[Week 1– ones-and-zer0es]
Theme: Learning Based Image Colorization
Team Members: Bugrahan Akbulut, Gökay Atay

REMINDER
Image colorization assigns colors to a gray-scale image, which is an important yet difficult image-processing task encountered in various applications. As we discussed on the previous week’s post, we are going to colorize an image using learning-based approach.


Deep learning based solutions got wonderful results in modeling large-scale data recently. Their learning ability can outperform humans on some computer vision and image processing problems such as classification, pedestrian detection, image super-resolution, photo adjustment etc. Proposed method directly establishes color relationships between features of the input gray-scale image and color information of the reference color image based on the corresponding training pixels. The success of deep learning techniques motivates us to explore its potential application in our context.
TESTING OF PRE-TRAINED MODEL
We have decided to use Colorful Image Colorization work (Zhang, R., Isola, P. and Efros, A.A., 2016. Colorful image colorization. European Conference on Computer Vision) as a baseline.

Convolutional Neural Network (CNN or ConvNet) is a deep learning model. CNN is a class of deep, feed-forward artificial neural networks, most commonly applied to analyzing visual imagery. CNN helps to reduce the number of parameter required for images over the regular Neural Network (NN). Also, it helps to do the parameter sharing so that it can possess translation invariance. A simple ConvNet is a sequence of layers, and every layer of a ConvNet transforms one volume of activations to another through a differentiable function. We use three main types of layers to build ConvNet architectures: Convolutional Layer, Pooling Layer, and Fully-Connected Layer (exactly as seen in regular Neural Networks). Stacking these layers form a full ConvNet architecture.
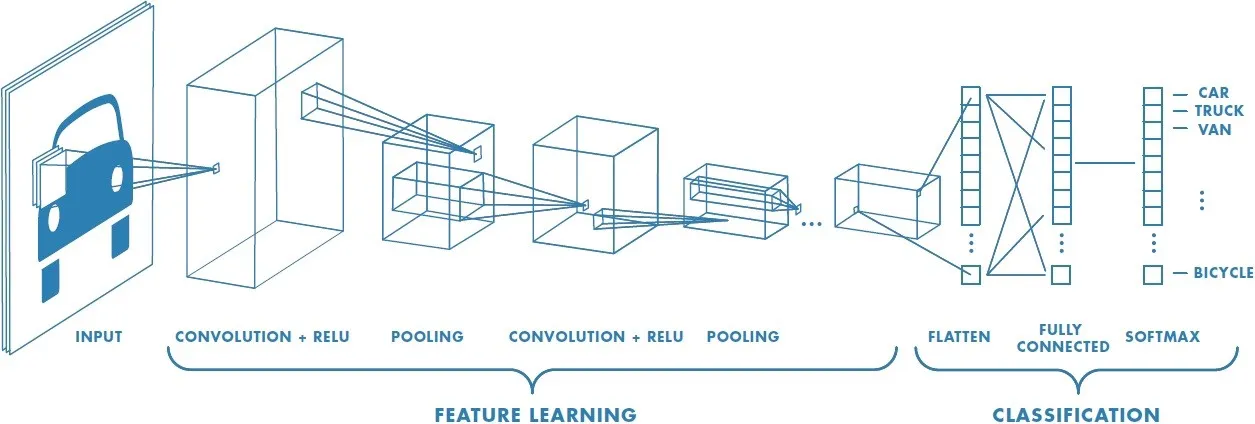
In Colorful Image Colorization project, they train a CNN to map from a grayscale input to a distribution over quantized color value outputs using the architecture shown below.

We have gotten their model and tested pre-trained model using some images. Here are some good examples that produce decent results which we consider as 1s.




We also tested pre-trained model with some edge-case images such as images from an anime (Death Note). Since project team’s training images contains real-life images, the test result of images like anime type are bad as expected which we consider as 0s. But, in general, the model performs very good. An example of 0 image is shown below.


OUR APPROACH
Since we are getting bad results for anime images, we might consider extending the training dataset with these images, also we can use some data augmentation techniques. This approach will make 0s (false colorizations) 1s (true colorizations).
For another improvement, we intend to change architecture of the model. Current architecture is similar to VGG architecture (excluding pooling and fc layers). The VGG network architecture was introduced by Simonyan and Zisserman in their 2014 paper, Very Deep Convolutional Networks for Large Scale Image Recognition. This network is characterized by its simplicity, using only 3×3 convolutional layers stacked on top of each other in increasing depth. Reducing volume size is handled by max pooling. Two fully-connected layers, each with 4,096 nodes are then followed by a softmax classifier (above). So, for other task, we want to change the architecture of the model, and convert it to ~ResNet architecture and visualize the performance changes.