The Economist as a Software Engineer
What best practices we can learn from software engineers?
Whenever my kids ask me what I do, I tell them I am trying to figure out how the world works.
They don’t believe me. They see me sit in front on my computer, writing and debugging code, reviewing scores of numbers and figures. I may be in conversation with my computer, but surely not with the world.
Most economists, whether econometricians, applied microeconomists, or macroeconomists, use their computer in increasingly sophisticated ways. They simulate the small-sample properties of a new estimator. They try several causal analysis techniques on large data sets, some of them non-parametric and computationally intensive. And they use sophisticated algorithms to find fixed points of their model where expectations and agents’ behavior are all aligned.
This increased reliance on a machine that converts numbers to other numbers still occupies a strange position in the collective ethos of academic economists. We have an uneasy relationship with this work. It is not us. It is what others do. We try to offload as much to others as possible. To research assistants. Who will often not become coauthors. After all, they “only wrote the code.”
I am calling for more openness and more humility from economists. When we are sitting in front of a computer, scratching our heads, we are not alone. There is an entire profession dedicated to solving problems with computers.
What can we adopt from software engineers when we are working on our next research project? Below are my top three recommended best practices.
1. Use scripts for every step of your research
Research is an iterative process. We try things that don’t work. We add variables to a regression. We remove them. We change the color and the scale of a chart until it communicates what we want to say.
It would be tempting to point and click on our computer enough times until the desired result appears. But then what? At some point we have to communicate to the scientific community (our professors, journal editors, our readers) how we found what we found.
You may have the perfect memory and can recall where you clicked when. You can narrate this in beautiful prose and hope that your professors, your editors and your readers will understand what you did.
It is much better, however, to rely on machine readable instructions. Write down precisely what you want to do. Let the computer do exactly that. And let your professors, editors, and readers read exactly what you did.
“Our measure of country development is the decadal average of log GDP per capita” has the same meaning as
egen mean_loggdp_decade = mean(log(GDP_per_capita)), by(country decade)
The former can be only be read by humans, the latter can be read by humans and machines alike. Moreover, the latter formulation is more precise. What exact variable did you use to measure GDP per capita? How did you deal with missing values? Science needs to precise and computers have a way of enforcing that.
In other words, you should write software.
2. Make code easy to change
I often hear the following excuse for not writing good code: “I will only run this code once or twice. It is not worth spending more time to improve my code.”
The right metric, however, is not how many times you run your code. The computer couldn’t care less if the code is ugly. You could run the same ugly code 100 times, and it would happily return the same result.
But then, why would you run the same code a 100 times if you already know the result? The point is, you will run almost the same code a 100 times. You will change things. Fix a bug. Increase a parameter. Choose a different estimation method. Use a different dataset.
Write code that is easy to change.
Uncle Bob Martin (an early evangelist of clean code) went so far to say

Ok, but how do I write code that is easy to change? By splitting your work into small chunks and organizing them in a logical way.
Suppose the referee told me to cluster my standard errors by receiving country, not by sending country.
If I didn’t write down my analysis steps in code, I am doomed.
If I did write single very long script, I am a little bit better off. I can search for “receiving country” among the thousands of lines of code. (As the Data Editor for the Review of Economic Studies, I have seen hundreds of complex research projects. In my experience, they rarely stop below a couple thousand lines.) I can replace the variables with “sending country”, hoping that nothing breaks in the process.
If I already split my code into manageable chunks, such a change takes five minutes. There is a regression.do, separate from data cleaning and chart plotting codes, and I can find the appropriate clustering options more easily there.
3. Use version control
We’ve all been there. The file regressions7.do becomes regressions8.do, then regressions_final_miklos.do, then regressions_final_miklos2.do. We are afraid to delete old versions of our files, because we fear that we are losing something very important. We save these versions with more and more obscure names.
Why are we torturing our coauthors and ourselves? Software engineers have solved the problem of keeping track of old versions of files decades ago. The solution is called git. It is a tool to save snapshots of a folder with a short, helpful message. In a folder that uses git, I can immediately see who changed which file when, and what message they shared about the change.
If you don’t use git yet, learn it now. We are also teaching it to our students at CEU.
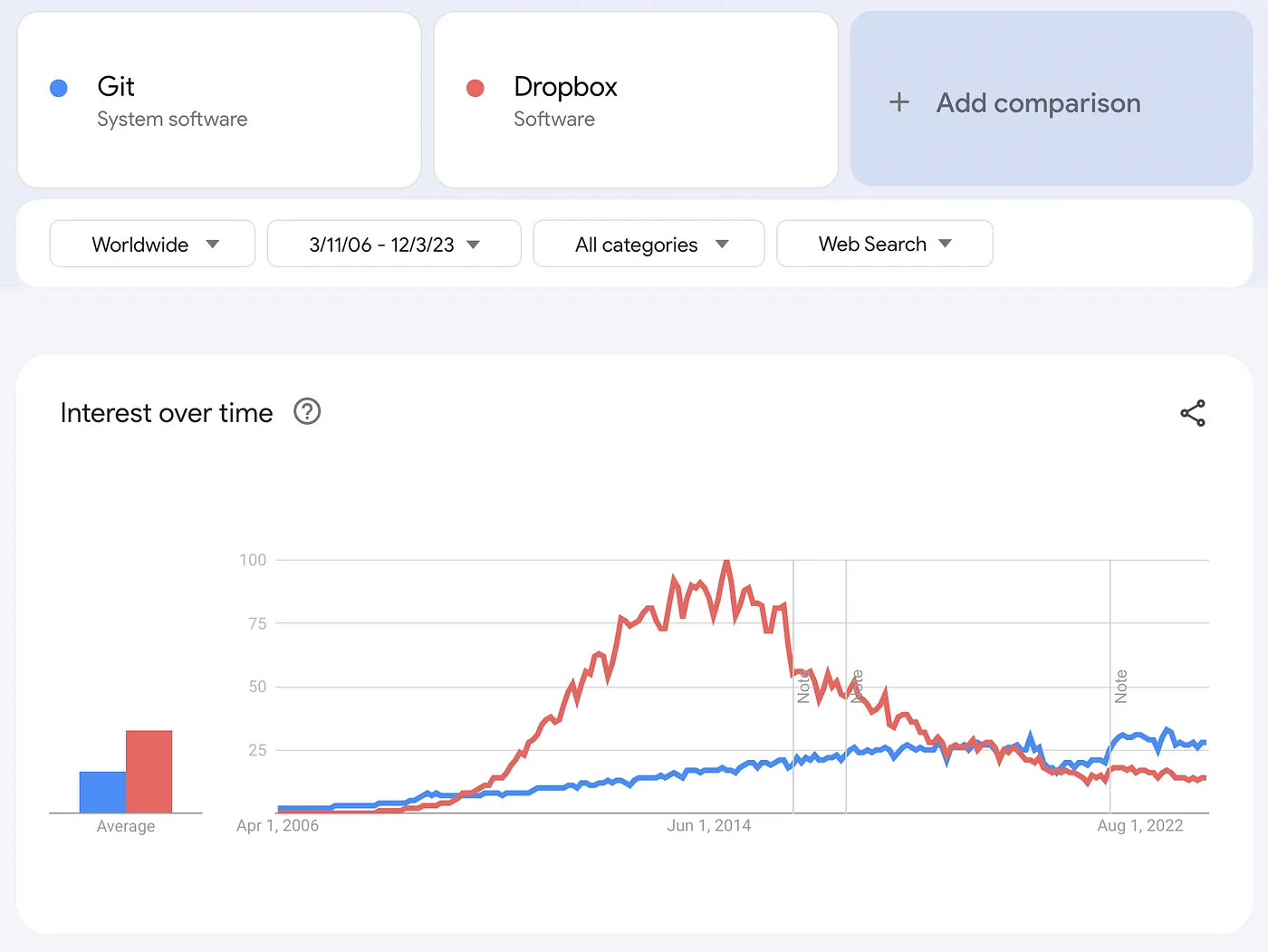
There used to be several source code control tools; git has won. Interest and usage of git has steadily increased since its invention in 2005. It now surpasses that of Dropbox.
These are just the top three things we can reuse from our software engineer friends.
For a deeper dive, I strongly recommend The Pragmatic Programmer, an excellent overview of the practices of software engineering.
A gentler introduction into these best practices is provided by Kieran Healy in The Plain Person’s Guide to Plain Text Social Science.
