เริ่มต้น Deep Learning Application ไปกับภาพวาดสไตล์ Doodle กันเถอะ !!
เอ๋ ภาพวาดสไตล์ Doodle เป็นแบบไหนกันนะ

นี่ไงภาพวาดไสตล์ Doodle เป็นภาพวาดสไตล์วาดขึ้นมาแบบง่ายๆ นั่นเองสำหรับใครที่สนใจจะไปลองวาดภาพก็สามารถเข้าไปที่โครงการของ Google ได้ตาม Link เลย
เอาล่ะขอแบ่งเนื้อหาเป็นบทๆไปดังนี้นะฮับ
- Briefly Explanation About the Application
- Data Preparation
- Intro to Deep Learning
- Landing to Code Step by Step
- Experiment
- Result
- Future Work
- References
Chapter 1 Briefly Explanation About the Application
เมื่อพูดถึง Application ที่เราจะมาทำกันในคราวนี้ อย่างที่บอกเลยเราจะมาใช้ Deep Learning เพื่อช่วยในการจำแนกภาพวาดสไตล์ Doodle ซึ่งคราวนี้ Google ได้ปล่อย Data set ให้โหดลแข่งขันกันที่ Website Kaggle หรือเข้าไปโหดล Data set กันได้ที่ Link ด้านล่างเลยครับ
สำหรับคนที่สงสัยว่า Kaggle คืออะไร
Kaggle เปรียบเสมือนแหล่งเรียนรู้ด้าน Machine Learning และ Data Science ของเหล่า Data Scientist ซึ่ง Kaggle มี Slogan ว่า Home of Data Scientist นั่นเองครับ
เหมือนกับแหล่งรวมจอมยุทธ์มาฝึกวิชา แหลกเปลี่ยนวรยุทธ์กัน
โดย Kaggle เองนั้นมี Data Set ที่จำแนกหลายหมวดหมู่ ทั้งเล่นขำๆไปจนถึงระดับแข่งขันที่มีเงินรางวัลมากกว่า 1,000,000 M $ ตาค้างงงงงงเลยถ้าชนะที !!
(แอบสงสัยเหมือนกันว่าเครื่องคอมส์บางครั้งที่ใช้ต้องราคาขนาดไหน หรือบางทีรวมกันทำระดับวิจัยในมหาวิทยาลัยก็มีให้เห็นอยู่หลายทีมด้วยกัน)

Chapter 2 Data Preparation
หลังจากที่เราทราบกันไปแล้วว่าเราจะมาทำ Image Recognition โดย Deep Learning นั่นเอง เราไปดูกันว่า Data Set ที่มีมาให้นั้นรูปร่างหน้าตาเป็นอย่างไรบ้าง !!

Data Source ของเราแบ่งเป็น 5 ส่วน โดยแต่ละส่วนเก็บในรูปแบบของ CSV นั่นเอง
- train_raw: ส่วนของภาพวาดสไตล์ Doodle ที่เป็นต้นฉบับ ส่วนนี้เค้าให้เราใช้ Train ทำ Modeling นั่นเอง (ก็มันมี Label นี่หน่าา !!!)
- train_simplified: ส่วนของภาพวาดสไตล์ Doodle ที่ย่อส่วนหรือตัดส่วนที่ไม่จำเป็นออก จึงมีขนาดเบาเหมาะแก่การนำมาศึกษาและเรียนรู้ รวมถึงทำ Model เบื้องต้นแบบง่ายๆ และเราก็สามารถนำมาใช้ Train ทำ Modeling ได้ด้วยนั่นเอง (ก็มันมี Label นี่หน่าา !!!!!!!!!)
- test_raw: อันนี้ต้นฉบับ แต่เพราะมันไม่มี Label เราเลยจะนำมา Test Model ที่เราสร้างขึ้นนั่นเอง แต่เราอาจจะไม่ได้นำมาใช้นะ
- test_simplified: อันนี้เป็น test ขนาดย่อมเยา
- sample_submission: ส่วนอันนี้เป็นตัวอย่างไฟลล์สำหรับการส่งคำตอบให้กับทาง Kaggle เค้าบอกคะแนนเรากลับมาเป็นค่า Mean Average Precision (ค่าเฉลี่ยความฉลาดของ Model เราในการแยก Noise ออกจาก Class คำตอบแต่ละตัว ซึ่งในที่นี้เรามี Class ทั้งหมดถึง 340 Classes โอว้โหวววววววววว)
ขอย้ำก่อนเริ่ม โจทย์ครั้งนี้ในการทำ Image Recognition
ซึ่งมี 340 Classes !!!!!! (Multi-classes Classification )

แต่ๆ แต่เดี๋ยวก่อน เราจะทำกันแบบ “เริ่มต้นง่ายๆกัน”
โอเคร ขั้นตอนทำแบบง่ายๆ คือ
- เราจะโหลด Training แบบ Simplified ซึ่งมีขนาดไม่ใหญ่มากนนั่นเอง เตรียมพื้นที่ไว้ประมาณ 8 Gb สำหรับ Download
- เราจะเลือกมาแค่ 10 Categoriesจาก 340 Categories ดังนั้นใช้งานจริงจะแค่ประมาณ 700 Mb
- หลังจากนั้นเราจะลองทำ Model จาก 10 Categories ที่เราเลือกออกมา
ซึ่งในที่นี้บอยด์เลือก list ตามนี้ฮับ
'The_Eiffel_Tower', 'The_Great_Wall_of_China', 'The_Mona_Lisa', 'pineapple', 'pizza', 'toothbrush', 'toothpaste', 'train', 'washing_machine', 'yoga'หลังจากเลือกเรียบร้อยแล้วเราจะจัด Folder ไว้แบบนี้นะ

- doodle-data: ใช้สำหรับใส่ไฟลล์ CSV ที่เราเลือกมาทำ Model
- model: ใช้สำหรับเก็บ Model ที่เราทำการ Check Point เดี๋ยวจะอธิบายเพิ่มเติมอีกทีว่า Check Point คืออะไรนะ !
- output-data: เพื่อไว้สำหรับใส่ data ขาออกเช่น Submission File
- transform-data: เพื่อไว้สำหรับใส่ data หลังจากการ Transform แล้ว
- weight: ใช้สำหรับเก็บ Weight ของ Model ที่เราทำการ Check Point
- doodle-recognition-01.ipynb: อันนี้ไว้ใช้ Run Code นั่นเอง
เริ่ม Start doodle-recognition-01.ipynb กัน
ทำการเรียก Keras มาลงใช้งานเป็น Backend ก่อน
จากนั้นทำการ Check ว่า GPU เราทำงานจริงๆแล้วนะ !!
Keras เป็น API ที่ช่วยให้เราเขียน Deeplearning ได้ง่ายขึ้น ตัวของมันอยู่บน Tensorflow อีกที
from keras import backend as K
K.tensorflow_backend._get_available_gpus()ต่อมาทำการ Import Pakages ที่สำคัญเข้ามาใช้งาน
อันนี้กลุ่มของ Keras
import keras as ks
from keras.callbacks import ModelCheckpoint, ReduceLROnPlateau
from keras.models import Sequential
from keras.layers.advanced_activations import LeakyReLU
from keras.layers import Activation, Dropout, Dense
from keras.layers import Conv2D, MaxPooling2D, GlobalMaxPooling2Dอันนี้กลุ่มของ Fundamental ที่ใช้กันบ่อยๆ
ตัวของ warnings.filterwarnings(‘ignore’, category=UserWarning)
ใช้เลี่ยงการแจ้งเตือนที่ไม่จำเป็นออกไป (ตัวสีชมพูๆใต้โค้ด)
plt.style.use('seaborn-whitegrid')
สำหรับ set stylesการวาดกราฟ
style_dict = {'background-color':'gainsboro',
'color':'steelblue',
'border-color': 'white',
'font-family':'Roboto'}
สำหรับแสดงผลให้ดูมีสีสันผ่าน Dataframe
%matplotlib inline
สำหรับแสดงผลกราฟบน Jupyter Notebook
import numpy as np
import pandas as pd
import matplotlib.pyplot as pltimport os
import ast
import warningswarnings.filterwarnings('ignore', category=UserWarning)
plt.style.use('seaborn-whitegrid')
style_dict = {'background-color':'gainsboro',
'color':'steelblue',
'border-color': 'white',
'font-family':'Roboto'}%matplotlib inline
อันนี้กลุ่มของ sklearn
from skimage.transform import resize
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix, classification_reportมาเช็คไฟลล์กันก่อนที่ path เราตอนนี้มีไฟลล์อะไรบ้างนะ
[‘.ipynb_checkpoints’,
‘doodle-data’,
‘doodle-recognition-01.ipynb’,
‘model’,
‘output-data’,
‘transform-data’,
‘weight’]
os.listdir()ทำการ Check Label ที่มีในไฟลล์ ว่ามี Label อะไรบ้าง ในที่นี้เราเลือกมา 10 Categoies ก็จะมี 10 Labels ด้วยกันนั่นเอง
[‘The_Eiffel_Tower’, ‘The_Great_Wall_of_China’, ‘The_Mona_Lisa’, ‘pineapple’, ‘pizza’, ‘toothbrush’, ‘toothpaste’, ‘train’, ‘washing_machine’, ‘yoga’]
files = os.listdir("doodle-data")
file_path = 'doodle-data/'
labels = [el.replace(" ", "_")[:-4] for el in files]มาลอง Check Data กันซักไฟลล์นึงก่อนว่าเป็นอย่างไรบ้างนะ !???
path_pine = 'doodle-data/pineapple.csv'
df_pine = pd.read_csv(path_pine, index_col='key_id')
df_pine.tail(3).T.style.set_properties(**style_dict)
เราจะเห็นว่ามีทั้งหมด 5 Columns ด้วยกัน (อย่าพึ่งงง นะเพราะเราทำการ Transpose ให้อ่านง่ายขึ้น และใช้ ID ของภาพ เป็น Columns แทน)
มาถึงจุดนี้ !! จะเห็นว่า Array ของเรานั้นมีความยากในการแปลงมากนัก เพราะเราต้องนำจุดต่างๆที่มีมาแบบไม่ครบนี้มาประกอบขึ้นเป็นภาพให้ได้ โดยเราจะประกอบเป็นขนาด 64 * 64 pixel นั่นเอง และในแต่ละ ID ของภาพนั้นจะเป็นขนาด 64*64*1
หรือกล่าวคือ กว้าง * ยาว * สูง ขนาด 64*64*1
หลังจากนั้นเรามา Set ค่าก่อนเริ่มทำการแปลง
I ขนาดภาพเราที่ตกลงจะปรับขนาด
S ขนาดของ Set ที่จะมี Label อยู่ข้างใน
T จำนวนของ Classes
N จำนวนของ ID ภาพในแต่ละ CSV ไฟลล์ ที่เราจะนำออกมาใช้งาน (เราคงไม่ใช้หมดเพราะเยอะมากๆ)
I = 64 # image size in pixels
S = 1 # number of the label set {1,…,10} -> {1–34,…, 307–340}
T = 10 # number of labels in one set
N = 7000 # number of images with the same label in the training setอันนี้ Code สำหรับการได้จุดต่างๆจาก เส้นที่ได้มาจาก Array
def get_line(x1, y1, x2, y2):
points = []
issteep = abs(y2-y1) > abs(x2-x1)
if issteep:
x1, y1 = y1, x1
x2, y2 = y2, x2
rev = False
if x1 > x2:
x1, x2 = x2, x1
y1, y2 = y2, y1
rev = True
deltax = x2 - x1; deltay = abs(y2 - y1)
error = int(deltax / 2)
y = y1; ystep = None
if y1 < y2:
ystep = 1
else:
ystep = -1
for x in range(x1, x2 + 1):
if issteep:
points.append((y, x))
else:
points.append((x, y))
error -= deltay
if error < 0:
y += ystep
error += deltax
if rev:
points.reverse()
return pointsจากนั้นทำการแปลง Array เราให้กลายเป็น Images หลังจากนั้นทำการ Resize เหลือ 64*64 ที่เราต้องการ
def get_image(data, k):
img = np.zeros((280, 280))
picture = ast.literal_eval(data.values[k])
for x,y in picture:
for i in range(len(x)):
img[y[i]+10][x[i]+10] = 1
if (i < len(x)-1):
x1, y1, x2, y2 = x[i], y[i], x[i+1], y[i+1]
else:
x1, y1, x2, y2 = x[i], y[i], x[0], y[0]
for xl,yl in get_line(x1, y1, x2, y2):
img[yl+10][xl+10] = 1
return resize(img, (I,I))สร้าง Function สำหรับการ plot ดูรูปภาพจาก Array ที่เราทำการ Preprocessing เสร็จ ว่าแต่ละตัวมีรูปร่างอย่างไรกันบ้างนะ
def display_drawing():
for k in range (10) :
plt.figure(figsize=(10,2))
plt.suptitle(files[(S-1)*T+k])
for i in range(5):
picture = ast.literal_eval(data[labels[(S-1)*T+k]].values[i])
for x,y in picture:
plt.subplot(1,5,i+1)
plt.plot(x, y, '-o', color='gainsboro')
plt.xticks([]); plt.yticks([])
plt.gca().invert_yaxis()
plt.axis('equal');โอเครเรามาอ่าน Data กัน โดยใช้ Pandas
data = pd.DataFrame(index=range(N), columns=labels[(S-1)*T:S*T])
Columns ทำการสร้างใหม่จาก Label และ Index สร้างจากขนาด N = 7,000 ที่เรากำหนดไว้ตั้งแต่แรกเริ่ม
จากนั้นนำ Columns Drawing มาใส่ในช่องต่างๆ
for i in range((S-1)*T,S*T):
data[labels[i]] = pd.read_csv(file_path + files[i], index_col='key_id') \
.drawing.values[:N]จะได้ดังนี้

มาลอง Plot กันดูดีกว่าว่ารูปร่างแต่ละ ID แต่ละ Cat เป็นอย่างไร !!
.
.
.
.
.
.
แท่น แท๊นนนนนน !!!!! เหมือนแท้ๆๆๆๆ

จากนั้นทำการสร้าง List ชื่อว่า Images ทำการ For loop เก็บภาพตาม Cat ต่างๆไปไว้ข้างใน
จากเดิม 7000 รูป ต่อ Cat มีขนาด 64*64
รวมใน list เดียวก็จะได้เป็น ขนาด
70000*64*64
ซึ่งกลุ่มนี้เองจะเป็น Features ให้กับเราในการสร้าง Model
images = []for label in labels[(S-1)*T:S*T]:
images.extend([get_image(data[label], i) for i in range(N)])
images = np.array(images)
และกลุ่มนี้จะเป็น Labels ในการให้ Model เรียนรู้นั่นเอง
ซึ่งมีขนาด
70000*10
targets = np.array([[] + N * [k] for k in range(T)])
targets = ks.utils.to_categorical(targets, T).reshape(N*T,T)อย่าลืม Save Data ที่ทำการ Preprocess ด้วยนะ
- เราใช้ Package ชื่อว่า h5py สำหรับ save ไฟลล์
import h5pywith h5py.File('transform-data/QuickDrawImages001-010.h5', 'w') as f:
f.create_dataset('images', data=images)
f.create_dataset('targets', data=targets)
f.close()
หลังจากนั้นเรามาต่อกันที่แปลง Features และ Labels ให้อยู่ในรูปที่สามารถนำไปทดสอบกับ Model ได้ นั่นคือการทำ Spliting Data
โดยก้อนนึงจะนำไป Training Model (ในที่นี้ใช้ 80%)
เพราะเราตั้งค่า test_size = 0.2
random_state = 1 เป็นการ Fix ว่าเราแบ่งกี่รอบก็ได้ Data ชุดเดิมแน่นอน
หลังจากแบ่ง Train 80 %
เราจะแบ่งต่ออีก Test = 10%, Validate 10% นั่นเอง
ตอนนี้ Shape ของ Data Labels เราเป็นแบบนี้แล้ว
(56000, 10), (7000, 10), (7000, 10)
ตัวหน้าคือ Rows และ ตัวหลังคือ Columns
คำตอบแต่ละแถวเป็นแบบ One-Hot-Encoding
x_train, x_test, y_train, y_test = \
train_test_split(images, targets, test_size = 0.2, random_state = 1)n = int(len(x_test)/2)
x_valid, y_valid = x_test[:n], y_test[:n]
x_test, y_test = x_test[n:], y_test[n:]del images, targetsx_train = x_train.reshape(-1,I,I,1)
x_valid = x_valid.reshape(-1,I,I,1)
x_test = x_test.reshape(-1,I,I,1)
y_train.shape, y_valid.shape, y_test.shape
โอเคร Recap ถึงตอนนี้เรามี
- Data สำหรับเตรียมพร้อมในการ Train แล้วอยู่ที่ X และ Y
- Data เราแบ่งออกเป็น Train, Test, Validation เพื่อทำการทดสอบความแม่นยำของ Model และเพื่อสังเกตุการ Overfitting
- ต่อจากนี้คือการสร้าง Model ล่ะ
Chapter 3 Intro to Deep Learning
ก่อนจะขึ้นเรื่อง Model ขอเกริ่นคร่าวๆก่อนสำหรับ Deep Learning และ Model ที่จะทำการใช้ Modeling
Model ที่จะนำมาใช้ทดสอบจะมี 2 ตัวด้วยกัน
- CNN
- VGG16
มาทำความรู้จักกับ CNN กันก่อน
CNN หรือที่เรียกกันว่า Convolutional Neural Network
เจ้า Convolution คือการทำให้บิดเบี้ยว
นั่นคือ ภาพที่เข้า Model เรานั้นจะค่อยๆบิดเบี้ยว
อันเนื่องมาจากการทำ Filtering
แล้วค่อยๆเปลี่ยนแปลงไปตาม Hidden Layer ต่างๆ
และแต่ละ Node แต่ละ Hidden Layer เองก็จะทำการจดจำลักษณะเรียงลำดับจาก Feature แบบง่ายๆ ที่ชั้นแรกๆ ไปจนถึงแบบซับซ้อนที่ชั้นลึกขึ้นๆ นั่นเอง
CNN เกิดขึ้นครั้งแรกโดย
Modern CNN ได้รับแรงบันดาลใจมาจาก Kunihiko Fukushimaในปี 1980 โดย Model เริ่มต้นเป็นการทำ ANN เพื่อทำการจดจำลายมือ ในสมัยนั้นยังเรียกเจ้า ANN ที่ทำการนำเสนอนี้ว่า Neocognitron
https://www.youtube.com/watch?v=Bh5uPyerI1M
Video สอน CNN จากท่าน Prof. Kunihiko Fukushima
(กราบสอนเข้าใจง่ายทีละ Step เห็นภาพสุดๆ)
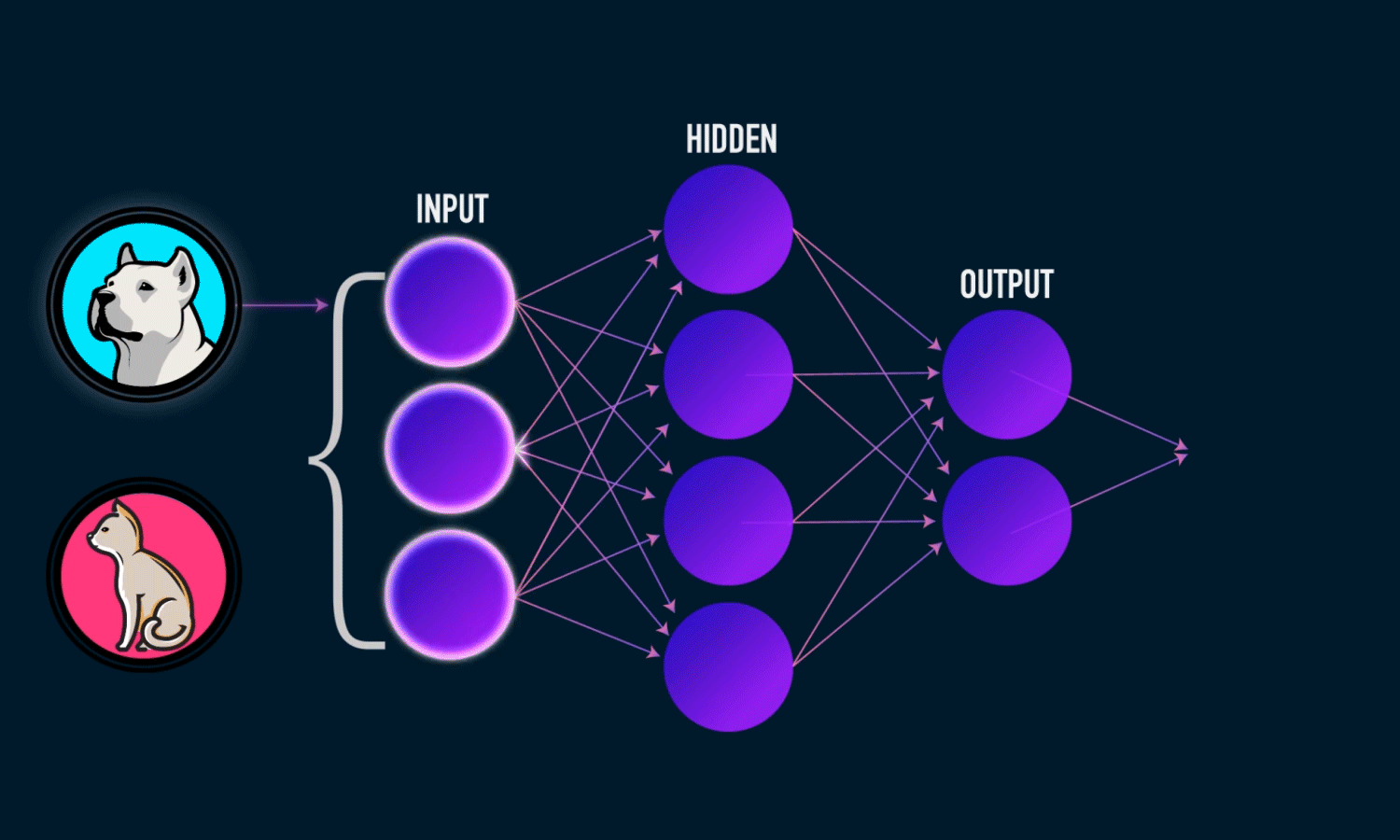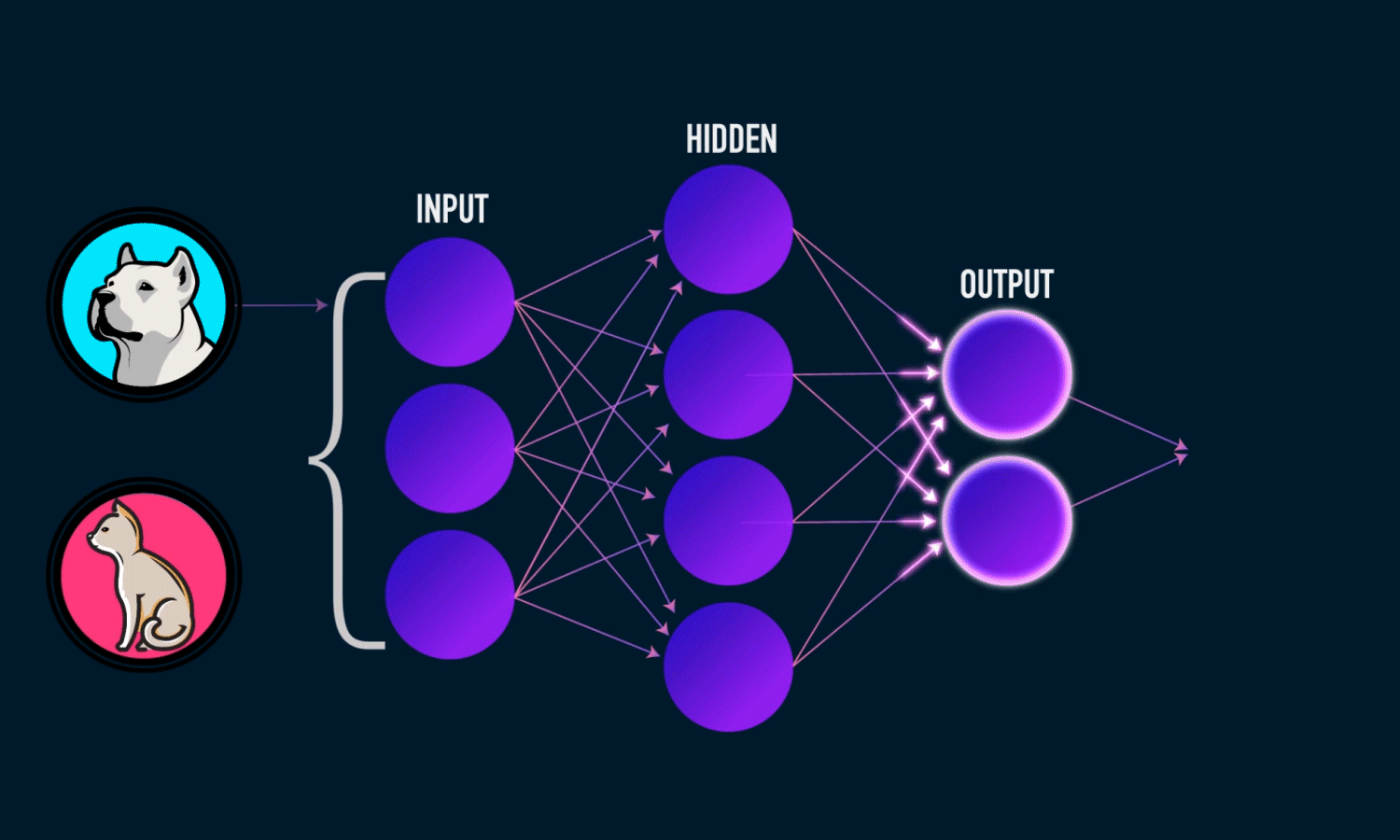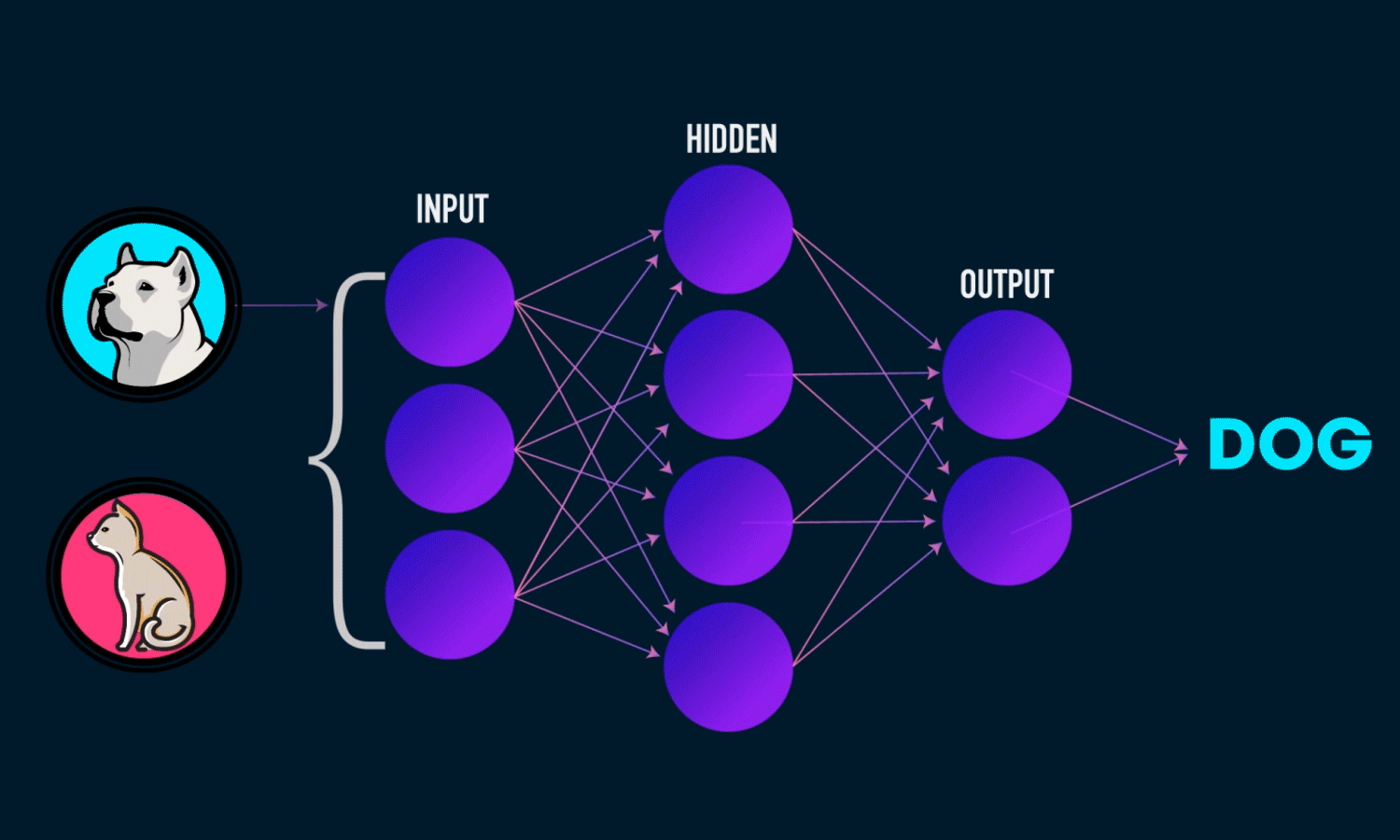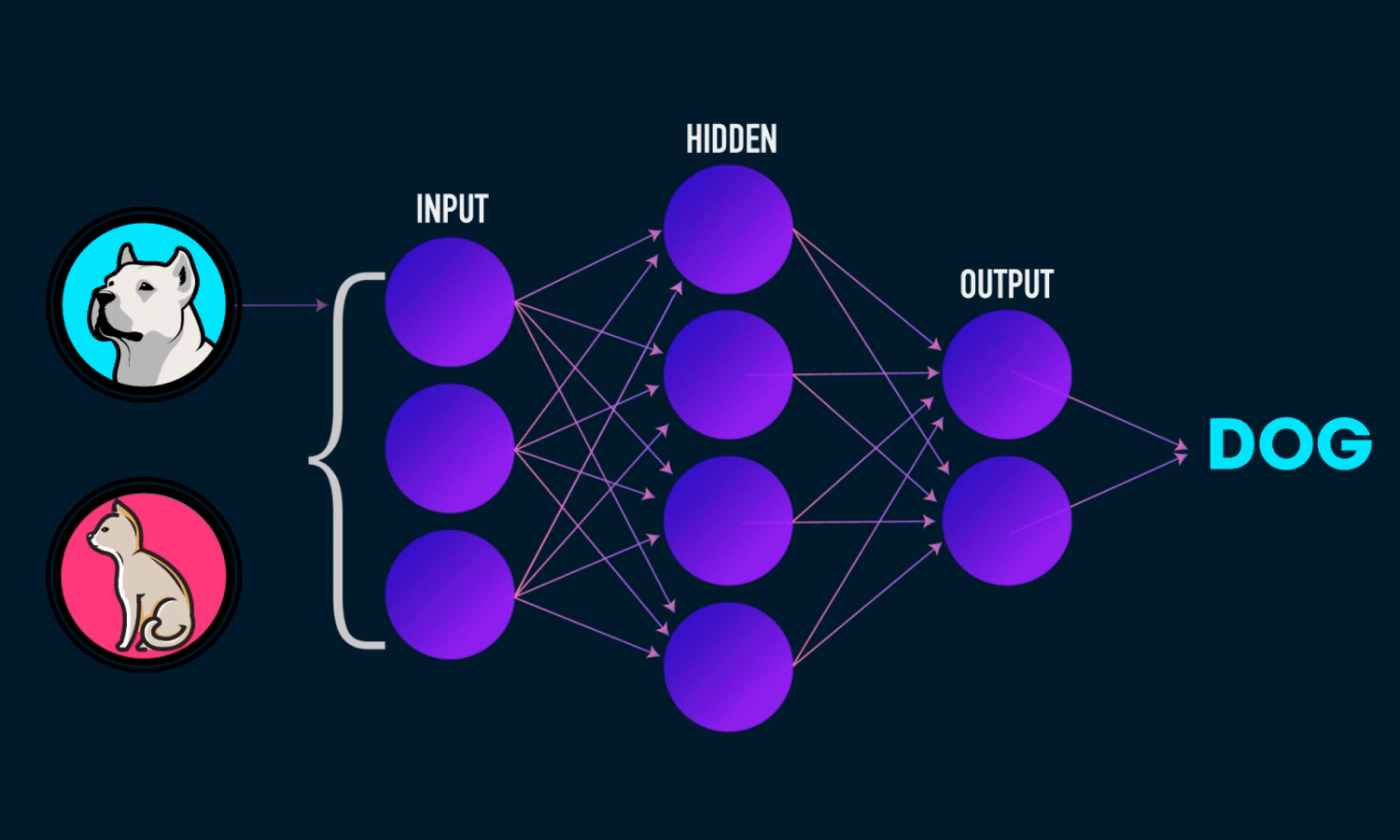
อันนี้เห็นง่ายดี แต่เป็น Neural Network นะ เพราะ Deep Learning จะต้องมี Hidden Layer ตั้งแต่ 2 ชั้นขึ้นไป
- วงกลมๆ ก็คือ Node ที่รับ Feature เข้ามาและส่งต่อไปยัง Node ถัดไป
- ชั้น Input คือชั้นที่นำ Feature เข้ามา
- Hidden Layer ในภาพนี้มีชั้นเดียวนั่นเอง เป็นชั้นที่รับค่ามาแล้วทำการคำนวณ ประมวลผล และส่งต่อค่าใหม่ที่ได้รับไปยัง Node ถัดไป
- Output ทำการรับค่า Node ก่อนหน้า และทำการประมวลผลออกมาเป็นความ่นาจะเป็นว่าจะตอบอะไรดี ซึ่งในภาพ มี 2 Classes คือหมาและแมว และที่มันตอบ Dog นั่นคือ 2 Node สุดท้ายบอกว่า ความน่าจะเป็นในการตอบหมา มากกว่า แมวนะ ดังนั้นมันจึงเชื่อมั่นว่าเป็นหมาหมา มากกว่า แมว
- ส่วน Edge หรือเส้นที่ออกจาก Node ก็จะมี Weight เพื่อบอกว่าแต่ละเส้นควรมีน้ำหนักเท่าไหร่ดี หรือมีความสำคัญเท่าไหร่ในการที่จะได้มาซึ่งคำตอบที่แม่นยำที่สุด
แล้ว CNN เป็นอย่างไรล่ะ
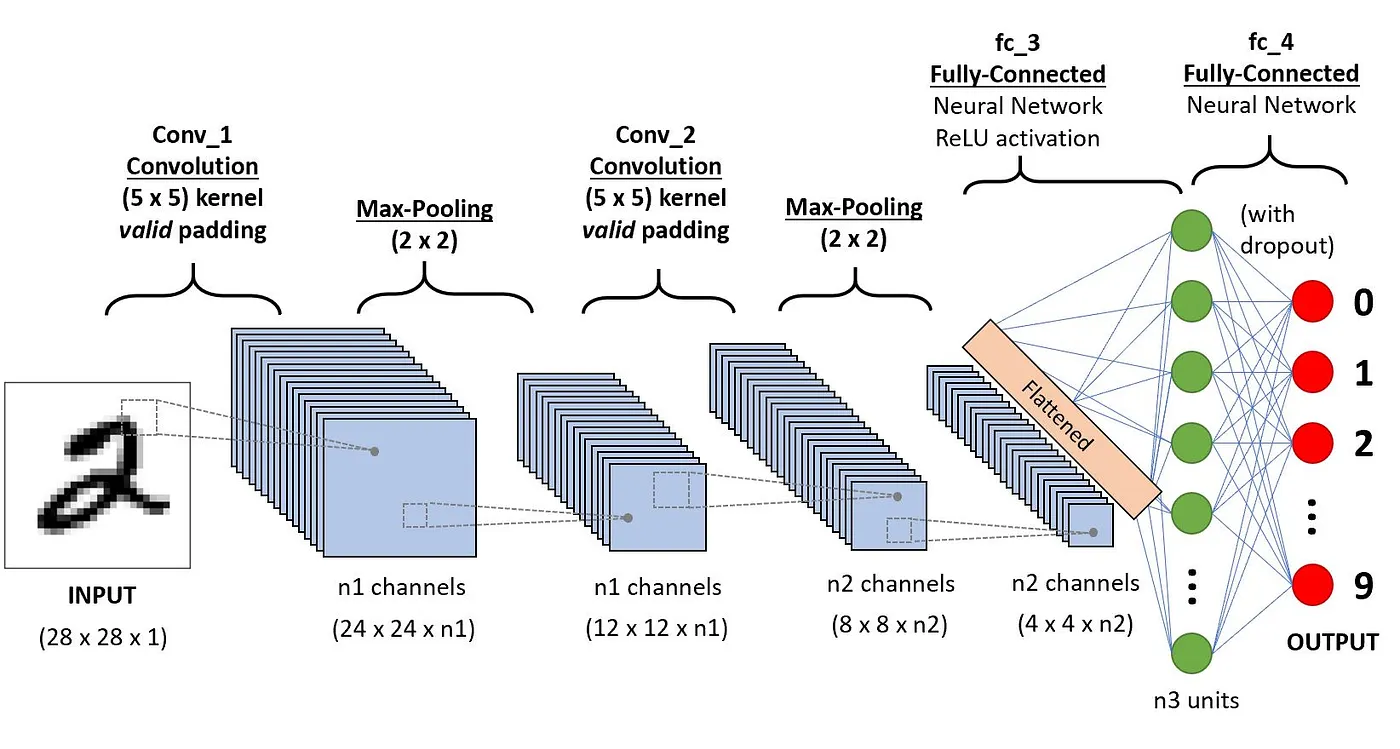
จากภาพจะเห็นว่าเรามีลำดับของชั้นต่างๆดังนี้
- Input ส่วนของการนำภาพเข้าไป
- Hidden Layer ชั้นที่ 1:
ชั้นของ Convolutional ขนาด 24*24*n
โดยที่ n คือจำนวนแผ่นของ Node ที่เราทำการกระจายออกไป
ทำการ Filter มาจากของตัวต้น (ในที่นี้ใช้ 5*5)
หรือภาพจาก Input ที่นำเข้ามาใน Hidden Layer ชั้นที่ 1
หรือเราจะพูดอีกอย่างนึงว่า 5*5 คือ Receptive Field Size - Max-Pooling:
ทำการ Max pooling ขนาด 2*2 หมายความว่า
ขนาดของแผ่นต่างๆใน Hidden Layer ชั้นที่ 1
จะถูกลดขนาดลง 2 เท่าจาก 24*24*n เหลือ 12*12*n
มันจะทำการเลือก pixel ในขนาด 2*2 คิดเหมือนตาราง Matrix
แล้วตัวไหนมีค่ามากที่สุดก็จะนำออกจาก Hidden Layer ชั้นที่ 1
ไปสู่ชั้น Hidden Layer ชั้นที่ 2
ตัวอย่างของการทำ Max Pooling (2*2)
ตัวเลขด้านล่างเปรียบเสมือน ค่าของ Pixel


- Hidden Layer ชั้นที่ 2: เป็นชั้นที่เหมือนกับชั้นที่ 1 นั่นคือผลที่เหลือจากการ Max Pooling ทำให้เหลือขนาดลดลง จาก 24*24*n เหลือ 12*12*n
- Max-Pooling: 2*2 ขั้นตอนเหมือนกับ Max-Pooling ครั้งแรก
- Hidden Layer ชั้นที่ 3: CNN 8*8*2n ขนาดของ Depth หรือจำนวนแผ่นเพิ่มขึ้นมาเป็น 2 เท่าหรือ 2n
- Max-Pooling: 2*2 ขั้นตอนเหมือนกับ Max-Pooling ครั้งแรก
- Hidden Layer ชั้นที่ 4: CNN 4*4*2n ขนาดของ Row และ Columns ลดลง 2 เท่าเนื่องจากผลของ Max-Pooling ชั้นที่ 6
- Hidden Layer ชั้นที่ 5: ทำการแปลง 3 มิติข้อมูลจาก ชั้นที่ 4 เหลือเพียง มิติเดียว
ได้จำนวน Node เท่ากับ 4*4*2n - Hidden Layer ชั้นที่ 6: ชั้นของกา่รปรับเปลี่ยนเลือกจำนวน Nodes ว่ามีเท่าไหร่ดี อาจจะเท่ากับชั้นก่อนหน้า หรือน้อยกว่า หรือมากกว่า *2 ก็ได้
ที่ชั้นนี้พิเศษหน่อยเนื่องจากมีการแทรก Drop Out เข้ามาด้วย
ช่วยทำให้แต่ละ Node ทำการหลงลืมสิ่งที่มันเคยเรียนมา
เพื่อป้องกันการ Overfiting การทำงานคล้ายๆกับสมองของมนุษย์เรา
ที่มีการหลงลืมสิ่งที่ทำการเรียนรู้มาก่อนหน้านั่นเอง - ชั้นของ Output: มีจำนวน Nodes เหลือเท่ากับจำนวน Classes ที่เราทำการให้ Model เรียนรู้
Summary จากภาพอีกที
- Input
- Hidden Layer ชั้นที่ 1: (5*5 Filter) CNN 24*24*n + Activation Function
- Max-Pooling 2*2
- Hidden Layer ชั้นที่ 2: CNN 12*12*n + Activation Function
- Max-Pooling 2*2
- Hidden Layer ชั้นที่ 3: (5*5 Filter) CNN 8*8*2n + Activation Function
- Max-Pooling 2*2
- Hidden Layer ชั้นที่ 4: CNN 4*4*2n + Activation Function
- Hidden Layer ชั้นที่ 5: Flatten
- Hidden Layer ชั้นที่ 6: Dense + Dropout
- Output + Activation Function
Activation Function คืออะไรนะ
หากเรายังจำรูป Neural Network ที่ทำการแยก หมา แมว ได้
เจ้าเส้นต่างๆที่ออกจาก Node กลมๆนัันทุกค่าที่ออกไปต้องทำการผ่าน Activation Function เสียก่อน
เช่น Node นั้นรับค่ามาคำนวณแล้วได้ 9
หาก Layer นั้นเลือก Activation Function = ‘LeakyRelu’
แสดงว่า ค่าตอนส่งไปยัง Node ถัดไปจะเท่ากับ 9
ในทางกลับกันจากสมการดังกล่าวที่ค่าน้อยกว่า 0
เช่น Node นั้นรับค่ามาคำนวณแล้วได้ -2
แสดงว่า ค่าตอนส่งไปยัง Node ถัดไปจะเท่ากับ -0.4 นั่นเอง
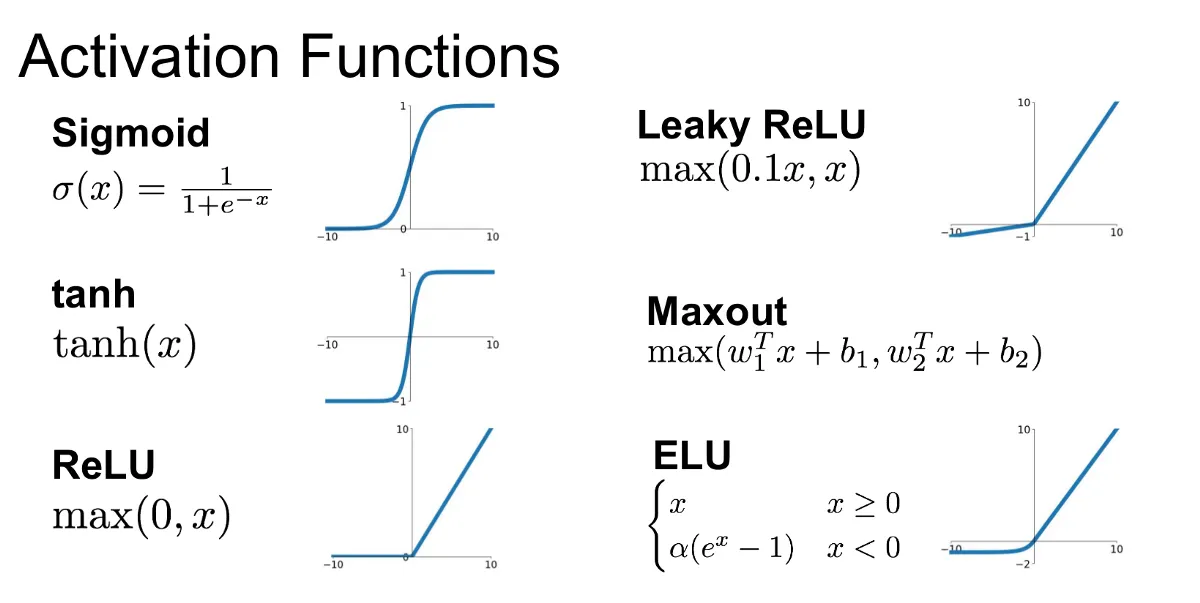
เดี๋ยวในส่วนของการ Code จะมีรายละเอียดอีกรอบ
ในส่วนที่มีการดัดแปลง Model
ทีนี้เรามาดู VGG 16 กันบ้างดีกว่า
VGG Propose ขึ้นมาโดย K. Simonyan และ A. Zisserman แห่ง มหาวิทยาลัย Oxford ผ่าน Paper ชื่อว่า
“Very Deep Convolutional Networks for Large-Scale Image Recognition”
ส่วน Architech ของ VGG 16 ลักษณะของมันก็จะประมาณนี้ เนื่องจากมี Hidden Layer 16 ชั้น จึงถูกเรียกว่า VGG 16 นั่นเอง จริงๆแล้วมี VGG 19 ด้วยนะนั่นคือ มี Hidden Layer 19 ชั้น

โดยความดังของ Model VGG16 มาจากการแข่ง ImageNet ซึ่งเป็น Dataset ที่มีข้อมูลมากกว่า 14 ล้านรูป และมีภาพถึง 1000 classes. และแน่นอน Model VGG16 สามารถติด 1 ใน 5 ความแม่นยำในชุดข้อมูล Test (92.7%)
ต่อมาเรามาทำความเข้าใจศัพท์ต่างๆใน Code กันต่อนะฮับ
Drop Out คืออะไรเอ่ย ?

ภาพด้านซ้าย: คือการเชื่อมต่อกันของ Node ต่างๆ เพื่อส่งค่าคำนวณจาก Node หนึ่งไปยังอีก Node หนึ่ง โดยทำการส่งต่อหากันทุก Node (Fully Connected)
ภาพด้านขวา: คือการ ทำการปิดบาง Node หรือเรียกว่าทำการ Drop Out ไป ซึ่งขึ้นกับการตั้งค่าว่าจะให้ลืมไปกี่เปอร์เซนต์ดี ช่วยในการแก้ปัญหา Overfitting
Optimizer คืออะไรเอ่ย ?

อธิบายง่ายๆคือ Algorithms ที่ช่วยเราค้นหา Loss ที่น้อยที่สุดนั่นเอง หรือจุดที่เราเรียกว่า Minima ซึ่งใน Keras มีให้เลือกใช้เยอะแยะหลายตัวเลย บางตัวก็ทำงานไวนะ หมายถึงค้นหาจุดที่ทำให้ Loss น้อยสุด (Global Minima) แต่อาจจะหลุดจุดนั้นได้ หรือติดอยู่กับ (Local Minima)

Learning Rate คืออะไรเอ่ย ?
ถ้าเทียบง่ายๆ ก็เหมือนอัตราความเร็วในการวิ่ง โดยที่วิ่งไปหาจุด Global Minima นั่นเอง หากเราเดินเร็วไปบางทีก็อาจจะหลุดจากจุด Global Minima ได้ หรือถ้าเราเดินช้าไป ก็เสียเวลานานกว่าจะทำการเดินถึงจุด Global Minima หรือบางทีก็อาจจะติดอยู่ที่ Local Minima ไม่ไปไหนต่อ !!
ว่าด้วยเรื่องของ Stride และ Padding

เริ่มต้นหากเรามีภาพที่มีขนาด 7*7 (กว้าง * ยาว) แล้วปรับมาเหลือ 5*5 ในที่นี้เราจะทำการตั้งค่า Receptive Field Size หรือบริเวณที่เราจะนำข้อมูลส่งต่อไปยัง ภาพด้านขวา โดยที่ภาพด้านซ้ายเราใช้ Receptive Field Size 3*3
จากสีแดงไปสีเขียว เราเลื่อน 1 ช่อง ในที่นี้เราเรียกว่าทำการ Stride 1 ช่อง และผลลัพธ์จากภาพซ้าย เราจะได้ภาพขวานั่นเอง
และแน่นอนว่าหากเราทำการ Stride= 2 ผลลัพธ์ที่ได้จะทำให้ Output ขนาดเล็กลงกว่าเดิมเหลือเพียง 3*3 ดังภาพล่าง

แล้วถ้า Stride กลายเป็น 3 ล่ะ ??? ภาพ Output คงเกิดปัญหาขึ้นแน่นอน
เราจึงเกิดวิธีที่เรียกว่า Padding ขึ้น
นั่นคือการเติมขอบรอบๆ Input เพื่อเพิ่มจำนวน Pixel ก่อนที่จะทำการ Filter แล้วเลื่อนตามจำนวน Stride ที่เราตั้ง เพื่อป้องกันปัญหา Output ไม่ได้ขนาดนั่นเอง
หรือบางทีก็ใช้ในการปรับ Input เพิ่มก่อน Filter เพื่อให้ ขนาดของ Output ตามที่เราต้องการ เช่น
Input 32*32*3 หากเราทำการ Filter ที่ขนาด 5 x 5 x 3 และ Stride = 1
Output จะเหลือเพียง 28 x 28 x 3
ดังนั้นหากเรานำ Padding มาช่วย เช่น Padding = 0 (Zero)
Input จากเดิม 32*32*3 หลังโดน Padding ปรับเป็น 36*36*3 แล้วจึงนำไปต่อที่ Filter ที่ขนาด 5 x 5 x 3 และ Stride = 1 จะได้
Output จะได้ 32*32*3 เหมือนเดิมนั่นเอง

ถึงตอนนี้น่าจะพอเข้าใจไปเบื้องต้นกันบ้างแล้วนะครับ
ต่อจากนี้ถ้าพร้อมแล้ว !!!
ไปลุยกันต่อใน Chapter 4 กันเลยโลด !!!!
Chapter 4 Landing to Code Step by Step
หลังจากเราพอเห็นภาพของ Deep Learning กันไปคร่าวๆแล้ว
เรามาดูกันต่อจาก บทที่ 4 กันต่อ
Recap อีกรอบ ถึงตอนนี้เรามี
- Data สำหรับเตรียมพร้อมในการ Train แล้วอยู่ที่ X และ Y
- Data เราแบ่งออกเป็น Train, Test, Validation เพื่อทำการทดสอบความแม่นยำของ Model และเพื่อสังเกตุการ Overfitting
ต่อจากนี้คือการสร้าง Model ล่ะ !!!!
เริ่มต้นด้วย Model แรก
เริ่มต้นที่ Hidden Layer 3 ชั้นก่อน
def model():
model = Sequential()
model.add(Conv2D(32, (5, 5), padding='same', input_shape=x_train.shape[1:]))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(Conv2D(196, (5, 5)))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(GlobalMaxPooling2D())
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.02))
model.add(Dropout(0.5))
model.add(Dense(T))
model.add(Activation('softmax'))model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
เราสามารถดูสรุป Model ที่เราสร้างได้ด้วย
model.summary()ก็จะได้หน้าตาสรุปมาให้แบบด้านล่างนี้

เราเพิ่ม Parameter อีก 2 ตัวคือ
- ModelCheckpoint():
ใช้ในการทำ Save Model ที่ดีที่สุดในทุกรอบของการ Modeling
นามสกุลก็จะเป็น .5df เฉพาะ Packages Keras เท่านั้น - ReduceLROnPlateau():
ใช้ในการลด Learning Rate (ความเร็วในการค้นหาจุดไหนคือ Global Minima)
monitor= ’val_loss’: ใช้ Criteria อะไรในการลด Learning Rate
patience= 5: ทนรอได้กี่ epoch ก่อนที่จะทำการลดค่า learning rate
verbose= 2: รูปแบบการแสดงผลหากเกิด Effect
factor= 0.5: หากไม่สามารถลด loss ได้ใน 5 epoch ทำการลด learning rate 50%
checkpointer = \
ModelCheckpoint(filepath='weight/weights.best.model.hdf5', verbose=1, save_best_only=True)
lr_reduction = \
ReduceLROnPlateau(monitor='val_loss', patience=5, verbose=2, factor=0.5)จากนั้นเรานำ Code มาประกอบกันแล้วเริ่ม Train กันเลย
- history คือตัวแปรที่จะทำการเก็บประวัติการ Train Model ของเรา
- model.fit() คือการนำ model มา train กับ data ที่เราเตรียมไว้คือ
x_train และ y_train - epochs=100: จำนวนรอบในการ Train
- batch_size=50: จำนวน data ที่ส่งไป Train ในแต่ละครั้ง จนครบจำนวนเต็ม x_train
- verbose=1: รูปแบบการแสดงผลขณะ Train
- validation_data=(x_valid, y_valid): ใส่ data ที่เราแยกไว้เพื่อดูผล Model ว่าเกิด Overfitting เริ่มที่จุดใด
- callbacks=[checkpointer, lr_reduction]: ค่า parameter ที่เรา set ไว้ตอนแรก
history = model.fit(x_train, y_train,
epochs=100, batch_size=50, verbose=1,
validation_data=(x_valid, y_valid),
callbacks=[checkpointer, lr_reduction])
หลังจากรันเรียบร้อยแล้วมาดูผลกันดีกว่า !!
# summarize history for accuracy
plt.figure(figsize=(12,6))
plt.plot(history.history['acc'])
plt.plot(history.history['val_acc'])
plt.title('model accuracy')
plt.ylabel('accuracy')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()# summarize history for loss
plt.figure(figsize=(12,6))
plt.plot(history.history['loss'])
plt.plot(history.history['val_loss'])
plt.title('model loss')
plt.ylabel('loss')
plt.xlabel('epoch')
plt.legend(['train', 'test'], loc='upper left')
plt.show()


เอ แล้วมันตีความอย่างไรหว่าาา !!
- Accuracy: เริ่มนิ่ง และไม่เพิ่มต่อที่ epoch = 60 ทั้ง train และ validation
- Loss: เริ่มนิ่ง และไม่ลดต่อที่ epoch = 60 ทั้ง train และ validation
- สำหรับ Model รูปแบบนี้ถ้าเรา Train ที่ 60 epoch พอ
- จากรูปไม่มีการตกของ Accuracy หรือการเพิ่มของ Validation คาดว่าไม่เกิด Overfitting จนเกินไป
- ต้องลองนำ Testing Data มาลองพิสูจน์กัน
ในส่วนของ Accuracy นั้นสรุปได้ว่า
ผลลัพธ์ ณ epoch ที่ 60
loss: 0.2551 - acc: 0.9126 - val_loss: 0.5907 - val_acc: 0.8206มาลองข้อมูล Test กันดูว่าจะถูกเท่าไหร่กันน้า
import itertoolspredicted = model.predict(x_test)
class_names = np.array(labels)def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
"""
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')print(cm)plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')# Compute confusion matrix
cnf_matrix = confusion_matrix(y_test.argmax(axis=1), predicted.argmax(axis=1))
np.set_printoptions(precision=2)# Plot non-normalized confusion matrix
plt.figure(figsize=(15,8))
plot_confusion_matrix(cnf_matrix, classes=class_names,
title='Confusion matrix, without normalization')

ผลลัพธ์ของ Testing ค่อนข้างใกล้เคียงกับ Validation เพราะมีปริมาณพอๆกัน
Testing Accuracy: 82.384%เรามาลองดูตัวที่ตอบผิดพลาดกันบ้างดีกว่า ว่าตอบอะไรผิด
# Convert predictions classes to one hot vectors
Y_pred_classes = np.argmax(predicted, axis = 1)
# Convert validation observations to one hot vectors
Y_true = np.argmax(y_test, axis = 1)# Errors are difference between predicted labels and true labels
errors = (Y_pred_classes - Y_true != 0)
Y_pred_classes_errors = Y_pred_classes[errors]
Y_pred_errors = predicted[errors]
Y_true_errors = Y_true[errors]
x_test_errors = x_test[errors]def display_errors(errors_index,img_errors,pred_errors, obs_errors):
""" This function shows 9 images with their predicted and real labels"""
n = 0
nrows = 3
ncols = 3
fig, ax = plt.subplots(nrows,ncols,sharex=True,sharey=True,figsize=(15,15))
for row in range(nrows):
for col in range(ncols):
error = errors_index[n]
ax[row,col].imshow((img_errors[error]).reshape((64,64)))
ax[row,col].set_title("Predicted label :{}\nTrue label :{}".format(pred_errors[error],obs_errors[error]))
n += 1# Probabilities of the wrong predicted numbers
Y_pred_errors_prob = np.max(Y_pred_errors,axis = 1)# Predicted probabilities of the true values in the error set
true_prob_errors = np.diagonal(np.take(Y_pred_errors, Y_true_errors, axis=1))# Difference between the probability of the predicted label and the true label
delta_pred_true_errors = Y_pred_errors_prob - true_prob_errors# Sorted list of the delta prob errors
sorted_dela_errors = np.argsort(delta_pred_true_errors)# Top 6 errors
most_important_errors = sorted_dela_errors[-9:]# Show the top 6 errors
display_errors(most_important_errors, x_test_errors, class_names[Y_pred_classes_errors], class_names[Y_true_errors])
อึ้งกันเลยทีเดียว !!!

โอเคร ถึงจุดนี้เพื่อนๆน่าจะนำไปทดลองเล่นเองต่อได้กับ Model อื่นๆ
เดี๋ยวต่อไปเรามาปรับปรุง Model กันต่อเพื่อเพิ่ม Accuracy กันในบทที่ 5 ครับ
Chapter 5 Experiments
หลังจากที่เราได้ทำการทดลอง Model CNN อันแรกกันไปแล้ว เราเลยตัดสินใจจะลองทำเพิ่มเติมอีก 6 การทดลองดังนี้
- Model 1: CNN 2 Layer + Flaten 1 Layer
Activation Function: LeakyRelu, Softmax
Optimizer: Adam
def model():
model = Sequential()
model.add(Conv2D(32, (5, 5), padding='same', input_shape=x_train.shape[1:]))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(Conv2D(196, (5, 5)))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(GlobalMaxPooling2D())
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.02))
model.add(Dropout(0.5))
model.add(Dense(T))
model.add(Activation('softmax'))model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
2. Model 2: CNN 2 Layer + Flaten 1 Layer +
ทดลองเพิ่มภาพที่รูปแบบ Augmentation
Activation Function: LeakyRelu, Softmax
Optimizer: Adam
def model2():
model = Sequential()
model.add(Conv2D(32, (5, 5), padding='same', input_shape=x_train.shape[1:]))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(Conv2D(196, (5, 5)))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(GlobalMaxPooling2D())
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.02))
model.add(Dropout(0.5))
model.add(Dense(T))
model.add(Activation('softmax'))model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
เพิ่มในส่วนของ ImageDataGenerator เพิ่มภาพแบบ Augmentation
datagen = ImageDataGenerator(
featurewise_center=False, # set input mean to 0 over the dataset
samplewise_center=False, # set each sample mean to 0
featurewise_std_normalization=False, # divide inputs by std of the dataset
samplewise_std_normalization=False, # divide each input by its std
zca_whitening=False, # apply ZCA whitening
rotation_range=15, # randomly rotate images in the range (degrees, 0 to 180)
zoom_range = 0.1, # Randomly zoom image
width_shift_range=0.1, # randomly shift images horizontally (fraction of total width)
height_shift_range=0.1, # randomly shift images vertically (fraction of total height)
horizontal_flip=False, # randomly flip images
vertical_flip=False) # randomly flip imagesData Augmentation คืออะไรหว่า ??
โดยปกติ หากเรามีภาพจำนวนหนึ่ง แล้วให้เครื่องเรียนรู้ มันอาจจะจำได้เฉพาะภาพที่มันเรียน ซึ่งภาพที่มันเรียนก็ไม่ได้มีการพลิกแพลงอะไรมากมายนัก และหากให้ Model เราไปเจอภาพที่ประหลาดๆ ไม่เคยเจอมาก็อาจจะทำการตอบได้ยากลำบากมากขึ้น ดังนั้นการเพิ่มภาพที่แปลกมากขึ้นก็ช่วยให้ Model เราเรียนรู้ได้ดีขึ้น
ตัวอย่างการ Augmentation

3. Model 3: CNN 2 Layer + Flaten 1 Layer +
ทดลองเพิ่มภาพที่รูปแบบ Augmentation อีกแบบหนึ่ง
Activation Function: LeakyRelu, Softmax
Optimizer: Adam
def model3():
model = Sequential()
model.add(Conv2D(32, (5, 5), padding='same', input_shape=x_train.shape[1:]))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(Conv2D(196, (5, 5)))
model.add(LeakyReLU(alpha=0.02))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.2))model.add(GlobalMaxPooling2D())
model.add(Dense(1024))
model.add(LeakyReLU(alpha=0.02))
model.add(Dropout(0.5))
model.add(Dense(T))
model.add(Activation('softmax'))model.compile(loss='categorical_crossentropy', optimizer='adam', metrics=['accuracy'])
return model
เพิ่มเติมด้วย Data Augmentation
datagen3 = ImageDataGenerator(
rotation_range=40,
width_shift_range=0.2,
height_shift_range=0.2,
shear_range=0.2,
zoom_range=0.2,
horizontal_flip=True,
vertical_flip=True,
fill_mode='nearest')4. Model 4: CNN 5 Layer + Flaten 2 Layer
Activation Function: Relu, Softmax
Optimizer: RMSProp
def model4():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',kernel_initializer='he_normal',input_shape=x_train.shape[1:]))
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',kernel_initializer='he_normal'))
model.add(MaxPool2D((2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(64, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Conv2D(64, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(T, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
5. Model 5: VGG 16
Activation Function: Relu, Softmax
Optimizer: RMSProp
def model5():
model = Sequential()
# Add the vgg convolutional base model
model.add(ZeroPadding2D((1,1),input_shape=x_train.shape[1:]))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(64, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(128, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(256, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(ZeroPadding2D((1,1)))
model.add(Convolution2D(512, 3, 3, activation='relu'))
model.add(MaxPooling2D((2,2), strides=(2,2)))model.add(Flatten())
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096, activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(T, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
6. Model 6: CNN 6 Layer + Flaten 2 Layer
Activation Function: Relu, Softmax
Optimizer: RMSProp
def model6():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',kernel_initializer='he_normal',input_shape=x_train.shape[1:]))
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',kernel_initializer='he_normal'))
model.add(MaxPool2D((2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(64, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Conv2D(64, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Conv2D(128, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Dropout(0.25))model.add(Flatten())
model.add(Dense(128, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(T, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
7. Model 7: CNN 7 Layer + Flaten 2 Layer
Activation Function: Relu, Softmax
Optimizer: RMSProp
def model7():
model = Sequential()
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',kernel_initializer='he_normal',input_shape=x_train.shape[1:]))
model.add(Conv2D(32, kernel_size=(3, 3),activation='relu',kernel_initializer='he_normal'))
model.add(MaxPool2D((2, 2)))
model.add(Dropout(0.20))
model.add(Conv2D(64, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Conv2D(64, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(128, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Conv2D(128, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(MaxPool2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
model.add(Conv2D(256, (3, 3), activation='relu',padding='same',kernel_initializer='he_normal'))
model.add(Dropout(0.25))model.add(Flatten())
model.add(Dense(256, activation='relu'))
model.add(BatchNormalization())
model.add(Dropout(0.25))
model.add(Dense(T, activation='softmax'))model.compile(loss='categorical_crossentropy', optimizer='rmsprop', metrics=['accuracy'])
return model
Chapter 6 Results
Model 1: CNN 2 Layer + Flaten 1 Layer
loss: 0.3261 — acc: 0.8885 — val_loss: 0.5877 — val_acc: 0.8137Model 2: CNN 2 Layer + Flaten 1 Layer +
ทดลองเพิ่มภาพที่รูปแบบ Augmentation
loss: 0.6248 — acc: 0.7869 — val_loss: 0.8280 — val_acc: 0.7359
ทดลองเพิ่มภาพที่รูปแบบ Augmentation

ทดลองเพิ่มภาพที่รูปแบบ Augmentation
Model 3: CNN 2 Layer + Flaten 1 Layer +
ทดลองเพิ่มภาพที่รูปแบบ Augmentation อีกแบบหนึ่ง
** เนื่องจากผลที่ได้ไม่ได้ดีกว่า Model 2 จึงไม่ได้ทำการ Plot Graph **
loss: 0.9587 — acc: 0.6662 — val_loss: 1.3119 — val_acc: 0.5993Model 4: CNN 5 Layer + Flaten 2 Layer
loss: 0.0758 — acc: 0.9749 — val_loss: 0.4081 — val_acc: 0.8790

Model 5: VGG 16 Failed
loss: 14.4916 — acc: 0.1009 — val_loss: 14.5247 — val_acc: 0.098Model 6: CNN 6 Layer + Flaten 2 Layer
loss: 0.0436 — acc: 0.9864 — val_loss: 0.5065 — val_acc: 0.9013

Model 7: CNN 7 Layer + Flaten 2 Layer
loss: 0.0429 - acc: 0.9860 - val_loss: 0.3260 - val_acc: 0.9100

จากผลการทดลอง !!
จะเห็นว่าที่ Model 7 มีค่า
- Accuracy: ทั้ง Train และ Validation ใกล้เคียงกับ Model 6
- Loss: ในส่วนของ Train นั้นใกล้เคียงกัน
แต่ในส่วนของ Validation นั้น Model 7 ดีกว่ามากเลย - การเพิ่ม CNN มาอีกชั้นช่วยลดการเกิด Overfitting ลงจาก Model 6 ได้ด้วย
- จะเห็นว่าที่ ภาพ Doodle Style มี Channel สี เพียง Channel (ขาว-ดำ) เดียวจึงไม่ได้จำเป็นต้องมีความซับซ้อนของ Model มากมายนักอย่างเช่น VGG16 ที่ต้นฉบับเหมาะกับ ภาพ มี Channel สี 3 Channel (RGB)
Chapter 7 Future Work
ถึงตอนนี้ก็พยายาม List ไว้ว่าจะทำอะไรเพิ่มเติมกันบ้างต่อดี
- ลอง Hyperparameter Tunning ในด้านของ Optimizer และ Activation Function รวมถึงค่าของ Stride และ Padding
- ลอง เพิ่มชั้นของ Hidden Layer ดู 2 แบบ
1. เพิ่มโดยที่ความลึกของ CNN เพิ่มขึ้น
2. เพิ่มโดยที่ความลึกของ CNN ลดลง - ลอง Model ที่เด่นอื่นๆเช่น Xception, Inception V3, Inception V4
- ทำ Model ซ้อน Model อีกทีหนึ่งโดยทำการแยกตัวที่ผิดบ่อยก่อนจะนำมาผ่าน Model อีก Model หนึ่ง
Chapter 8 References
- Learning Rate << Link >>
- How to build a Neural Network with Keras << Link >>
- Deep Learning แบบง่าย แทบไม่มีสมการ :) << Link >>
- Data Augmentation << Link >>
- fast.ai << Link >>
- VGG in TensorFlow << Link >>
- Very Deep Convolutional Networks << Link >>
- Why are ConvNets beating traditional computer vision? << Link >>
- A Beginner’s Guide To Understanding Convolutional Neural Networks
<< Link >>
สำหรับ Code ในการเข้าไปลองเล่นสามารถเข้าไปโหดลกันได้ที่
https://github.com/BigDataRPG/deeplearning-project
ขอบพระคุณทุกท่านที่ติดตามครับ
More Share, More Fun