Kernels (Filters) in convolutional neural network (CNN), Let’s talk about them.
We all know about Kernels in CNN, most of us already used them but we don’t understand them properly. Here in this blog, I tried to explain some of the questions related to kernels and if you want to read more about them you can check out my previous blog.
1. Can we use 2 x 2 or 4 x 4 Kernels, Why do we always use 3 x 3 kernels?
First of all, let’s talk about the first part. Yes, we can use 2 x 2 or 4 x 4 kernels.

If we convert the above cats' image into an array and suppose the values are as in fig 2. When we apply 2 x 2 kernel on this array we will get a 4 x 4 output matrix. But when we apply 3 x 3 kernel we will get a 3 x3 output matrix.
Our algorithm will have thousands of cats’ images to process and pass each image through multiple neural network layers so if we use a 2 x 2 kernel our computation power will increase and the algorithm will take much more time to compute the output as compared to 3 x 3 kernel. So it is more effective to use 3 x 3 kernel instead of 2 x 2 kernel.

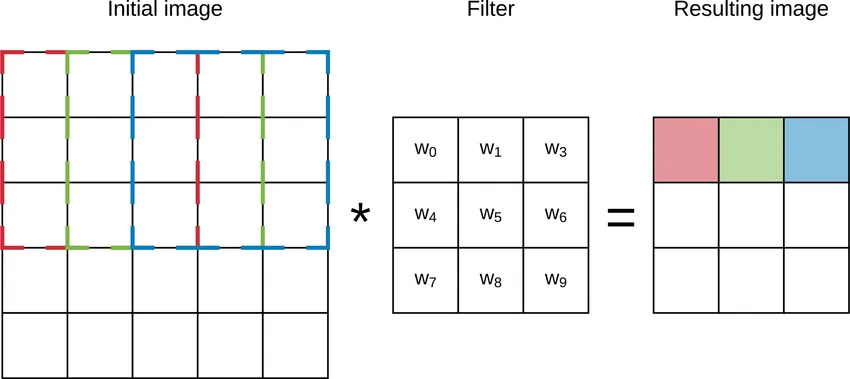
Now, I know what you are thinking, if we use a 4 x 4 kernel then we will have a 2 x 2 matrix and our computation time will decrease more than 3 x 3 kernel, but you are converting your 6 x 6 matrix image into 2 x 2 matrix; there is a higher chance that you will not capture important features from your images and also there will be noise in the output matrix.
So overall using a 3 x 3 kernel is a more effective and safe choice in deep learning. Also, 3 x 3 kernel is a superset of 2 x 2 and 1 x 1 kernel, which means we can use 3 x 3 kernel as 2 x 2 or 1 x 1 kernel.
2. Why do we use Symmetrics Kernels?
You converted the above image into a 6 x 6 matrix, it’s a 1D matrix and for convolution, we need a 2D matrix so to achieve that we have to flip the kernel, and then it will be a 2D matrix. Also, convolution without a flip is a correlation.
If we use a non-symmetrics and non-symmetrics matrix, we can’t have its inverse, so we will never get a convolution.
If we Horizontally Flip Square or Symmetrics matrics they will not change. Also, some kernels are never changing to vertical flip or approximate rotational.
Such kernels act as a regularizer and improve the generalization of the convolutional neural networks at the cost of a more complicated training process.
Research paper link: https://arxiv.org/abs/1805.09421
3. Why the size of the images should not equal kernel size?
If we choose the size of the kernel smaller then we will have lots of details, it can lead you to overfitting and also computation power will increase.
Now we choose the size of the kernel large or equal to the size of an image, then input neuron N x N and kernel size N x N only gives you one neuron, it can lead you to underfitting.
4. How are kernel’s input values are initialized and Learned in a convolutional neural network (CNN)?
There are many different initializing strategies:
- Set all values to 0 or 1 or another constant.
- Sample from distribution, such as normal or uniform distribution.
- You can initialize kernels with predefined values.
Traning is a procedure of adjusting the values of these elements.
Given an input, all the layers elements effectively constitute a transformation of this input to a predicted output. The measure of variation between this predicted output and the actual output is defined as a loss. The value of this loss is then passed backwards through these filters and used to adjust the values in the filters to effectively minimize the difference between predicted and actual output. This way the value of the filters is adjusted during training and the system is said to have converged when the loss is minimized.
Network filters can also be initialized from the weights of another network. This is popularly called transfer learning and is used successfully for better and faster convergence of many problems.
If you know some other questions then you can mail them to me.
Mail id: kadamrahulj0909@gmail.com
Thanks…