隨著深度學習的發展,自然語言處理 (Natural Language Processing,NLP) 技術越趨成熟,近年來在情感分析、機器翻譯、語音辨識、對話機器人等任務上均有很不錯的結果。
自然語言處理是指讓電腦能夠分析、理解人類語言的一項技術,而人類語言具有前後順序、上下文關係,對於這種時間序列的資料很常使用循環神經網路 (Recurrent Neural Network,RNN)。但由於 RNN 難以進行平行運算,因此 Google 提出了一種不使用 RNN、CNN,僅使用自注意力機制 (self-attention mechanism) 的網路架構 — Transformer。
本文將要介紹 Attention Is All You Need 論文,發表於 NIPS 2017。其網路架構是基於 Seq2Seq + self-attention mechanism。在開始閱讀之前,建議先了解 RNN、Seq2Seq 及注意力機制 (attention mechanism),本文僅大略地介紹。
📝 Paper: https://arxiv.org/abs/1706.03762
Seq2Seq
Seq2Seq主要由兩篇論文提出:Sequence to Sequence Learning with Neural Networks、Learning Phrase Representations using RNN Encoder–Decoder for Statistical Machine Translation,兩者概念相同,差別在於使用不同的 RNN 模型。前者使用 LSTM,而後者使用 GRU。
其架構為 Encoder-Decoder,如下圖所示,Encoder 會先將輸入句子進行編碼,得到的狀態會傳給 Decoder 解碼生成目標句子。

Attention Mechanism
但是當訊息太長時,seq2seq 容易丟失訊息,因此引入了注意力機制 (Attention Mechanism)。其概念為將 Encoder 所有資訊都傳給 Decoder,讓 Decoder 決定把注意力放在哪些資訊上。有兩篇經典的代表論文:Neural Machine Translation by Jointly Learning to Align and Translate、Effective Approaches to Attention-based Neural Machine Translation

Transformer
經過上述的介紹後,開始進入主題吧~~ 首先來看一下 Transformer 的網路架構,由 Encoder-Decoder 堆疊而成,其中 N 為堆疊的層數,預設值為 6。接著看 Encoder-Decoder 裡面的結構,有 Multi-head Attention、Add&Norm、Feed Forward、Masked Multi-head Attention,接下來會一一說明這些結構。

Encoder
Positional Encoding
先來看左邊的 Encoder 部分,input 先經過 embedding 層轉換為一個向量,然後在進入 layer 前會先與 Positional Encoding 相加 (Input Embedding 跟 Positional Encoding 的維度相等),這個 Positional Encoding 就是詞語的位置編碼,目的是為了讓模型考慮詞語之間的順序。

論文使用 sin, cos 函數進行位置編碼,公式如下,其中 pos 為詞語在序列中的位置、2i, 2i+1 為該詞語在 Positional Encoding 維度上的 index、d_model 為 Positional Encoding 的維度 (與 Input Embedding 維度相等),預設值為 512。

這樣講可能覺得有點難以理解,來舉個例子,假設要計算序列中的第二個詞語,此時 pos=1,則 Positional Encoding (PE) 為以下樣子

❓ 為什麼要使用 sin, cos 函數進行編碼?
因為 sin, cos 函數可以表示為兩個向量間的線性關係,能夠呈現不同詞語之間的相對位置,並且不受限序列長度的限制,比較不會有重複的問題。

此外,sin, cos 函數有上下界 (落於 [0, 1] 之間)、穩定循環的性質。

❓ 為什麼是與 Positional Encoding 相加,而不是 concat ?
因為其實做相加得到的結果與 concat 是相同的。假設有一輸入序列 xi,其位置使用簡單的 one-hot encoding 表示為 pi=(0, …, 1, 0),W_x, W_p 為其相對應的權重。
將 W_x, W_p 合併為 W,xi, pi 合併為 X,而 W 與 X 的 Inner Product 可經由線性代數的性質,拆分為 W_x 跟 xi 的 Inner Product + W_p 跟 pi 的 Inner Product。因此可以得知 Input Embedding 與 Positional Encoding 相加所得到的結果跟兩者 concat 是一樣的。

Multi-head Attention
Input Embedding 與 Positional Encoding 相加後會進入到 layer 裡,Encoder 有兩個子層 Multi-head Attention、Feed Forward。在介紹 Multi-head Attention 之前,先來說明自注意機制 (self-attention mechanism)

- self-attention mechanism
自注意力機制有三個重要的參數 q, k, v,而這些參數是由 input xi 經過 embedding 層轉換為 ai,接著 ai 進入到 self-attention layer 會乘上三個不同的 matrix 所得到的。
q (query): 是指當前的詞向量,用於對每個 key 做匹配程度的打分
k (key): 是指序列中的所有詞向量
v (value): 是指實際的序列內容
由下圖可以看到 q1 會對每一個 k 做 Inner Product 得到 q, k 之間匹配的相似程度 α1, 1、α1, 2、…,然後做一系列的運算得到輸出,這些計算步驟稱為 Scaled Dot-Product Attention

- Scaled Dot-Product Attention
接著來看數學式子會更了解,由下列公式得知 q, k 會先做 Inner Product,得到的值是匹配的相似程度,除以 sqrt(dk) 後,再做 softmax 計算出 v 的權重,最後將該權重與 v 做加權運算,其中 q, k 維度都為 dk,v 維度為 dv。
看到這裡可能會疑惑為什麼要除以 sqrt(dk)? 之所以這樣做的原因是為了避免當 dk (q, k 的維度) 太大時,q, k Inner Product 的值過大,softmax 計算的值落入飽和區而導致梯度不穩定。


- Multi-Head Attention
終於要來介紹 Multi-Head Attention 啦~ 其運算方式與 self-attention mechanism 相同,差異在於會先將 q, k, v 拆分成多個低維度的向量,由下圖可看到若假設 head=2,qi 會拆分成 qi,1、qi,2,接著繼續跟上述一樣的步驟,最後再把這些 head 輸出 concat 起來做一次線性計算。
這樣的好處是能夠讓各個 head (q, k, v) 關注不同的資訊,有些關注 local、有些關注 global 資訊等。

由下圖可看到 q, k, v 會做 h 次的線性映射到低維度的向量,再進行 Scaled Dot-Product Attention,最後將其 concat、linear 得到輸出。

以下是 Multi-Head 公式,其中 h=8、dk=dv=d_model/h

Add & Norm
經過 Multi-head Attention 後會進入 Add & Norm 層,這一層是指 residual connection 及 layer normalization。前一層的輸出 Sublayer 會與原輸入 x 相加 (residual connection),以減緩梯度消失的問題,然後再做 layer normalization。


📚 Layer Normalization vs Batch Normalization
在之前的文章有介紹過 Batch Normalization (BN),其作法是在每一個 mini-batch 的 input feature 做 normalize,這樣的方式雖然在 CNN 上獲得了很好的效果,但仍然存在一些缺點:
- 過於依賴 batch size,如果 batch size 太小,BN 的效果會明顯下降。
- 不太適用於時間序列,因為文本序列的長度通常不一致,強制對每個文本執行 BN 不大合理。
因此在 RNN 中較常使用 Layer Normalization (LN),概念與 BN 類似,差別在於 LN 是對每一個樣本進行 normalize。由下圖可以很清楚的看出兩者的差異,其中每一行是指樣本,每一列是樣本特徵。

Position-wise Feed-Forward Networks (Feed Forward)
接著進入到 FFN 層,由下列公式可以看到輸入 x 先做線性運算後,送入 ReLU,再做一次線性運算。其中輸入輸出的維度 d_model=512,而中間層的維度 dff = 2048

Decoder
看到這裡已經理解 Encoder 的運算過程了,再來看右邊 Decoder 的部分吧!
Decoder 與 Encoder 一樣會先跟 Positional Encoding 相加再進入 layer,不同的是 Decoder 有三個子層 Masked Multi-head Attention、Multi-head Attention、Feed Forward。此外,中間層 Multi-head Attention 的輸入 q 來自於本身前一層的輸出,而 k, v 則是來自於 Encoder 的輸出。
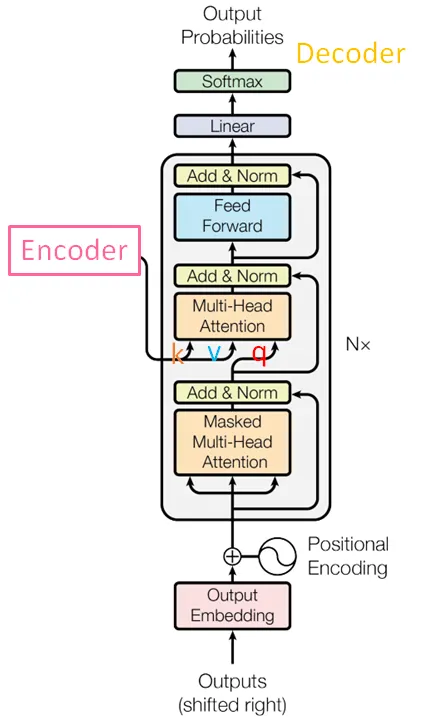
Masked Multi-head Attention
由於其他兩層跟 Encoder 大致相同,所以就跳過來介紹 Decoder 中才有的 Masked Multi-head Attention。
Transformer 的 Mask 機制有兩種:Padding Mask、Sequence Mask
- Padding Mask 在 Encoder和 Decoder 中都有使用到,目的是為了限制每個輸入的長度要相同,對於較短的句子會將不足的部分補 0
- Sequence Mask 只用於 Decoder,目的是為了防止模型看到未來的資訊,因此在超過當前時刻 t 的輸出會加上一個 mask,確保模型的預測只依賴小於當前時刻的輸出。
Sequence Mask 的做法是通過一個上三角矩陣來實現,將這些區域的值都設定為負無窮,如此一來這些元素經過 softmax 後都會變為 0 以達到 mask 的效果。

Conclusion
來看一下 Transformer 的運算過程會更清楚的了解。Encoder-Decoder 層數為 3,首先 Encoder 會利用注意力機制關注彼此,接著在 Decoder 中除了關注本身前幾層的輸出外,還會關注 Encoder 的輸出。
Transformer 以全部基於 attention 的方式達到了 Attention Is All You Need,這樣的架構有利於平行運算,比起 RNN、CNN 能夠得到更好的表現結果,同時還提升了訓練速度,對於之後的 NLP、 CV 領域有很大的影響。

最後附上我認為滿好的教材:
