When we say a technique is non-parametric , it means that it does not make any assumptions on the underlying data distribution. In other words, the model structure is determined from the data. If you think about it, it’s pretty useful, because in the “real world”, most of the data does not obey the typical theoretical assumptions made (as in linear regression models, for example). Therefore, KNN could and probably should be one of the first choices for a classification study when there is little or no prior knowledge about the distribution data. ~ Adi bronshtein

Pada suatu waktu ketika bumi masih berupa primordial soup dan Jatinangor secara etimologis masih berupa gugusan asam amino, saya bersama Reza (ahli taksonomi tumbuhan bawah laut dan nama-nama ikan) sedang asyik-asyiknya menikmati suasana alam yang sedang sepi-sepinya tersebut. Singkat cerita, kami tanpa sengaja melewati beberapa spesies tumbuhan yang unik-unik, tak ayal kami dengan segala insting ketumbuhan yang dimiliki mulai tebak-tebak berhadiah, menebak ini dan itu termasuk spesies A, B, C, dst. Masalah mulai muncul ketika terdapat satu spesies yang cirinya mirip dengan ciri-ciri spesies yang terdapat pada memory otak kami, sehingga kami tidak dapat memastikan spesies tersebut termasuk spesies yang mana dan ditambah lagi kami lupa membawa kunci determinasi (waktu itu kayaknya belum ada kunci determinasi). Akhirnya, kami berdua sama-sama bersitahan dengan segala kesoktahuan pendapat masing-masing.
Cerita imajinatif diatas sebenarnya merupakan masalah yang sering kita hadapi sehari-hari. Tidak hanya di bidang kehutanan, di bidang-bidang yang lain-pun serupa tapi tak sama. Misalkan kita diberikan suatu grup data, yang mana data tersebut sudah mempunyai label/kelas/kategori yang sudah jelas, kemudian terdapat data baru yang masuk kedalam data kita yang lama. Kemudian muncul pertanyaan, data yang baru tersebut termasuk label/kelas/kategori yang mana berdasarkan data yang sudah?.
Contoh yang lebih kekinian misalkan saja saya mempunyai data ciri-ciri famili (independent variable) dan data nama famili (dependent variable) seperti berikut (Didalam dunia Machine Learning, Independent Variables sering disebut juga sebagai Features) :

Dari contoh di atas jikalau saya menemukan spesies yang bercirikan bentuk hidup perdu, bunga panikula, dan buahnya memiliki 3 stamen, apakah spesies tersebut termasuk famili lauraceae, piperaceae, atau papaveraceae. Atau malah tidak termasuk ketiganya? Contoh lain dalam ranah kuantitatif, misal kita melakukan suatu pengukuran terhadap panjang sepal, lebar sepal, panjang petal, dan lebar petal dari spesies Iris setosa, Iris versicolor, dan Iris virginica. Kemudian kita ingin tahu ketika kita mempunyai data panjang sepal 5 cm dan lebar sepal 2,4 cm atau panjang petal 3,5 cm dan lebar petal 1,1 cm termasuk spesies Iris yang mana. Setosa, versicolor, atau virginica? atau bahkan tidak ketiganya.




Atau contoh yang lebih jelas lagi, ketika terdapat acara himpunan, mantan, teman, kabinet, dll. Nah kita ketika itu sedang gamang, antara datang atau tidak. Entah alasannya karena kemanfaatan, kebutuhan, atau penting tidaknya acara tersebut. Kemudian kita menghubungi kawan-kawan terdekat kita untuk menanyakan apakah mau datang ke acara tersebut atau tidak. Alhasil, dari 10 kawan yang kita tanya, ternyata 3 datang dan 7 orang tidak akan. Keputusan apa yang akan kita ambil? Kebayang untuk melakukan regresi-kah?
Sekilas tentang KNN (K-Nearest Neighbors)
Secara sederhana K-nearest neighbors atau knn adalah algoritma yang berfungsi untuk melakukan klasifikasi suatu data berdasarkan data pembelajaran (train data sets), yang diambil dari k tetangga terdekatnya (nearest neighbors). Dengan k merupakan banyaknya tetangga terdekat. KNN ini dapat kita temukan bilamana kita sedang belajar Machine Learning. ML intinya berkaitan dengan automasi atau bagaimana sebuah machine dapat belajar dari contoh-contoh yang kita berikan, terus memprediksi sesuatu yang sesuai dengan contoh-contoh tadi.
Lihat gambar di bawah, misalnya terdapat dua kategori yang ditunjukkan dengan Lingkaran Merah (LM) dan Kotak Hijau (KH). Kemudian kita hendak mengetahui kategori dari Bintang Biru (BB). BB dapat berupa LM atau tidak keduanya (gambar sebelah kiri). K adalah jumlah tetangga terdekat yang akan kita gunakan, asumsikan saja k = 3 (gambar sebelah kanan). Tentu dari sini kita bisa dapat segera tahu dengan membuat lingkaran yang memungkinkan BB menjadi di tengah-tengah 3 titik terdekat. Tiga titik terdekat ke BB adalah LM. Oleh karena itu, dengan sangat yakin kita dapat mengatakan bahwa BB mempunyai kelas LM. Dari sini tentu kita sadar, bahwa penentuan nilai K sangat penting pada algoritma KNN.
Dalam menentukan nilai k, sebaiknya kita gunakan nilai ganjil, karena jika tidak, ada kemungkinan kita tidak akan mendapatkan jawaban


Penentuan jarak terdekat diantara dua titik di atas dapat menggunakan dalil Pythagoras, akan tetapi bilamana terdapat lebih dari dua feature/independent variable kita dapat menggunakan euclidean distance, jaccard, cosine, manhattan, minkowski, dll. Selengkapnya dapat dilihat disini.


Kalau diterapin di SIG (Sistem Informasi Geografis) tentu bisa dong? yup tentu sangat bisa. Misal untuk menentukan lokasi dari dua titik. Lihat gambar di bawah ini untuk lebih jelasnya.

Secara garis besar dalam dunia data mining atau data science terdapat 2 pendekatan untuk melakukan teknik — teknik data mining. Supervised learning adalah sebuah pendekatan dimana sudah terdapat data yang dilatih, dan terdapat variable yang ditargetkan sehingga tujuan dari pendekatan ini adalah mengkelompokan suatu data ke data yang sudah ada, lain halnya dengan unsupervised learning, unsupervised learning tidak memiliki data latih, sehingga dari data yang ada, kita mengelompokan data tersebut menjadi 2 bagian atau 3 bagian dan seterusnya.
Sederhananya, Supervised itu artinya sudah termanage dengan baik (data yang fitur dan labelnya udah jelas). Misal jikalau terdapat ciri-ciri daun yang phyllotaxis-nya berhadapan berseling, circumscriptio berbentuk jorong, apex falii berbentuk runcing, dan nervatio menyirip itu berarti sudah jelas mengkudu (Morinda citrifolia). Sedangkan Unsupervised learning targetnya atau labelnya belum jelas. Metode yang dipakai biasanya Clustering. Jadi kita cuma ngelompokin data yang punya keterkaitan satu sama lain, tanpa tahu mereka sebenernya bener-bener satu label atau enggak. Algoritma Supervised Learning misalnya Decision tree, Nearest — Neighbor Classifier, Naive Bayes Classifier, Artificial Neural Network, dll. Algoritma Unsupervised Learning misalnya K-Means, Hierarchical Clustering, DBSCAN, dll.
Siapa bergaul dengan orang bijak menjadi bijak, tetapi siapa berteman dengan orang bebal menjadi malang. ~ Amsal, 13:20
Iris datasets
Kali ini saya menggunakan Python untuk melakukan coba-coba model. Disini saya menggunakan dataset iris. Dataset ini sangat populer digunakan untuk latihan pertama (R atau python). Iris biasanya sudah tersedia didalam modul sklearn (lengkap dengan target dan feature) atau jika kita belum install sklearn, kita bisa mengunduhnya disini.
# code untuk install modul sklearn
pip install -U scikit-learn #jika menggunakan pip yang ada di python
conda install scikit-learn #jika menggunakan anacondaTerdapat 150 observasi (row) dengan feature/independent variable sebanyak 4 (Panjang sepal, lebar sepal, panjang petal, dan lebar petal). 150 observasi tersebut dibagi menjadi 50 observasi pada masing-masing spesies (Iris setosa, Iris versicolor, dan Iris virginica). Pada data iris, kita tidak akan menjumpai nilai null (N/A), sehingga kita tidak perlu capek-capek untuk merapikan data tersebut. Selengkapnya dapat dilihat disini.

Pada gambar di bawah saya menggunakan atom dengan data iris yang sudah secara default berada pada modul sklearn. Kita tinggal memanggil data tersebut. Kemudian seperti biasa, kita definisikan variabel untuk memanggil data tersebut, dalam hal ini iris = load_iris().



Untuk gambar di bawah ini saya menggunakan jupyter notebook, dengan data iris hasil download dengan format file csv. Modul Pandas dapat mempermudah kita dalam pemanggilan dataset yang kita butuhkan, untuk lebih jelasnya dapat dibaca disini. Penilaian subjektif saya, jika membandingkan atom dan jupyter notebook, saya lebih suka menggunakan jupyter notebook, karena selain ringan dia juga dapat mengeksport code-code yang telah kita tulis menggunakan ekstensi Gist-it ke github yang kita miliki.

Hasil grafik dari kedua kode (jupyter dan atom) memang sama saja, walaupun terdapat perbedaan, karena memang struktur file-nya sudah berbeda sejak awal. Jadi jangan bingun bilamana file yang dari sklearn tidak dapat menampilkan head() karena bentuknya dataframe.
Apabila ingin menampilkan PCA (Principal Component Analysis) dapat menggunakan code di bawah:
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from sklearn import datasets
from sklearn.decomposition import PCA# import some data to play with
iris = datasets.load_iris()
X = iris.data[:, :2] # we only take the first two features.
y = iris.targetx_min, x_max = X[:, 0].min() - .5, X[:, 0].max() + .5
y_min, y_max = X[:, 1].min() - .5, X[:, 1].max() + .5plt.figure(2, figsize=(8, 6))
plt.clf()# Plot the training points
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Set1,
edgecolor='k')
plt.xlabel('Sepal length')
plt.ylabel('Sepal width')plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())# To getter a better understanding of interaction of the dimensions
# plot the first three PCA dimensions
fig = plt.figure(1, figsize=(8, 6))
ax = Axes3D(fig, elev=-150, azim=110)
X_reduced = PCA(n_components=3).fit_transform(iris.data)
ax.scatter(X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2], c=y,
cmap=plt.cm.Set1, edgecolor='k', s=40)
ax.set_title("First three PCA directions")
ax.set_xlabel("1st eigenvector")
ax.w_xaxis.set_ticklabels([])
ax.set_ylabel("2nd eigenvector")
ax.w_yaxis.set_ticklabels([])
ax.set_zlabel("3rd eigenvector")
ax.w_zaxis.set_ticklabels([])plt.show()


Kita juga dapat meggunakan plot dari seaborn, yang mana dapat memperlihatkan hubungan bivariat antar masing-masing pasangan feature yang kita miliki. Dari pairplot tersebut kita dapat melihat bahwa pada masing-masing kombinasi feature, spesies Iris setosa cenderung terpisah dari kedua spesies lainnya. Minimal dari sini kita dapat mempunyai sense terhadap data kita apabila ingin memasukkan data baru.
sns.pairplot(iris.drop("Id", axis=1), hue="Species", size=3)
# sns adalah modul seaborn, jika kita ingin memanggilnya cukup tambahkan diatasnya import seaborn as sns
# iris adalah nama data kita di dalam code
KNN dengan python
Langkah pertama adalah memanggil data iris yang akan kita gunakan untuk membuat KNN. Misal masing-masing target/spesies kita berikan nilai yang unik, setosa=0, versicolor=1, virginica=2. Pada gambar di bawah ini dapat dilihat jika kita menggunakan K=1 dan data baru a=[1,2.7,3.6,4.2]. a mewakili masing-masing nilai feature. Hasilnya adalah 2, yaitu Iris virginica.
Jika saya ganti nilai k=3 dengan nilai data a tidak saya rubah, maka hasil menjadi 1, yaitu Iris versicolor.
Untuk menghindari overfitting, kita dapat membagi iris dataset tadi menjadi data train dan test. Perbandingannya 80%:20%, sehingga bakal ada x buat training dan testing, begitu juga dengan ‘y’ bakal ada y buat training dan testing. Jadi dari 150 total observasi pada data iris, terdapat 120 observasi pada data train dan 30 observasi pada data testing. Script pemisahan data train dan test dapat dilihat di bawah.
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20)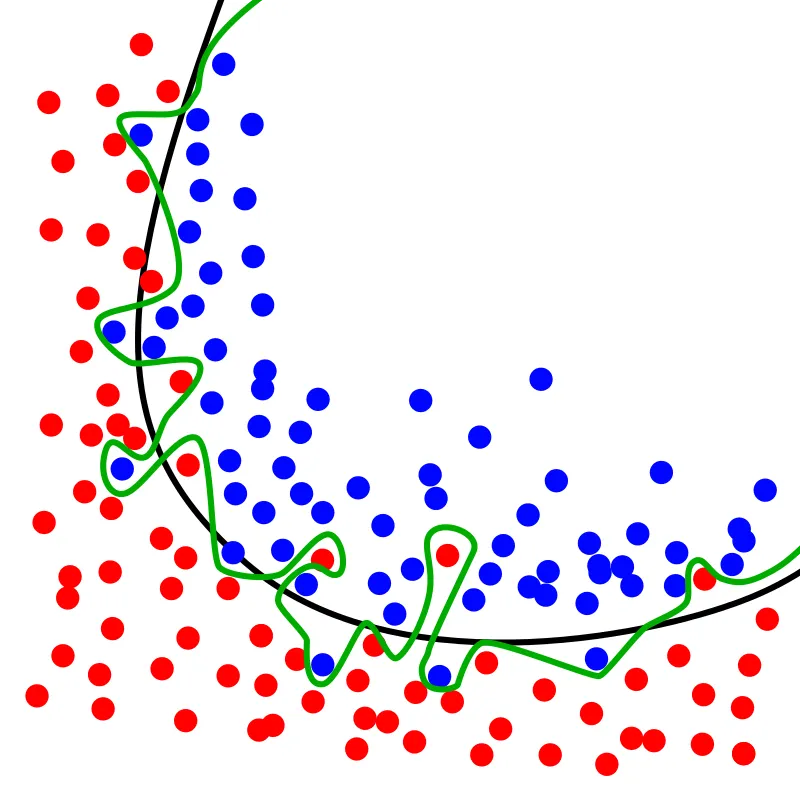
Cross-validation
Cross-validation (CV) adalah metode statistik yang dapat digunakan untuk mengevaluasi kinerja model atau algoritma dimana data dipisahkan menjadi dua subset yaitu data proses pembelajaran dan data validasi / evaluasi. Model atau algoritma dilatih oleh subset pembelajaran dan divalidasi oleh subset validasi. Selanjutnya pemilihan jenis CV dapat didasarkan pada ukuran dataset. Biasanya CV K-fold digunakan karena dapat mengurangi waktu komputasi dengan tetap menjaga keakuratan estimasi.

Misal nih, data kita ada 150. Ibarat kita pake K=5, berarti kita bagi 150 data menjadi 5 partisi, isinya masing-masing 30 data. Jangan lupa, kita perlu menentukan mana yang training data dan mana yang test data. Karena perbandingannya 80:20, berarti 120 data adalah training data dan 30 sisanya adalah test data. Berdasarkan 5 partisi tadi, berarti bakal ada 4 partisi x 30 data = 120 training data. Dan sisanya ada 1 partisi test data berisi 30 data. Kemudian, experimen menggunakan data yang udah di partisi-partisi bakal diulang 5 kali (K=5). Tapi posisi partisi Test data berbeda ditiap iterasinya. Misal di iterasi pertama Test nya di posisi partisi awal, terus iterasi partisi kedua Test-nya di posisi kedua, dan seterusnya, pokonya gaboleh sama.
Hasil running code diatas menunjukkan bahwa algoritma KNN yang telah kita lakukan dapat mengklasifikasikan semua observasi (30) dalam set test dengan akurasi 97%, yang artinya susdah sangat bagus. Meskipun algoritma KNN dilakukan sangat baik dengan dataset ini, jangan berharap hasil yang sama dengan semua dataset. KNN tidak selalu berkinerja baik dengan data yang memiliki dimensi tinggi atau yang memiliki feature yang sangat kategoris.
Menentukan nilai K
Nah sekarang kita akan mencari tahu nilai K berapa yang akan menghasilkan akurasi tinggi. Karena kita tahu sendiri pada algoritma KNN, penentuan nilai K sangatlah krusial. Kita akan melihat nilai K dari 1–40. Berikut code yang dapat kita gunakan:

Dari hasil di atas kita dapat melihat bahwa yang memiliki nilai error rata-rata 0 adalah ketika nilai K sebesar 4, 6–24. Hasil ini dapat dijadikan pedoman ketika kita ingin menggunakan nilai K yang memiliki akurasi tinggi. Dari situ kita dapat meminimalisir kesalahan prediksi.
Selanjutnya?
Kita dapat menampilkan plot hasil klasifikasi data iris. Kemudian kita dapat melihat perubahan yang terjadi ketika nilai K berbeda. Langkah ini sangat membantu jika kita tidak dapat membayangkan bagaimana data tersebut bekerja.
Kita juga dapat membuat code ketika menjadi dinamis, sehingga memungkinkan adanya interaksi ketika kita memasukkan data. Hanya dengan menambahkan beberapa perintah logika kita dapat melakukan hal tersebut.
import numpy as np
from sklearn import neighbors, datasets
from sklearn import preprocessing
n_neighbors = 6
# import some data to play with
iris = datasets.load_iris()
# prepare data
X = iris.data[:, :2]
y = iris.target
h = .02
# we create an instance of Neighbours Classifier and fit the data.
clf = neighbors.KNeighborsClassifier(n_neighbors, weights='distance')
clf.fit(X, y)
# make prediction
sl = input('Enter sepal length (cm): ')
sw = input('Enter sepal width (cm): ')
dataClass = clf.predict([[sl,sw]])
print('Prediction: '),
if dataClass == 0:
print('Iris Setosa')
elif dataClass == 1:
print('Iris Versicolour')
else:
print('Iris Virginica')
Sekian yang dapat ditorehkan, kurang lebihnya maap-maap aje…