these luxury levels and the other data we have, we need to estimate the price of the house.
IMAGE CLASSIFICATION

As we have mentioned previous week, for the image classification task, we are planning to use a deep learning model called Convolutional Neural Network (CNN or ConvNet). CNN is a class of deep, feed-forward artificial neural networks, most commonly applied to analyzing visual imagery. CNN helps to reduce the number of parameter required for images over the regular Neural Network (NN). Also, it helps to do the parameter sharing so that it can possess translation invariance. A simple ConvNet is a sequence of layers, and every layer of a ConvNet transforms one volume of activations to another through a differentiable function. We use three main types of layers to build ConvNet architectures: Convolutional Layer, Pooling Layer, and Fully-Connected Layer (exactly as seen in regular Neural Networks). Stacking these layers form a full ConvNet architecture.
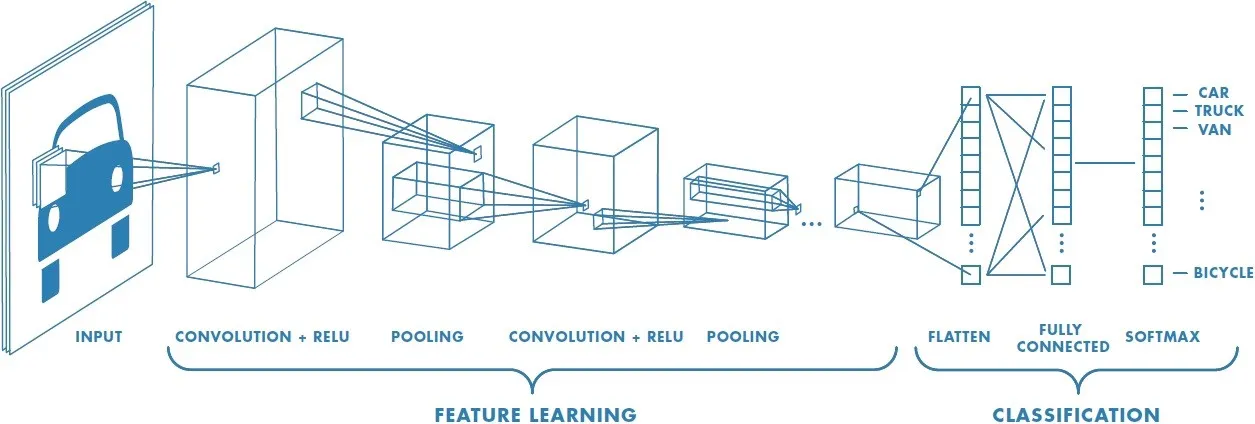
We have four classes to classify which are bedroom, bathroom, kitchen and frontal view. For this task, we intend to use transfer learning to solve the classification problem. Transfer learning is the improvement of learning in a new task through the transfer of knowledge from a related task that has already been learned.

Here is an architecture of InceptionV3. InceptionV3 is trained for the ImageNet Large Visual Recognition Challenge using the data from 2012. For the second week, we have used InceptionV3’s pre-trained weights to classify images. We have frozen all the layers and only trained the fully-connected layer with our class labels. Since this architecture is used for a related task, the classifier accuracy was decent which is around 90% accuracy.


We have arranged the code for ~200 epochs, and we have set up early stopping condition. If validation accuracy does not increase for 30 epochs, the execution ends and saves the model with maximum validation accuracy. For this case, on epoch = 29, model gave the maximum validation accuracy and it took about 5 hours to train the model.
Epoch 00059: val_acc did not improve from 0.90517
Epoch 00059: early stopping
Passed Time: 5:21:25.383212
InceptionV3 architecture was only an initial starting point for our image classification task. For the upcoming weeks, we will try different architectures such as VGG19, AlexNet and ResNet. We will also compare them w.r.t their accuracy, parameters, training time etc.

Also, for the upcoming weeks we might consider using Support Vector Machine (SVM) instead of a fully-connected layer and compare their results.