
Lavínia e o embate: #moroCriminoso versus #EuApoioALavaJato
Primeiramente, esta é a Lavínia e daqui a nossa história começa…
Uma das coisas interessantes sobre trabalhar com dados é pensar em como disponibilizá-los e como torná-los atraentes, principalmente quando estes dados geram polêmica e estão no meio de um furacão. Contando com um grupo muito interessante de pessoas como o Charles Santana, Fernando Almeida Barbalho, Tomás Barcellos e Leonardo Nascimento pensamos em algumas soluções para essa questão. A primeira delas é disponibilizando os códigos utilizados e os bancos de dados em repositórios de livre acesso, como o Github. A segunda é criando dashboards interativos que permitam a qualquer pessoa “brincar de cientista de dados”.
Disponibilizado os dados, os códigos e dashboards interativas, nos é apresentada a hora de esclarecer um pouco sobre o que temos feito, esmiuçar os métodos e os resultados e deixarmos os leitores criarem suas hipóteses e testá-las.
O contexto
Lançadas, então, as notícias sobre o vazamento de conversas do ex-juiz Sérgio Moro por parte do Intercept, surgiram duas hashtags nas redes sociais de grande relevância para o nosso estudo e que no seu conjunto apresentam um embate de ideias centradas, principalmente, na figura do supracitado ex-juiz. São elas #MoroCriminoso e #EuApoioALavaJato.
O mais intuitivo a se pensar, ao se iniciar a análise de um debate caloroso como este, é visualizar quais palavras estão mais associadas aos dois discursos, buscando de alguma forma inferir acerca dos caminhos que cada um dos lados se propõem. A Figura 1 abaixo mostra o as palavras mais citadas em tuítes contendo cada uma das hashtags estudas aqui.

A maioria das publicações relacionadas à hashtag #MoroCriminoso estão associadas à operação lava-jato — centro de qualquer discurso possível no momento — à figura do ex-presidente Lula e ao The Intercept (citar Moro em qualquer uma das hashtags seria redundante já que o embate o tem como figura motivadora).
É possível inferir que este posicionamento destaca bastante a questão da validade do julgamento do ex-pesidente Lula, uma vez que as notícias evidenciam uma atuação suspeita por parte do ex-juiz na Lava Jato que por sua vez teve como figura mais emblemática Lula.
Do outro lado, a hashtag #EuApoioALavaJato tem no seu discurso palavras ligadas à esquerda, a corrupção e a cadeia. Ou seja, o discurso girava em torno das benesses que a operação Lavo Jato trouxe à sociedade ao condenar corruptos e ao fato de que a maioria dos condenados da Lava Jato foi políticos que participaram dos governos de esquerda de Lula e Dilma.
Modelando Palavras
A análise do discurso pode ir além de simplesmente olhar as palavras mais comuns de um texto, mas há vários desafios nessa tarefa. Primeiramente, a inspeção de todas as palavras é bastante complicada, tendo em vista que no dia da publicação da reportagem do Intercept havia cerca de 200 mil tuítes falando a seu respeito.
Outra questão que se faz pertinente é identificar que a frequência de cada palavra não diz respeito, necessariamente, à capacidade dela de sugerir se um tuíte cita a hashtag #MoroCriminoso ou a #EuApoioALavaJato. Para observar isto, basta olhar para os termos “lava”, “jato”, “lula”, “moro” que são bastante frequentes em ambos.
Surge, então, a necessidade de um modelo que seja capaz de identificar o acréscimo que determinada palavra dá para a classificação de um tuíte em uma das duas classes trabalhadas (#MoroCriminoso e #EuApoioALavaJato).
Para isto, a partir dos aproximadamente 200 mil tuítes obtidos até o dia 14 de Junho, foi criado um modelo de regressão logística, considerando as palavras como variáveis, partindo da combinação das regularizações L1 e L2 (Elastic-Net). Esta abordagem é interessante tendo em vista o número de variáveis, já que este tipo de regularização minimiza os efeitos do overfitting e acaba por contribuir para a seleção de variáveis mais importantes.
O primeiro resultado conveniente desta abordagem é que um determinado termo não pode contribuir significativamente para a classificação das duas classes, ou seja, os termos muito presentes em ambas tem influência próxima a 0.
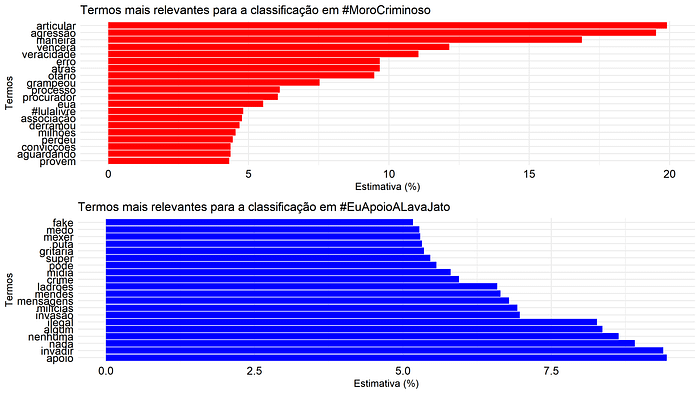
Quanto aos resultados, podemos identificar que estes se alinham com os discursos apresentados até o presente momento. A Figura 2 mostra dois gráficos em que o eixo vertical representa palavras e o eixo horizontal representa a probabilidade de aquela palavra aparecer em um tuíte com as hashtags #MoroCriminoso (em vermelho) ou #EuApoioALavaJato (em azul).
De um dos lados, concordando com as palavras mais citadas, estão termos que regem sobre a veracidade do julgamento (“articular”, “veracidade”, “erro”, “processo”) e, claro, a #lulalivre, referente ao protagonista (antagonista) da operação Lava Jato junto ao juiz Moro.
Do lado oposto, o discurso se faz em torno da ilegalidade das mensagens divulgadas, pondo de forma marginal o conteúdo destas ou colocando em cheque a sua veracidade.
Modelando Frases
Chegamos à parte mais ousada de nossa análise. Até este momento brincávamos com palavras, mas como identificar uma opinião? Eis que, então, surge uma perspectiva mais ousada de classificar uma opinião tendo em vista as duas hashtags supracitadas.
Para isto, um modelo de classificação foi treinado utilizando XGBoost, dada a sua capacidade de trabalhar com matriz esparsas e de obter resultados bastante pertinentes, uma vez que é uma boosted tree. Este modelo recebe todas as palavras de uma frase e a classifica como pertencente ao grupo #MoroCriminoso ou #EuApoioaLavaJato.
Deste ponto já teríamos um modelo que preveria a classificação em cerca de 85% das vezes. Seria suficiente, mas o modelo que temos é uma caixa preta, como os usuários observariam o porquê daquela classificação? O quanto isto prejudicaria a aproximação destes com esta funcionalidade?
Por isto, lançou-se mão do LIME, algoritmo muito pertinente para interpretação de modelos caixa-preta. Isso permite que, dado um texto qualquer, sejam identificadas quais palavras são chaves para a sua classificação.
Para exemplificar o uso da técnica empregada usaremos uma frase dita por Reinaldo Azevedo (Figura 3):
“A montanha já deu à luz algumas ratazanas que atentam contra a democracia e o estado de direito sob o pretexto de combater a corrupção.”

Este caso é particularmente interessante porque estamos testando uma frase dita mais de uma semana após o treinamento da Lavínia. Ela está predita como participante da #MoroCriminoso (label 1) e está CORRETA!.
Agora, quanto às palavras em destaque, qual a “mágica”? É neste momento que o LIME atua, buscando no classificador quais palavras foram essenciais para que determinada frase seja predita em uma das classes. No exemplo em questão, as palavras “democracia” e “direito” tiveram grande influência para a determinação da posição do discurso.
Outro teste de grande relevância é utilizar uma declaração do próprio Sérgio Moro e observar como a Lavínia reage (Figura 4):
É uma invasão criminosa por um grupo criminoso organizado, que tem, por objetivo, ou invalidar condenações por corrupção e lavagem de dinheiro, ou obstaculizar investigações que ainda estão em andamento e que ainda podem atingir pessoas poderosas, ou simples ataques às instituições brasileiras.

Mais uma vez, o algoritmo vai bem. Acerta a palavra do maior defensor da Lava Jato, o próprio juiz. Identificando, ainda, através do LIME, as palavras chaves e que por sinal refletem o discurso proferido por este que está pautado na invalidação das mensagens e na invasão criminosa da sua privacidade.
Agora sim, temos um dashboard que tem a possibilidade de suscitar dúvidas, hipóteses e curiosidade nos usuários que querem por em cheque suas opiniões, ou que querem reproduzir discursos jornalísticos e institucionais e querem inferir em qual lado este se encontra.
Sobre os autores
Charles Novaes de Santana: “Lulista de Dados” com experiência em modelagem computacional e análise de dados usando sistemas complexos, estatística computacional e inteligência artificial. Programador nas linguagens R, C++ e Julia. Graduado em Ciência da Computação (2006), com mestrado em ciências ambientais (2007), e em mudanças climáticas (2009) com doutorado na mesma área (2013). Atualmente atua como Pesquisador de Postdoc no ETH-Zurich. Co-fundador da empresaDataSCOUT.
Tarssio Barreto: “Lulista de Dados”, estudante de doutorado do Programa de Engenharia Industrial da Universidade Federal da Bahia. Formado em Engenharia Sanitária e Ambiental (2015) e com mestrado na mesma área (2017). Dedico o seu tempo ao aprendizado estatístico e aprendizado de máquina com particular interesse em métodos de redução de dimensionalidade, temas relacionados a modelagem ambiental e qualquer desafio que lhe tire o sono!
Fernando Barbalho — Doutor em Administração pela Universidade de Brasília (2014). Atualmente é auditor federal de finanças e controle da Secretaria do Tesouro Nacional (STN). A trajetória profissional e acadêmica mais recente está principalmente relacionada a dados abertos e desenvolvimento de produtos que resultem em maior transparência do Setor Público brasileiro. Nos finais de semana costuma utilizar o R para investigar perguntas de pesquisa que escapam ao mundo das finanças públicas.
Tomás Barcellos — Formado na Universidade Federal de Santa Catarina (2014). Trabalha no Ministério da Agricultura, Pecuária e Abastecimento desde 2015, atuando hoje como Coordenador de Inovação. É mestrando do Programa de Pós-Graduação em Estudos Latino-Americanos da UnB.
Leonardo Nascimento — Químico pelo Instituto Federal de Educação, Ciência e Tecnologia da Bahia — IFBA (1997), graduado em psicologia pela Universidade Federal da Bahia — UFBA (2002), mestre em sociologia pela Universidade de São Paulo — USP (2007) e doutor em sociologia pelo Instituto de Estudos Sociais e Políticos — IESP/UERJ (2013). Atualmente é professor do Instituto de Ciência, Tecnologia e Inovação da UFBA. Apesar de ser um padawan em R, acredita cegamente que apenas os métodos digitais, em especial a linguagem R, poderão salvar as ciências sociais.
