Algoritmos de otimização: Hill Climbing e Simulated Annealing

Os algoritmos de otimização são de grande importância para nos ajudar a resolver certos tipos de problemas onde métodos comuns não são o suficiente. Nesse artigo, irei explicar alguns conceitos e algoritmos importantes nessa área e deixar disponível exemplos de suas implementações.
Conteúdos abordados no artigo:
- Introdução aos algoritmos de otimização
- Algoritmo Hill Climbing (subida da encosta)
- Algoritmo Simulated Annealing (recozimento simulado)
- Técnicas para melhorias nos algoritmos de busca
- Implementação em Python
- Conclusão
1. Introdução aos algoritmos de otimização
Provavelmente você já ouviu falar do problema clássico do caixeiro-viajante, onde o objetivo é tentar encontrar a menor rota para percorrer uma sequência de cidades, passando apenas uma vez por cada uma delas e voltando até a cidade de início.
Problemas como esse possuem diversas soluções possíveis, ainda que apenas uma delas seja considerada a melhor. Por exemplo:
- Podemos fazer o trajeto de cidades A-B-C-A com uma distância percorrida de 300 km
- Podemos também fazer o trajeto de cidades A-C-B-A com uma distância de 280 km
Nos dois casos, cumprimos com o objetivo de passar por todas as cidades sem repetição e voltar para o ponto inicial A, todavia na segunda tentativa conseguimos minimizar a distância em 20 km, podendo ser considerado a melhor solução para o problema.
Mas por que precisamos utilizar um algoritmo de otimização?
Nesse exemplo tínhamos apenas 3 cidades (A,B e C), o que nós dá um número muito limitado de iterações. Todavia podemos imaginar esse problema sendo feito com dezenas ou até centenas de cidades, criando um espaço de solução muito grande, com milhões de possíveis combinações que vão gerar diferentes resultados (chamado na computação de problema NP-complexo).
Dito isso, tentar encontrar a melhor combinação com um número tão grande de soluções é praticamente impossível, pois exigiria um poder computacional massivo e ainda assim o tempo de execução seria impraticável.
Também poderíamos tentar randomizar essa busca gerando combinações aleatórias, o que pode até funcionar até certo ponto, porém é uma abordagem bastante limitada em tentar encontrar uma boa solução, pois pontos aleatórios se fundamentam apenas na exploração de um espaço e não na sua explotação, sendo improvável por si só de trazer resultados satisfatórios.
É pensando nisso que aplicamos os algoritmos de otimização, onde o objetivo geral é chegar a uma boa solução (que talvez não seja a melhor) em um tempo de execução aceitável.
Essa solução boa é chamada de mínimo ou máximo local e a melhor solução possível é chamada de mínimo ou máximo global (que dificilmente é encontrada).
Usamos mínimo caso nosso problema tente minimizar o valor alvo e máximo caso tente maximizar. No nosso exemplo a ideia é minimizar a distância percorrida no trajeto, portanto nosso alvo é chegar a um mínimo global.
Na imagem abaixo podemos ter uma noção visual do que foi dito.

Espaço de solução
O espaço de solução (ou espaço de busca) é o conjunto de todas as possíveis soluções, sendo geralmente ilustrado por um plano cartesiano (x,y) como visto acima ou por uma figura tridimensional como abaixo:
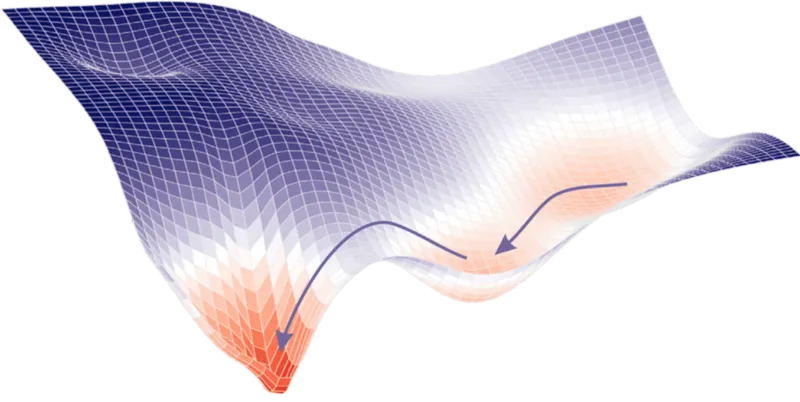
Na prática, como acabamos de discutir, não é possível visualizar todo o espaço de solução de um problema extremamente complexo com dezenas de variáveis e milhões de possibilidades, porém nós sabemos de sua existência e sempre tentamos encontrar o melhor resultado para os nossos problemas.
Qual a melhor solução? atingimos um ponto global?
Existem alguns problemas em que nós temos a solução alvo pré-definida, por exemplo, podemos supor que no caso do caixeiro nós vamos tentar diferentes combinações até chegar a uma distância precorrida entre as cidade de 220 km, sendo assim, quando nosso algoritmo atingir esse valor (se é que conseguirá atingir) nossa condição para o algoritmo é satisfeita.
Todavia, muita das vezes nós não possuímos essa solução pré-definida e o objetivo geral se resume em maximizar ou minimizar o quanto for possível um determinado valor. Seguindo o mesmo exemplo, podemos executar nossos algoritmos diversas vezes e obter diferentes resultados de distância. Nossa solução será aquela que tiver o menor valor em quilômetros.
Ainda assim, na prática nós não sabemos qual é o ponto global, ou seja, aquele melhor possível para nosso problema, pois o mesmo costuma ser extremamente difícil de ser encontrado e mesmo que seja, nós provavelmente nunca saberemos se ele é um ponto global ou não.
Por exemplo, pode ser que você conseguiu minimizar a distância entre as cidades para 200 km e pense que esse seja o melhor resultado possível na sua combinação.
Todavia pode acontecer, e é bastante comum no mundo real, que em alguma outra circunstância (algoritmo diferente, mais poder de processamento, ou sorte) uma outra pessoa consiga minimizar essa distância para 190 km, sendo esse o novo menor ponto do problema. Mas seria esse o menor possível? Não temos como saber, mas não se preocupe, por que isso não importa.
Não importa porque ainda que, na teoria, os algoritmos de otimização sejam uma luta constante para se atingir o ponto global, na prática só precisamos encontrar uma solução que seja boa o bastante para resolver o nosso problema.
Exploração e explotação
Os algoritmos de otimização de forma geral precisam buscar uma abordagem eficiente para percorrer o espaço de soluções a fim de encontrar o melhor ponto, e para isso utilizamos uma mescla de técnicas de exploração e explotação.
Na exploração, o objetivo é abrir os horizontes, percorrendo as soluções candidatas de forma mais espaçada, porém sem se aprofundar tanto.
Já na explotação a ideia é limitar nossa busca por soluções a uma pequena região no espaço, porém se aprofundando o máximo possível.
Para exemplificar os conceitos, vamos supor que você descobriu que no seu quintal existem pepitas de ouro e você quer encontrá-las.
Se você decidir por uma abordagem exploratória, você poderá cavar por alguns metros em pontos aleatórios do seu quintal, aumentando a chance de encontrar o ouro em termos de abrangência.
Todavia se a sua abordagem for de explotação, você irá cavar por vários metros porém em uma única região do quintal, aumentando a chance de encontrar caso o lugar do quintal que você escolheu por acaso tenha algum ouro.
Como você pode observar, nas duas abordagens existem vantagens e desvantagens, sendo uma troca que você deve escolher fazer entre uma e outra. As duas também podem ser combinadas, porém aumentando o custo computacional e tempo de processamento.
2. Algoritmo Hill Climbing (subida da encosta)
O Hill Climbing é um algoritmo clássico para otimização, sendo bastante eficiente na tarefa de encontrar máximos ou mínimos locais, usando da técnica de explotação que vimos anteriormente.
Nesse algoritmo nós iniciamos de um ponto aleatório X e fazemos a sua avaliação.

Feito isso, nós nos movemos do nosso ponto X original para um novo ponto vizinho ao que estamos o X’.
Se esse novo ponto X’ for uma solução melhor do que nosso ponto anterior, ficamos nele e fazemos esse processo novamente, porém caso seja inferior, voltamos para nosso ponto inicial X e tentamos visitar um outro vizinho.

Dessa forma, o algoritmo vai gerar pequenos movimentos que melhoram progressivamente os resultados.
Uma das principais “limitações” do Hill Climbing é que ele não aceita valores negativos, ou seja, ele sempre tenta buscar pontos vizinhos no espaço de solução que vão melhorar seu estado atual, caso ele não encontre melhoria, a execução é parada.

No exemplo acima, podemos ver um caso em que o algoritmo iria parar, pois ao chegar naquele máximo local, todos os seus próximos movimentos resultariam em uma piora nos resultados (ainda que essa seja uma piora momentânea), por isso o Hill Climbing é ótimo em encontrar as boas soluções (pontos locais) mas dificilmente vai encontrar a melhor solução (a menos que você tenha sorte na inicialização do ponto inicial).
3. Algoritmo Simulated Annealing (recozimento simulado)
O Simulated Annealing é mais um dos algoritmos inspirados pela natureza, assim como as redes neurais artificiais e os algoritmos genéticos. O recozimento é um processo térmico bastante utilizado no aprimoramento de aços, onde o material é aquecido até altas temperaturas, fazendo com que os átomos se movimentem livremente e depois é resfriado gradativamente para que as moléculas se encaixem em uma melhor posição.

Esse mesmo princípio é usado no algoritmo de recozimento simulado, começando em temperaturas altas e resfriando lentamente. Em termos de busca, esse algoritmo usa ambas as técnicas de exploração em temperaturas iniciais mais elevadas e muda para explotação conforme a temperatura diminui como podemos ver abaixo:

De forma parecida com o Hill Climbing nós iniciamos de um ponto aleatório X e fazemos sua avaliação.
Feito isso, o algoritmo faz um movimento até um dos seus vizinhos X’ e avalia esse novo ponto. Se os resultados melhoraram no nosso ponto X’ então nos movemos até ele e refazemos o processo anterior, todavia se o ponto X’ for inferior nós só iremos nos mover para ele caso nossa probabilidade de ir para um ponto negativo seja superior a um número aleatório.
Uma das grandes vantagens do algoritmo de recozimento simulado é aceitar valores negativos, diferentemente do Hill Climbing.
A probabilidade de aceitar um valor negativo é definida por:
probabilidade(p) = Exp(X’- X / T)
Essa função exponencial calcula a diferença do nosso ponto vizinho X’ subtraída pelo ponto X em que estávamos anteriormente, dividido pela temperatura (variável T).
Com isso, nas primeiras iterações do algoritmo, quando nossa temperatura T está mais elevada, nós temos uma probabilidade maior de aceitar valores negativos e conforme são decorridas as iterações essa probabilidade diminui.
Por isso, esse algoritmo tem uma propriedade bastante exploratória à princípio, pois consegue se movimentar mais livremente pelo nosso espaço de solução, e conforme a temperatura vai se aproximando de 0, essa movimentação tente a diminuir pois o algoritmo praticamente só admite valores positivos.
Um ponto de atenção importante é que o esse algoritmo possui parâmetros que devem ser otimizados e afetam diretamente os resultados obtidos. Um deles é a temperatura (T) e o outro é a taxa de resfriamento.
Cada problema deve ter seu próprio conjunto de parâmetros para buscar a melhor solução.
4. Técnicas para melhorias nos algoritmos de busca
Existem algumas técnicas importantes que foram desenvolvidas para melhorar o desempenho dos algoritmos de otimização e que podem ser importantes para nos ajudar nesse difícil tarefa de otimizar soluções.
Parada no platô
Nosso espaço de solução não é apenas definido por picos e vales, mas também possui alguns platôs, ou seja, são locais no espaço onde o resultado se mantém o mesmo, sem piorar nem melhorar.

Esses espaços planos podem ser uma verdadeira armadilha para nosso algoritmo, deixando ele completamente preso, em um ciclo de ida e volta.
Como você pode ver na imagem, se o espaço reto for seguido de uma melhoria, nós o chamamos de shoulder (ombro) e nesse caso existe uma esperança de solução caso nosso ponto consiga chegar até a próxima “montanha”. Todavia se não houver mais pontos de melhoria ele é considerado um máximo (ou mínimo) local reto.
Todos os nosso algoritmos de otimização possuem um critério de parada baseado no número de iterações, para não correr nenhum risco de se entrar em um loop infinito. Todavia é uma perda de tempo executar o algoritmo até que ele ultrapasse esse número de iterações máximo caso ele tenha caído em um plato sem melhoria.
Pensando nisso, a técnica de parada no platô nada mais é do que um contator que começa a ser acrescentado em cada iteração do nosso algoritmo que não apresenta melhoria na solução.
Sendo assim, hora que esse contador chegar a um valor especificado por nós (e que também deve ser otimizado para não perder os espaços de “shoulder”) nosso algoritmo tem sua execução interrompida, podendo ser uma ótima abordagem para economizar tempo e escapar de armadilhas como essa.
O algoritmo Hill Climbing, que não aceita valores negativos, é especialmente beneficiado por essa abordagem, pois tem maiores chances de ficar preso em um platô.
Redução do passo de movimentação no espaço
Como nós vimos nos GIFs anteriores, nossa movimentação no espaço de solução é dada através da avaliação dos vizinhos, porém o que é o nosso vizinho?
O vizinho é um ponto próximo ao nosso ponto atual, porém essa proximidade é definida por um parâmetro de passo escolhido por nós, também conhecido como taxa de aprendizado nas redes neurais.
Seguindo o exemplo do caixeiro viajante, se nós definirmos que nossa cidade vizinha é aquela à 50 km do nosso ponto atual, vamos ter que nosso vizinho da cidade A é a cidade B, todavia se essa distância for de 100 km então nosso vizinho é a cidade C.
Como é de se esperar, quanto maior esse “passo” (que nesse caso são os quilômetros, pois é o valor que queremos otimizar) mais rapidamente nós iremos nos mover pelo nosso espaço de solução e quanto menor mais lento será o processo.

Ao lado podemos ver uma comparação prática de como a movimentação dos pontos no espaço se comportam ao mudarmos esse parâmetro.

Se nosso parâmetro for grande, nós iremos nos movimentar mais rápido, fazendo com que o tempo de execução do algoritmo seja menor e possibilitando abranger uma área maior do espaço, porém a desvantagem é que temos uma chance maior de perder o máximo/mínimo local ou até global, pois o passo de 100 km pode acabar ignorando uma cidade da rota que resultaria em uma diminuição na distância, sendo assim um passo grande pode simplesmente passar reto, pulando o pico da montanha (que por sorte não foi o que aconteceu no GIF).
Por outro lado, se nosso parâmetro for muito pequeno, nossa movimentação pelo espaço vai ser mais lenta, o que pode levar ao algoritmo a um tempo de execução muito grande se quisermos percorrer uma parte considerável do nosso espaço, todavia temos a vantagem de minimizar o risco de perdermos uma boa solução.
Uma abordagem para lidar com isso é fazer a redução dinâmica do passo, onde começamos com ele maior e diminuímos à medida que nosso resultado melhora.
Dessa forma, podemos seguir com uma movimentação mais rápida de forma geral, porém conforme nossa solução vai melhorando, ou seja, vamos nos aproximando de pico ou vale (dependendo se for máximo ou mínimo local) nosso passo diminui gradativamente para não correr o risco de perder a melhor solução.
Com essa abordagem, nós conseguimos um tempo de execução interessante sem perder de vista nosso objetivo de melhorar ao máximo a solução para nosso problema.
Inicialização não randômica
Como vimos na explicação básica dos algoritmos de Hill Climbing e Simulated Annealing nosso primeiro passo da execução começa com a inicialização de um ponto X escolhido de forma aleatória no espaço.
Todavia essa inicialização, apesar de ser aparentemente algo fora do nosso controle, é bastante importante para nossos resultados. Quando estamos tentando encontrar as melhores soluções para nosso problema, não iremos executar o algoritmo apenas uma vez, mas ele será executado diversas vezes em que cada uma delas apresentará diferentes resultados, devido às características estocásticas (aleatórias) desses algoritmos de otimização.
O Hill Climbing por exemplo, vai sempre encontrar o máximo local mais próximo e seus resultados dependem muito do local que ele iniciou, se por sorte o nosso ponto inicial aleatório for na “montanha” do máximo global, nós conseguiremos atingir os melhores resultados.
Portanto, uma abordagem utilizada para aumentar nossas chances de conseguir bons resultados é trabalhar na inicialização do nosso ponto X.
Podemos fazer isso de duas formas:
- Inicializar em um local que apresenta melhorias.
- Ter um espaçamento entre os pontos de inicialização
antes de discutir sobre essa abordagem, vamos apenas relembrar sobre nosso domínio do problema.
Todo problema possui um domínio, ou seja, o espaço de valores em que iremos trabalhar para encontrar a solução.
Esse domínio deve ser uma das primeiras coisas a serem definidas na implementação do algoritmo. Por exemplo, podemos ter o domínio entre [0, 1], ou seja, nossa solução poderá ser qualquer valor entre o 0 e o 1.
No exemplo do caixeiro viajante, nosso domínio é basicamente todas as nossas cidades, sendo a solução uma combinação de qualquer uma delas, porém com o ponto inicial e final igual à cidade definida como ponto de origem.
O que acontece então, é que muita das vezes nós atingimos uma solução melhor em determinados espaços do domínio (baseado em execuções anteriores do algoritmo).
Por exemplo, se percebermos que entre 0 e 0.5 nossas soluções estão consideravelmente melhores do que entre 0.5 e 1, podemos optar por limitar nosso domínio de solução, fazendo com que nossa inicialização se limite à esse espaço que tem gerado melhores soluções.
Isso pode ser especialmente útil em situações onde o domínio do problema é muito grande, pois se limitarmos o domínio, o número de combinações possíveis também é limitado, fazendo com que o espaço de solução diminua.
Quanto a segunda abordagem, a ideia é gerar uma diferença mínima entre um ponto e outro para garantir que o espaço seja explorado em termos de inicialização.
Isso acontece por que nossos pontos aleatórios podem acabar sendo gerados próximos um do outro na medida em que o algoritmo vai sendo executado novamente.
Por exemplo, se executarmos o Hill Climbing 5 vezes e tivemos os seguintes pontos iniciais X: [0.15, 0.2, 0.7, 0.5, 0.11].
Como podemos ver, os pontos 0.15, 0,11 e 0.2 estão próximos uns dos outros, fazendo com que fiquemos limitados à mesma área do espaço.
Nessa abordagem, nós definimos um valor mínimo de espaçamento entre cada uma dos pontos X que inicializará o nosso algoritmo, fazendo com que a área do espaço seja mais explorada, mesmo em algoritmos que são fortes por explotação.
Todas essas técnicas fazem diferença e devem ser consideradas ao utilizar algoritmos de otimização de problemas.
5. Implementação em Python
O objetivo geral desse artigo foi de explicar, ainda que de forma básica, o funcionamento dos algoritmos de otimização e alguns dos conceitos por trás dessas técnicas.
Em futuros artigos pretendo trazer uma explicação detalhada da implementação desses algoritmos em Python. Por hora , é possível conferir meu repositório no GitHub caso você queria descobrir como implementar esses algoritmos.
Nesse repositório fiz um Jupyter notebook com a implementação dos dois algoritmos aqui discutidos para tentar otimizar o resultado de uma função matemática, além de alguns comentários explicando o código e os conceitos.
Fique a vontade para fazer comentários ou sugestões caso possua alguma dúvida.
6. Conclusão
Os algoritmos de otimização nos dão a possibilidade de encontrar boas soluções de problemas complexos e não lineares sem levar anos de processamento computacional, sendo essenciais para áreas como a inteligência artificial por exemplo. Ter um bom entendimento de como funcionam esses algoritmos pode ser decisivo ao tentar encontrar melhores soluções para os mais diversos problemas.
