Maintaining Iceberg Tables
หากใครได้ลองอ่านบทความ Journey of TILDI Data Engineer in 2023 ก็อาจพอทราบว่าทีมเราได้เพิ่ม “Apache Iceberg” เป็นตัวเลือกใหม่ในการใช้งาน Data Lakehouse ในบทความนี้จะกล่าวถึงแนวทางการ maintain Iceberg tables รวมไปถึงการ maintenance เพื่อให้คงประสิทธิภาพสูงสุดเอาไว้

Table of Content
- Why We need to Maintenance Iceberg Tables
- Understanding Iceberg Table Structure
- Maintenance Iceberg Tables
- Conclusion
Why We need to Maintenance Iceberg Tables
Small Files Problem เป็นหนึ่งในปัญหาที่อาจพบได้ใน Iceberg table จากการที่เรา ingest data เข้า table บ่อยๆ โดยเฉพาะกับ near real-time pipeline ซึ่งขนาดของข้อมูลที่เข้ามาอาจไม่อยู่ในขนาดที่เหมาะสม เป็นไฟล์เล็กๆจำนวนมาก และนอกจาก data files ที่เยอะแล้ว จำนวนของเหล่า metadata files ก็เพิ่มตามเช่นกัน ได้แก่ snapshots, metadata files, manifest files
ปัญหานี้ส่งผลโดยตรงต่อประสิทธิภาพในการทำงานของ operations ต่างๆ ตามจำนวนไฟล์เล็กๆที่มากขึ้น เช่น ไฟล์เล็กๆจำนวนมากจะต้องใช้เวลาในการ query มากขึ้น หรือหากใช้งาน Spark ก็จะพบว่าใช้เวลานานขึ้น เนื่องจากต้องทำงานกับไฟล์เล็กๆจำนวนมากนั้นเอง
จากปัญหาเรื่องของ small files และจำนวนของ metadata files ทำให้เราต้องมา maintenance Iceberg tables เพื่อให้ใช้งานได้อย่างมีประสิทธิภาพสูงสุด และไม่เปลือง cost ในการเก็บ files ต่างๆที่ไม่จำเป็น
Understanding Iceberg Tables
ก่อนเราจะไป maintenance Iceberg table ของเราได้ เราจำเป็นต้องเข้าใจโครงสร้างการเก็บไฟล์ต่างๆของ Iceberg เพื่อความเข้าใจในการใช้งาน maintenance operations ต่างๆให้เหมาะสมกับแต่ละ table
การเก็บไฟล์ของ Iceberg แบ่งออกเป็น 2 layers ได้แก่ data และ metadata
ภายใน data layer จะเป็นที่เก็บไฟล์ข้อมูลต่างๆของเรา และ metadata layer จะประกอบไปด้วย snapshots, metadata files, และ manifest files
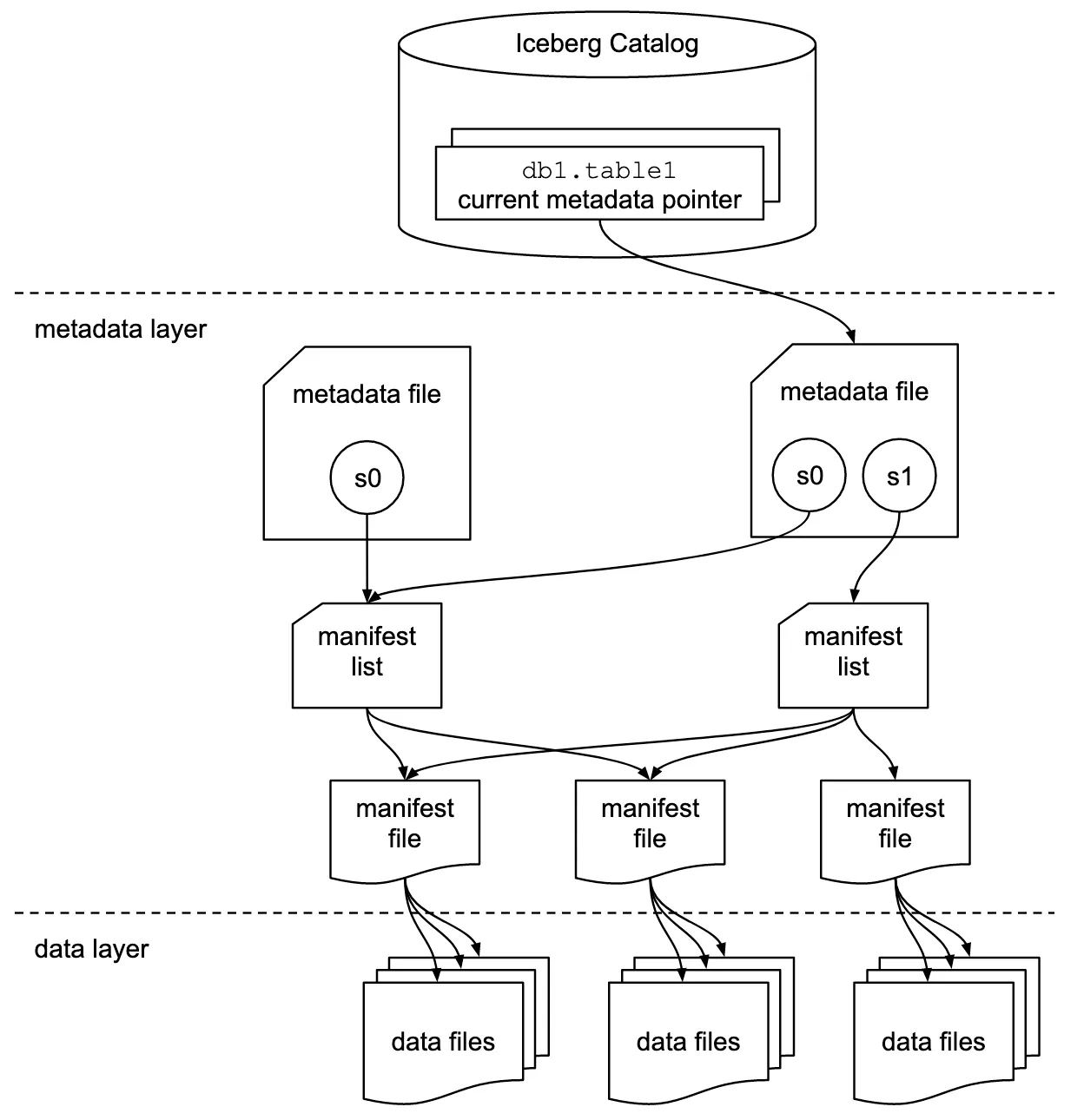
จากภาพข้างต้นแสดงให้เห็นถึงโครงสร้างการเก็บข้อมูลของ Iceberg table หนึ่งๆ เราลองมาเจาะดูแต่ละส่วนกัน
Metadata Layer
- metadata files: เก็บข้อมูล snapshots, manifest list
- snapshot: state ของ table ณ เวลาหนึ่งๆ โดยมีข้อมูลเกี่ยวกับ table ของเรา
- manifest list: เก็บ list ของ manifest files โดย 1 manifest list ต่อ 1 snapshot
- manifest files: เก็บ list ของ data files หรือ delete files ทั้งหมด
Data Layer
- data files: ไฟล์ที่เก็บข้อมูลของเรา โดยเก็บเป็น rows
- delete files: คล้ายๆ data files แต่เก็บข้อมูลของ rows ที่ถูกลบออก
น่าจะพอเห็นภาพมากขึ้นนะครับ ในหัวข้อถัดไปจะเริ่มมาจัดการไฟล์เหล่านี้กัน
Maintenance Iceberg Tables
ทาง Iceberg เองก็มีคำแนะนำให้เรา maintenance เป็นระยะๆ โดย maintenance operations ที่เราจะทำกัน ได้แก่ compact data files, expire snapshots, remove old metadata files, และ remove orphan files
Iceberg มี API ให้เราสามารถทำ operations เหล่านี้ได้ผ่าน Spark โดยเขียนผ่าน Java หรือ SparkSQL ก็ได้ ในบทความนี้ผมใช้งานผ่าน SparkSQL ซึ่งการทำ maintenance operations จะทำโดยเรียกใช้งาน procedures ที่มากับ Iceberg SQL extension (จำเป็นต้องติดตั้งลง Spark เพิ่ม)
Compact Data Files
การ compact data files คือการรวม data files และ delete files ให้เป็นไฟล์ที่มีขนาดตามที่เราต้องการ (default คือ 512 MB) โดยเราจะใช้procedure ที่ชื่อว่า “rewrite_data_files” ซึ่งการ compact จะเกิดภายใน partition ตัวเองเท่านั้น

ตัวอย่างของการ call “rewrite_data_files” procedure
CALL catalog.system.rewrite_data_files(
table => 'demo',
strategy => 'binpack',
options => map('min-input-files','2')
)code ข้างต้น หมายถึง ให้ทำการ rewrite data files ใหม่สำหรับ table ที่ชื่อว่า demo โดยใช้ strategy แบบ binpack และแต่ละ partitions ต้องมีอย่างน้อย 2 ไฟล์
จุดที่น่าสนใจ คือ strategy ที่สามารถเลือกได้ 2 แบบ คือ binpack และ sort
โดย binpack จะไม่สนใจเนื้อหาข้อมูล แค่อ่านไฟล์เล็กๆมารวมเป็นไฟล์ที่ใหญ่ขึ้น และอ่านไฟล์ใหญ่เกินไปมาแตกเป็นไฟล์ที่เล็กลง วิธีนี้ถือว่าง่ายและรวดเร็วที่สุด
อีกหนึ่งวิธีคือ sort สำหรับ sort จะมีการอ่านและเรียงข้อมูล ผลลัพธ์ที่ได้จะออกมาเป็นไฟล์ที่เรียงลำดับมาแล้ว ซึ่งเป็นการ optimized เพื่อการอ่าน หากเราเรียงโดยใช้หลาย columns จะเรียกว่า z-order

Expire Snapshots
การทำ operations ต่างๆในการใช้งาน Iceberg table เช่น write, update, delete ล้วนทำให้เกิด snapshot ใหม่ทั้งสิ้น โดย snapshots เก่าๆจะยังคงถูกเก็บไว้สำหรับการทำ time travel รวมไปถึง data files ก่อน compact ก็ยังคงเก็บไว้อยู่ด้วย
ตัวอย่างของการ call “expire_snapshots” procedure
CALL catalog.system.expire_snapshots(
table => 'demo',
older_than => TIMESTAMP '2024-01-15 01:00:00.000',
retain_last => 10
)code ข้างต้นหมายถึง ให้ลบ snapshots ของ table demo ที่เก่ากว่าตี 1 ของวันที่ 15 มกราคม 2024 และเก็บ snapshot ที่เก่ากว่าปัจจุบันไว้ 10 snapshots

procedure นี้จะทำการลบ snapshots ที่เก่ากว่าที่ตั้งเอาไว้ รวมไปถึง manifest files และ data files แต่สำหรับ manifest files และ data files ที่ยังเกี่ยวข้องกับ snapshots ที่ใช้งานอยู่จะยังเก็บไว้ให้ครับ
Remove Old Metadata Files
ก่อนหน้านี้เราได้ลบ snapshots เก่าๆไปแล้ว แต่นอกจาก snapshot ที่ถูกสร้างขึ้นมาใหม่เรื่อยๆ ก็มี metadata file ถูกสร้างขึ้นมาใหม่เรื่อยๆเช่นกัน (นับเป็น version ใหม่ไปเรื่อยๆ) โดยใน version ใหม่ที่ถูกสร้างขึ้นจะมี list ของ snapshot ก่อนหน้าไว้อยู่ด้วย ดังนั้นเราจึงสามารถลบ metadata files ที่ไม่ใช้ออกไปได้ ในส่วนนี้สามารถตั้งค่า table properties ตั้งแต่ตอนสร้างหรือ alter table ภายหลังได้
ตัวอย่างของการ Alter table เพื่อเพิ่ม table properties สำหรับการลบ metadata files เก่าๆออก
ALTER TABLE catalog.demo SET TBLPROPERTIES (
'write.metadata.delete-after-commit.enabled'='true',
'write.metadata.previous-versions-max'=10
)code ข้างต้น หมายถึง เราเพิ่ม 2 properties ให้กับ table demo ได้แก่ ให้ลบไฟล์ metadata เก่าสุดหลัง commit โดยอัตโนมัติ และจำนวน version สูงสุดที่เก็บไว้เท่ากับ 10 version

การ set table properties สามารถทำครั้งเดียวแล้วอยู่ไปตลอดได้เลย
Remove Orphan Files
Orphan files หมายถึงไฟล์ที่ไม่ถูก referenced ใน metadata ซึ่งไฟล์เหล่านี้อาจเกิดจากการ failed ระหว่างการ write data หรือเป็นไฟล์ก่อนทำการ compact แล้วไม่มี snapshot ใดๆมาอ้างอิงถึงแล้ว
ตัวอย่างของการ call “remove_orphan_files” procedure
CALL catalog.system.remove_orphan_files(
table => 'demo'
)code ดังกล่าวหมายถึง เราจะลบ orphan files ของ table demo โดย parameter อื่นๆให้เป็นค่า default

Conclusion
Iceberg นั้นถูก design มาให้รองรับ table ขนาดใหญ่มากๆ แต่การใช้งานที่ใกล้เคียง near real-time มากขึ้นอาจส่งผลให้เกิดการเก็บข้อมูลที่ไม่มีประสิทธิภาพ เป็นไฟล์เล็กๆจำนวนมาก รวมไปถึงเป็นการเพิ่ม metadata files และ snapshots ส่งผลให้ประสิทธิภาพการใช้งาน Iceberg table ลดลง และเกิด cost ในการเก็บไฟล์ที่ไม่ใช้งานโดยไม่จำเป็น ดังนั้นการ maintain Iceberg table เพื่อใช้งานระยะยาวควรเกิดการ maintenance เป็นระยะๆ สามารถทำได้โดย call procedure ผ่าน SparkSQL
- rewrite_data_files: compact ไฟล์ข้อมูลเล็กๆให้เป็นไฟล์ที่ใหญ่ขึ้น
- expire_snapshots: ลบ snapshots เก่าๆออก โดยจะไม่สามารถทำ time travel กว่ากว่า snapshots ที่ยังคงเหลือได้
- remove_orphan_files: ลบไฟล์ข้อมูลที่ไม่ถูก referenced โดย metadata ใดๆ
ส่วนการตั้งค่า table properties สำหรับการลบไฟล์ metadata เก่าๆจะทำให้เราอัตโนมัติไปตลอดครับ
หากข้อมูลส่วนไหนตกหล่นหรือผิดพลาดประการใด ขออภัยมา ณ ที่นี้ครับ ท่านใดมีคำถาม ข้อสงสัย หรือ feedback สามารถ comment ได้เลยนะครับ
ขอบคุณทุกท่านที่เข้ามาอ่านครับ :)
References:
- Official Docs: Spark Procedures, Table Configuration
- dremio: maintenance tasks, compaction