Controle Sintético: Como Aplicar Inferência Causal na Prática
Uma abordagem para identificar e medir impactos de intervenções reais

Sumário
→ Introdução à Causalidade
→ Introdução ao Controle Sintético
→ Exemplo Didático e Definições
→ Controle Sintético com Regressão Linear
→ Aplicação Prática
→ Conclusão
→ Referências
Introdução à Causalidade
Provavelmente muitos de vocês cientistas e analistas de dados já se depararam com a frase:
Correlação não implica causalidade!
Se você nunca tinha ouvido falar, então preste atenção nestes gráficos.
Gráfico 1: Nesta primeira Figura podemos ver a curva de popularidade do nome Sarah e a cobertura florestal remanescente na Amazônia brasileira

Apesar de as linhas seguirem um padrão semelhante ao longo do tempo e estarem muito correlacionadas, não há uma relação causal que seja plausível entre essas duas variáveis. Seria o maior dos absurdos afirmar que o desmatamento da Amazônia impacta a popularidade de nomes de bebês nos EUA.
Gráfico 2: Nesta segunda Figura vemos a quantidade de buscas no Google pelo nome de Matt Levine e o número de college administrators em Ohio

No gráfico acima temos uma situação parecida, embora as linhas se movam em sintonia, isso não indica que uma variável causa a outra.
Existem diversos destes exemplos na internet, mostrando como alguns padrões de correlação podem surgir por coincidência, ou por algum fator externo (inicialmente não identificado), sem qualquer relação causal entre as variáveis. Para chegar a conclusões causais, precisamos de metodologias específicas que vão muito além da análise de correlações.
É aí que entra a inferência causal, que nos fornece ferramentas robustas o suficiente para estudar relações de causa e efeito. Entre estas técnicas estão:
- Controle Sintético (Synthetic Control)
- Variáveis Instrumentais (Instrumental Variable — IV)
- Diferenças em Diferenças (Diff-in-Diff)
- Descontinuidade de Regressão (Regression Discontinuity Design — RDD)
- Pareamento (Matching)
Este será o primeiro artigo de uma série de cinco artigos sobre inferência causal, cada um sobre um tópico a ser explorado, começando com Controle Sintético.
Introdução ao Controle Sintético
Vamos considerar uma situação hipotética em que uma Cidade A decide implementar uma política de transporte público gratuito para todos os seus habitantes!!
(Momentos de Euforia)
Em termos de inferência causal, a Cidade A é o nosso grupo tratado, ou grupo que sofreu a intervenção.
Com isso, você deseja entender:
Qual o impacto dessa política na redução do tráfego de veículos?
E mais, outra pergunta fundamental seria:
O que teria acontecido com a Cidade A se ela NÃO tivesse recebido a intervenção?
Sim, estas respostas são possíveis de serem obtidas. Mas pense comigo! Se compararmos apenas com outra cidade, poderíamos cometer erros graves, já que fatores como densidade populacional, infraestrutura urbana e hábitos de mobilidade podem variar significativamente entre as cidades.
Podemos resolver isso criando uma “cidade sintética” (contrafactual), através de uma combinação de dados de várias outras cidades que não receberam a intervenção, isso é o controle sintético. Essas cidades seriam escolhidas de forma que suas características se assemelhem o máximo possível às da Cidade A antes da implementação da política.
Assim, após a intervenção, podemos comparar o comportamento da Cidade A com o da cidade sintética para isolar o efeito da política de transporte público gratuito, eliminando a influência de variáveis externas que poderiam impactar ambas as cidades.
Exemplo Didático e Definições
Um exemplo bem didático é o presente no livro “Causal Inference for The Brave and True”, do Matheus Facure.
Vamos imaginar o seguinte problema:
Queremos descobrir o efeito que o aumento de impostos sobre cigarros causam no consumo desse produto
De um lado, estão as pessoas que argumentam que impostos mais altos tornam os cigarros mais caros, reduzindo sua demanda.
Do outro lado, estão aqueles que acreditam que, como os cigarros são altamente viciantes, mudanças no preço não afetam muito o consumo. Ou seja, nesse caso, os economistas diriam que a demanda por cigarros é inelástica ao preço — um aumento nos impostos teria pouco impacto no comportamento dos fumantes.
O fato é que, na Califórnia em 1988 foi aprovada a Proposição 99, uma lei que adicionou uma taxa de 25 centavos por maço de cigarros vendidos no estado, além de criar impostos para outros produtos de tabaco, como charutos e tabaco de mascar.
Se plotarmos as vendas de cigarro na Califórnia (em azul) e a média das vendas nos demais estados, teremos o seguinte comportamento:
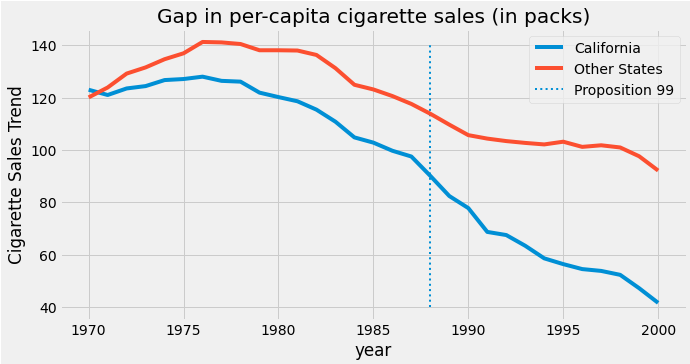
Repare que há uma indicação no gráfico mostrando a ocorrência da Proposição 99 em 1988, tratando-se da intervenção.
Também podemos perceber que:
- Após o início dos anos 1970, a Califórnia vendeu menos cigarros que a média dos outros estados
- A venda de cigarros entrou em uma curva mais acelerada de decadência após o início dos anos 1980, tanto para Califórnia quanto para os outros estados
- Após a Proposição 99, em 1988, as vendas estão decaindo ainda mais na Califórnia
Com isso podemos nos perguntar:
Qual foi o real efeito da Proposição 99 nas vendas de cigarro na Califórnia?
Para isso, vamos criar uma combinação ponderada de unidades de controle que simula como seria o comportamento do grupo tratado caso ele não tivesse recebido a intervenção.

Nesse caso, temos que:
Grupo Tratado: É a unidade que sofreu a intervenção (no caso é o estado da Califórnia)
Grupo de Controle: São todas as unidades que não sofreram a intervenção e que são usadas para prever a unidade sintética
Desta forma, gerando o controle sintético, podemos plotá-lo juntamente com os valores do grupo tratado (vendas de maços de cigarro da Califórnia), afim de realizar comparações entre as duas séries:
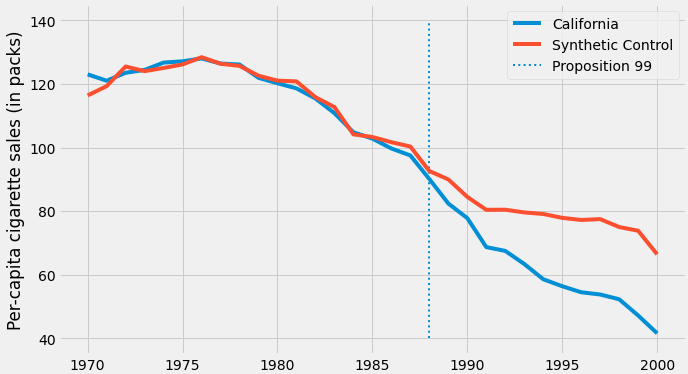
Antes da intervenção podemos ver que a Califórnia e a unidade sintética tiveram trajetórias bem semelhantes, o que acaba validando a sua construção.
Porém, após a intervenção, houve uma queda mais acentuada da linha azul o que sugere que a política foi efetiva em reduzir o consumo de cigarros.
Sendo assim, a diferença entre as duas séries seria o impacto da Proposição 99 na venda de tabaco
Controle Sintético Com Regressão Linear
Nessa altura do campeonato eu posso fazer o seguinte questionamento:
Qual recurso da matemática podemos utilizar para construir combinações lineares ponderadas e que se encaixa como uma luva no controle sintético?
Se você pensou em Regressão Linear, acertou!!
Os coeficientes da regressão fornecem os pesos para cada grupo de controle. Isso possibilita que, no período após a intervenção, os coeficientes ajustados sejam usados para estimar o comportamento contrafactual do grupo tratado.
No período antes da intervenção, considere a expressão da regressão linear dada por:

É com esta expressão que treinaremos o nosso modelo.
Sendo que o objetivo é encontrar os coeficientes beta que minimizem o erro quadrático a seguir:

Antes da intervenção:
Em seguida, o modelo ajustado será utilizado para realizar previsões antes da intervenção. O resultado do predict será:
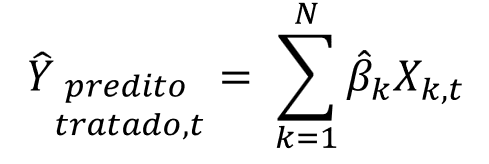
Estas previsões devem ser próximas dos valores do grupo tratado antes da intervenção.
Após a intervenção:
Com o mesmo modelo ajustado, o predict é aplicado para o período após a intervenção. Isso cria o comportamento contrafactual do grupo tratado:
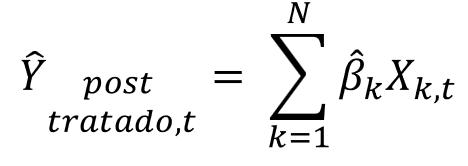
Neste caso, os valores do grupo de controle após a intervenção são utilizados para entender o que teria acontecido com o grupo tratado se o evento não tivesse ocorrido.
Assim, o impacto do evento seria obtido pela diferença entre o real e o contrafactual:
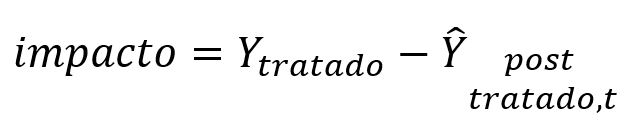
Vamos para a prática?!!
Aplicação Prática
Para a aplicação prática vamos utilizar o dataset Rossmann Store Sales, que contém informações históricas de vendas diárias de mais de 1.100 lojas, abrangendo fatores como promoções, sazonalidade, feriados e características específicas de cada loja.

Ele será utilizado para demonstrar como a metodologia de controle sintético pode ser aplicada na análise de intervenções e inferência causal.
De início, vamos importar as bibliotecas:
# Importando biblioteca para manipulação de dados
import pandas as pd
# Importando biblioteca para manipulação algébrica
import numpy as np
import warnings
warnings.filterwarnings("ignore")
# Importando biblioteca para análise exploratória
import matplotlib.pyplot as plt
# Importando a Regressão Linear
from sklearn.linear_model import LinearRegressionAgora vamos carregar os dados disponíveis:
# Carregar os datasets fornecidos
train_data = pd.read_csv('train.csv')
store_data = pd.read_csv('store.csv')Usando o método .head() podemos ver as primeiras linhas do dataset train_data:
E também do dataset store_data:

Manipulando a base train_data, vemos que a Loja 983 começou a operar em 2013–01–01:

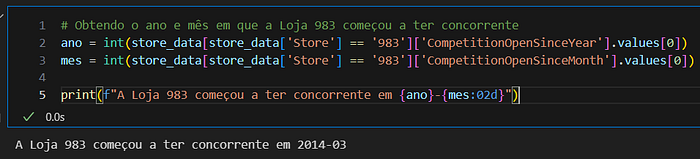
E manipulando a base store_data, vemos que a Loja 983 começou a ter um concorrente próximo em 2014–03:
E também que este concorrente se localizava a apenas 40 metros de distância:

Sendo assim, podemos pensar nas seguintes perguntas:
Qual o efeito da concorrência no desempenho das vendas da Loja 983?
O que teria acontecido com as vendas da Loja 983 se a abertura da concorrência não tivesse se concretizado?
Mas antes de aplicar a metodologia de controle sintético, precisamos organizar os dados para que a unidade tratada e o grupo de controle sejam claramente identificados.
- Definição da unidade tratada: Os dados referentes à Loja 983, que será analisada como a unidade tratada, são extraídos para análise.
- Seleção do grupo de controle:
- São excluídos os dados da Loja 983.
- Como critério adicional, podemos considerar o grupo de controle composto apenas pelas lojas localizadas a menos de 100 metros dos concorrentes (com base na variável
CompetitionDistancepresente no conjunto de dados store_data).
# Filtrando as colunas relevantes do dataset de treinamento
train_data = train_data[['Store','Date', 'Sales']]
# Convertendo a coluna 'Date' para datetime e definir como índice
train_data['Date'] = pd.to_datetime(train_data['Date'])
# Garantindo que a coluna 'Store' seja tratada como string
train_data['Store'] = train_data['Store'].astype(str)
store_data['Store'] = store_data['Store'].astype(str)
# Filtrando os dados para a loja tratada (Loja 983)
treated_store_data = train_data[train_data['Store'] == '983']
# Iniciando a criação da unidade de controle
unit_control_aux_1 = train_data[(train_data['Store'] != '983') & (train_data['Store'].isin(store_data[store_data['CompetitionDistance'] < 100]['Store']))]No caso deste exemplo, as vendas são representadas de forma diária. Vamos realizar uma agregação (soma) para representá-las por semana (a cada 7 dias:
# Criando uma matriz de vendas para as unidades de controle, com cada coluna representando uma loja e linhas representando datas agregadas a cada 7 dias
unit_control_aux_1_matrix = unit_control_aux_1.pivot(index='Date', columns='Store', values='Sales').resample('7D').sum()
# Agregando as vendas para a Loja 983 para a cada 7 dias
treated_sales_series = treated_store_data.set_index('Date')['Sales'].resample('7D').sum()Mas perceberam que ainda falta um detalhe na nossa unidade de controle?!
Precisamos manter somente as lojas que não possuem concorrente!!
# Identificando as lojas sem competidores com base em valores ausentes nas colunas relacionadas à competição
no_competition_stores = store_data[store_data['CompetitionDistance'].isna() |
store_data['CompetitionOpenSinceMonth'].isna() |
store_data['CompetitionOpenSinceYear'].isna()]['Store']
# Da unit_control_aux_1_matrix, são identificadas as lojas que não possuem competidores
valid_no_competition_stores = unit_control_aux_1_matrix.columns.intersection(no_competition_stores)
# Filtrando a unidade de controle para incluir apenas as lojas sem competidores
unit_control = unit_control_aux_1_matrix[valid_no_competition_stores]Para facilitar a visualização e a identificação de variações entre as séries, vamos alinhar as datas da unidade de controle e da unidade tratada. Nesse caso, dados nulos serão substituídos pela mediana da distribuição.
Além disso, para efeitos de comparação, vamos utilizar a média de todas as lojas da unidade de controle para criar uma série agregada que represente o comportamento médio das lojas não tratadas.
# Alinhar as datas para focar no mesmo período para a matriz de controle e séries tratada
aligned_dates = unit_control.index.intersection(treated_sales_series.index)
# Extrair a matriz de vendas alinhada para o período
X_sales = unit_control.loc[aligned_dates].fillna(unit_control.median())
X_sales_mean = X_sales.mean(axis=1)
# Usar apenas a série de vendas da loja tratada como variável de interesse (variável dependente)
y_sales = treated_sales_series.loc[aligned_dates]Sendo assim, podemos plotar em gráficos de linha as duas séries, aproveitando para inserir em linha tracejada a indicação da intervenção:
# Definir a data de intervenção
intervention_date = pd.to_datetime("2014-03-01")
plt.figure(figsize=(12, 6))
plt.plot(y_sales.index, y_sales, label="Loja Tratada - Loja 983", color='blue')
plt.plot(X_sales_mean.index, X_sales_mean, label="Lojas Sem Concorrência", color='red', linestyle='--')
plt.axvline(x=intervention_date, color="gray", linestyle=":", lw=2, label="Chegada da Concorrência na Loja 983")
plt.xlabel("Data")
plt.ylabel("Vendas")
plt.title("Gap nas vendas da Loja 983 e Lojas Sem Concorrência")
plt.legend()
plt.show()Originando a representação gráfica a seguir:
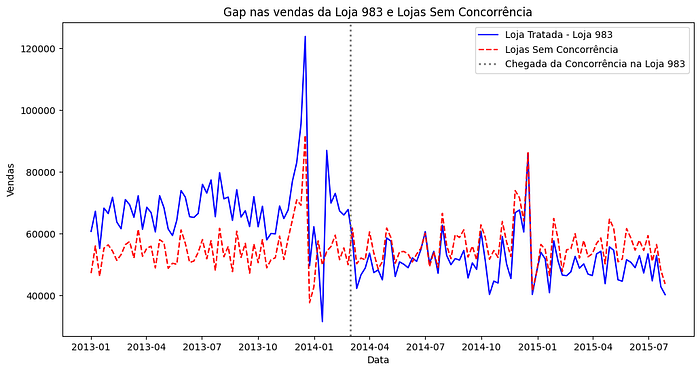
Analisando o gráfico acima podemos destacar os seguintes pontos:
Comportamento pré-intervenção (antes de 2014–06–01):
- Podemos observar que as vendas da Loja 983 são consistentemente mais altas do que a média das lojas do grupo de controle. Isso pode nos indicar que a Loja 983 tinha características particulares, como maior clientela ou estratégias de venda mais eficazes.
- Apesar disso, o padrão de sazonalidade parece ser similar entre as duas séries, com flutuações cíclicas alinhadas.
Impacto da intervenção (chegada da concorrência em 2014–06–01):
- Após a data de chegada da concorrência, há uma queda significativa nas vendas da Loja 983.
- Esse comportamento não é observado na média das lojas do grupo de controle, o que nos indica que a intervenção teve um impacto claro e local na Loja 983.
Gap nas vendas pós-intervenção:
- Após a chegada da concorrência, o gap entre as duas séries se torna bastante evidente. Enquanto as vendas do grupo de controle permanecem estáveis, as da Loja 983 estabilizam em níveis inferiores ao observado antes da intervenção.
- Essa diferença entre as séries pós-intervenção é uma evidência do efeito da concorrência, sugerindo que ela reduziu significativamente o desempenho da Loja 983.
O próximo passo seria ajustar uma Regressão Linear na unidade de controle (período pré-intervenção), para então criar a unidade sintética antes e depois da intervenção.
# Identificando as unidades de controle e tratada para antes e depois da intervenção
X_sales_before_intervention = X_sales.loc[X_sales.index <= '2014-03-01']
X_sales_after_intervention = X_sales.loc[X_sales.index > '2014-03-01']
y_sales_before_intervention = y_sales[y_sales.index <= '2014-03-01']
y_sales_after_intervention = y_sales[y_sales.index > '2014-03-01']
# Ajustando uma Regressão Linear para obter os pesos para cada loja na unidade de controle
linear = LinearRegression(fit_intercept=False)
linear.fit(X_sales_before_intervention, y_sales_before_intervention)
# Prevendo as vendas para o período antes e depois da intervenção
predicted_sales_before_intervention = linear.predict(X_sales_before_intervention)
predicted_sales_after_intervention = linear.predict(X_sales_after_intervention)
# Construindo a série predita completa para o controle sintético
synthetic_sales_series = pd.Series(
np.concatenate([predicted_sales_before_intervention, predicted_sales_after_intervention]),
index=X_sales.index
)Agora podemos plotar em gráficos o controle sintético e o comportamento da unidade tratada, identificando com uma linha tracejada o momento exato da intervenção:
# Definir a data de intervenção
intervention_date = pd.to_datetime("2014-03-01")
plt.figure(figsize=(12, 6))
plt.plot(y_sales.index, y_sales, label="Loja Tratada (Vendas) - Loja 983", color='blue')
plt.plot(synthetic_sales_series.index, synthetic_sales_series, label="Controle Sintético (Vendas)", color='red', linestyle='--')
plt.axvline(x=intervention_date, color="gray", linestyle=":", lw=2, label="Chegada da Concorrência")
plt.xlabel("Data")
plt.ylabel("Vendas")
plt.title("Análise de Controle Sintético para a Loja 983 (Vendas)")
plt.legend()
plt.show()Originando a representação gráfica a seguir:
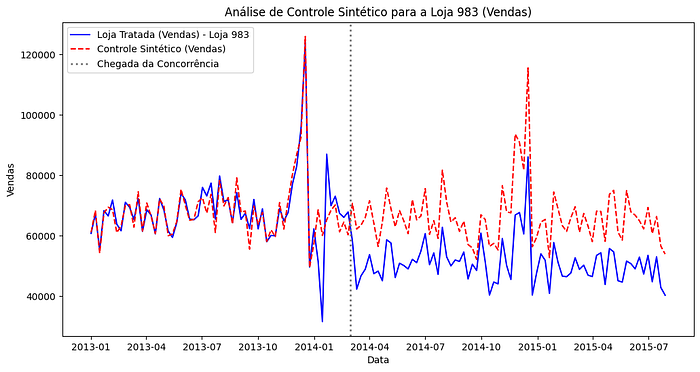
Sobre o gráfico acima, podemos perceber que:
Período pré-intervenção (antes de 2014–06–01):
- O controle sintético acompanha de maneira muito próxima o comportamento da Loja 983 antes da chegada da concorrência.
- Essa proximidade valida a construção do controle sintético como uma boa representação contrafactual da Loja 983, ou seja, como a Loja 983 teria se comportado na ausência de concorrência.
Impacto da intervenção (a partir de 2014–06–01):
- Após a chegada da concorrência, as vendas da Loja 983 caem significativamente, enquanto o controle sintético mantém um padrão semelhante ao período pré-intervenção.
- Essa divergência indica que a chegada da concorrência teve um impacto negativo significante nas vendas da Loja 983.
Efeito da intervenção:
- A diferença entre as duas séries (unidade tratada e controle sintético) no período pós-intervenção pode ser interpretada como o efeito estimado da chegada do concorrente.
- Além disso, podemos ver que esse efeito parece ser persistente ao longo do tempo, reforçando que a intervenção alterou permanentemente o desempenho da Loja 983.
Validade do controle sintético:
- Podemos concluir que a boa aderência entre a unidade tratada e o controle sintético antes da intervenção indica que o modelo conseguiu capturar adequadamente as características principais da Loja 983 com base nas lojas de controle.
- Isso aumenta a confiança nos resultados da análise, já que a divergência pós-intervenção pode ser atribuída com maior certeza à chegada da concorrência.
Conclusão
Neste artigo, vimos que o controle sintético se apresenta como uma poderosa ferramenta para avaliar o impacto de intervenções reais, nos permitindo isolar efeitos causais mesmo em cenários onde experimentos controlados não são viáveis.
Discutimos o conceito, a metodologia e sua aplicação prática, destacando como essa abordagem pode oferecer insights valiosos para a tomada de decisão em diferentes contextos, como negócios, políticas públicas e economia.
Ainda não me segue no Medium? Aproveite e me siga para ficar sabendo toda vez que sair um artigo novo do forninho!!
LinkedIn: https://www.linkedin.com/in/edson-junior/
GitHub: https://github.com/ejunior029
Referências
1 — Livro: Causal Inference for The Brave and True, Matheus Facure

