Lakehouse Data Platform on Kubernetes
Introduction
The idea of a data lakehouse is rapidly becoming more popular, marking a significant departure from the conventional data warehouses that have been a staple of businesses for decades. Essentially, a data lakehouse merges the best of both worlds: it brings together the expansive storage capacity and agility of data lakes with the orderly structure and governance capabilities characteristic of data warehouses. This fusion not only addresses the limitations inherent in each approach when used in isolation but also leverages their strengths to create a more flexible, scalable, and efficient data management solution.
Building such a modern, cloud-native lakehouse platform is not only possible but has been made more accessible through the use of open-source technologies. Throughout this article, we will explore the intricacies of a data lakehouse platform, emphasizing how it simplifies the transition to and utilization of data lakehouses. We will also provide a comprehensive guide on constructing an entire data lakehouse ecosystem on Kubernetes, highlighting the steps and strategies involved in leveraging this powerful container-orchestration system to deploy and manage a highly scalable and resilient data platform.
Understanding Lakehouse Platform
To grasp the transformative impact of data lakehouse platform, it is crucial to start with a clear definition of what constitutes a data lakehouse. This innovative architectural design revolutionizes how we approach the storage, management, and analytical processing of an extensive range of data types, both structured and unstructured. By leveraging a suite of loosely coupled components, a data lakehouse effectively replicates the functionalities traditionally reserved for data warehouses, but does so directly atop your data lake. This architecture dismantles the conventional constraints associated with data warehouses, which typically function within restrictive silos, and ushers in a unified, adaptable framework for data management.
On one side of analytics landscape, there are data warehouses that come with rigid structures but limited in terms of expandability. Data warehouses are crafted for specific analytic tasks and usually necessitate that incoming data be transformed and conformed to a predetermined schema prior to its utility. On the other side of landscape, there are data lakes representing expansive silos of unrefined data maintained in their original format that come with remarkable scale yet frequently deficient in systematic governance and orderly arrangement.
Embarking on a synthesis of these two paradigms, the data lakehouse architecture embodies the optimal synthesis. First, it enables the storage of colossal volumes of raw data akin to a data lake’s capacity. Second, it takes advantage of organizational schema and analytical tool-sets characteristic of a data warehouse. This modular strategy signifies that each constituent element — encompassing data storage mechanisms, the structure of data files, the format of tables, cataloging systems, and computational resources — is fashioned as an independent, modular entity. This architecture thereby guarantees enhanced adaptability and scalability, redefining the landscape of data management and analysis.
Understanding the Architecture
The following shows the high level architecture of lakehouse platform built on Kubernetes.

The process of creating and improving a lakehouse data platform on Kubernetes has involved combining several technologies: Alluxio is used for speeding up data access, Trino helps with running analytical queries, Debezium captures changes in data as they happen, Iceberg is used for organizing the data in tables, and Cube helps by storing the results of queries to speed up future access. Each of these parts is crucial for building a strong, scalable, and effective data platform that can handle real-time analytics and help make decisions based on large amounts of data.
In the upcoming sections, we will focus on each component.
Caching with Alluxio
Alluxio is an open-source data orchestration platform designed to accelerate data access in complex, multi-tiered storage environments. It introduces a virtual layer that sits between computation frameworks and storage systems, enabling faster data retrieval without repeated reads from the underlying storage. This is particularly beneficial in a lakehouse setup where data is frequently accessed by various compute engines for analytics and machine learning tasks.
In a lakehouse architecture, data resides in a data lake stored in an object storage system such as AWS S3, which is designed for high durability and scalability but not necessarily for speed. Alluxio complements this by providing a caching layer that keeps frequently accessed data closer to the computation engines, dramatically reducing latency and improving query performance. This setup ensures that data can be processed at higher speed, enabling real-time analytics and insights.
Alluxio’s ability to cache data from AWS S3 brings several advantages. First, it reduces egress costs by minimizing the amount of data read repeatedly from S3. Second, it provides a unified view of data stored across different environments (AWS, Azure, GCP), simplifying data management and access. By leveraging Alluxio’s tiered storage, data can be stored across multiple media types, from high-speed RAM to slower, disk-based storage, ensuring optimal performance based on access patterns.
Below is the high level architecture of Alluxio [taken from Alluxio’s docs]:

Kubernetes enhances Alluxio’s capabilities by enabling various replication strategies that ensure high availability and fault tolerance. Data cached in Alluxio can be replicated across multiple Kubernetes nodes, safeguarding against node failures and ensuring that data is always accessible when needed. This replication not only enhances data durability but also allows for scalable data access across the cluster.
Deploying Alluxio on Kubernetes offers a seamless way to integrate this caching layer into your data platform. Kubernetes’ orchestration capabilities ensure that Alluxio can dynamically scale based on demand, providing efficient resource utilization and maintaining high performance. The configuration involves setting up Alluxio as a Daemonset within Kubernetes, allowing it to benefit from persistent storage options and makes sure objects are replicated on different nodes.
Setting up Alluxio on Kubernetes
Will use the following configuration with Alluxio helm chart:
properties:
alluxio.master.mount.table.root.ufs: s3://BUCKET_FOR_LAKEHOUSE/ufs
alluxio.security.authentication.type: NOSASL
alluxio.security.authorization.permission.enabled: false
alluxio.user.file.writetype.default: ASYNC_THROUGH
alluxio.user.file.replication.durable: 2
alluxio.user.file.replication.min: 2
alluxio.user.ufs.block.read.location.policy: alluxio.client.block.policy.DeterministicHashPolicy
master:
enabled: true
properties:
alluxio.master.metastore: ROCKS
alluxio.master.metastore.dir: /metastore
journal:
volumeType: persistentVolumeClaim
storageClass: "ebs-csi-gp3"
size: 2Gi
metastore:
volumeType: persistentVolumeClaim
size: 2Gi
mountPath: /metastore
storageClass: "ebs-csi-gp3"
accessModes:
- ReadWriteOnce
shortCircuit:
enabled: true
policy: local
tieredstore:
levels:
- level: 0
alias: MEM
mediumtype: MEM
path: /dev/shm
type: emptyDir
high: 0.95
low: 0.7
quota: 3Gi
- level: 1
alias: SSD
mediumtype: SSD
path: /opt/alluxio-data-store
type: emptyDir
high: 0.95
low: 0.7
quota: 30GiExplanation:
- We use
ASYNC_THROUGHreplication for persisting to S3. This might look dangerous in terms of data loss. However, it's not an issue because we synchronously replicate files in Alluxio. - For the sake of simplicity, authentication is disabled using
alluxio.security.authentication.type: NOSASL alluxio.user.file.replication.min: 2andalluxio.user.file.replication.durable: 2helps to reduce the chance of data loss by replicating data within Alluxio deployment (rememberASYNC_THROUGHis used for S3 persistence). In order to ensure data is safely stored on multiple nodes (before S3 persistence), in-cluster replication is utilized.- A local cache hit occurs when the requested data resides on the local Alluxio worker. If the data is locally available, the Alluxio client uses a short-circuit read to bypass the Alluxio worker and read the file directly via the local file system.
- We are using two tier cache: memory and SSD. Once memory tier is filled, it will be offloaded to SSD.
Introducing Iceberg Table Format
As organizations navigate the complexities of big data management, the Apache Iceberg table format has emerged as a transformative solution, addressing longstanding challenges associated with traditional data lake file formats. Iceberg, an open-source table format, is engineered for high-performance, large-scale data analytics, offering features like schema evolution, transactional support, and efficient querying.
Apache Iceberg is designed to improve data reliability, performance, and scalability in data lakes. Unlike conventional file formats that struggle with complexities such as schema evolution and table management, Iceberg provides a more structured approach to data storage and access. It treats data lakes as first-class citizens, bringing the capabilities of traditional database management systems to the flexibility and scale of data lakes.
Key features of Iceberg:
- Schema Evolution: Iceberg supports adding, renaming, deleting, or updating fields without disrupting ongoing queries, ensuring data consistency and compatibility across different versions of a dataset.
- Hidden Partitioning: It abstracts the complexity of partitioning from users, automatically optimizing how data is stored and accessed based on the query patterns, without the need for explicit partition management.
- Snapshot Isolation: Iceberg maintains snapshots of data, enabling consistent views of data at any point in time and supporting rollbacks, auditing, and concurrent writes and reads without locking.
- Incremental Processing: The format allows for efficient incremental data processing, enabling systems to process only new or modified data since the last computation, significantly reducing the computational load.
- Efficient File Management: Iceberg optimizes file size and layout based on access patterns, reducing the overhead of small files and improving query performance by organizing data into logically related files.
Above features are achieved by re-using files that has not been modified in a transaction as depicted below [taken from Iceberg’s docs]
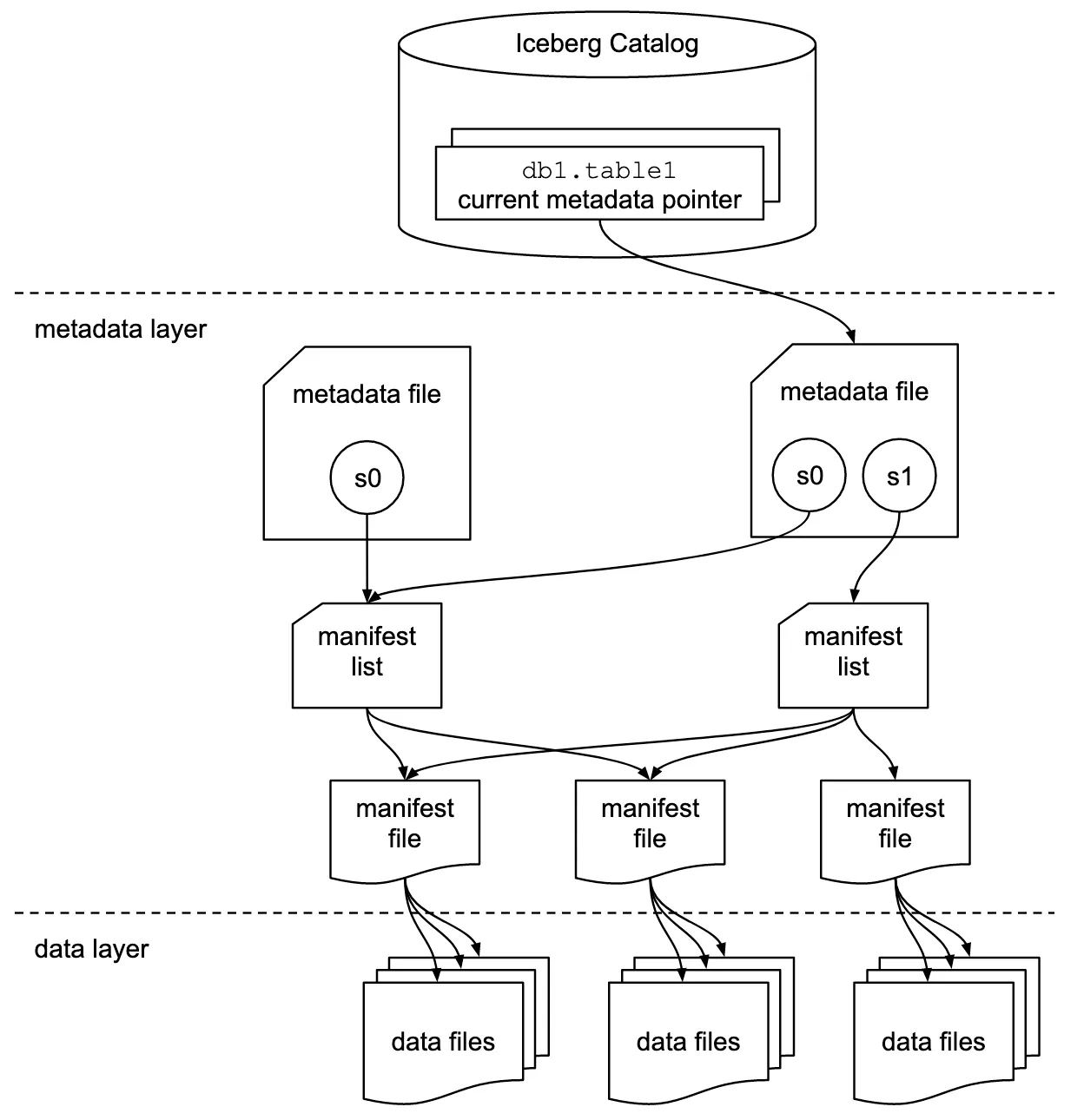
The Iceberg table format is a cornerstone in the lakehouse architecture, bridging the gap between data lakes and warehouses. It enables the lakehouse to support transactional workloads and complex analytical queries with ease, making it possible to run operational and analytical workloads on the same platform. This convergence simplifies data infrastructure and management, reducing costs and increasing agility.
Integrating Iceberg into a data platform transforms how data is managed and queried. By adopting Iceberg, organizations can leverage its advanced features within their existing data lakes, avoiding the need to move data into proprietary data warehouses for advanced analytics. This integration typically involves setting up Iceberg tables on top of existing data storage solutions like HDFS or cloud object stores (e.g., AWS S3), allowing for a smooth transition and immediate gains in performance and manageability.
Introducing CDC and Debezium
CDC (Change Data Capture) is a method used to capture and replicate changes made to the data in databases, such as inserts, updates, and deletes, and then apply these changes to a target system in real-time or near-real-time. This approach allows businesses to react swiftly to data changes, feeding fresh data into analytics platforms, search indexes, or data lakes without the need for bulk data loads, which can be resource-intensive and disruptive. CDC minimizes the overhead on source systems and ensures that data in target systems is up-to-date, enabling real-time analytics and decision-making.
Debezium, an open-source distributed platform, stands out as a robust solution for implementing CDC, especially within Kubernetes environments. Debezium is designed to tap into the database’s replication log (or transaction log) to capture changes as they occur. This ensures that data in the target system is always consistent with the source, without imposing a significant load on the source database. Debezium’s distributed nature makes it highly scalable and fault-tolerant, qualities that are essential in a Kubernetes-based data architecture.
Debezium is typically used in conjunction with Apache Kafka, where it captures changes and publishes them as events to Kafka topics. This combination leverages Kafka’s robust messaging and stream processing capabilities to distribute, store, and process change events. By connecting Debezium to Kafka, developers can build complex data pipelines that filter, aggregate, and transform data streams for a wide range of use cases, from real-time analytics to machine learning model training.
In the following section we assume you have already setup Strimzi in your Kubernetes cluster.
Configuring Debezium Source Connector
The following shows a sample example a debezium source connector:
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: source-mysql-connector
labels:
strimzi.io/cluster: cdc-connect-cluster
spec:
class: io.debezium.connector.mysql.MySqlConnector
tasksMax: 1
config:
tasks.max: 1
database.hostname: DB_SERVICE_NAME
database.port: 3306
database.user: DB_DBZ_USER
database.password: DB_DBZ_PASSWORD
database.include.list: DB_NAME
database.server.name: source_mysql
snapshot.mode: when_needed
snapshot.locking.mode: none
database.ssl.mode: disabled
transforms: unwrap
transforms.unwrap.type: io.debezium.transforms.ExtractNewRecordState
transforms.unwrap.add.fields: op,table,source.ts_ms,db
transforms.unwrap.add.headers: db
transforms.unwrap.delete.handling.mode: rewrite
transforms.unwrap.drop.tombstones: true
database.allowPublicKeyRetrieval: true
include.schema.changes: false
schema.history.internal.kafka.topic: source-mysql-history-topic
schema.history.internal.kafka.bootstrap.servers: KAFKA_BOOTSTRAP_ADDRESSThis is a fairly standard Debezium configuration. However, the most important part is ExtractNewRecordStateSMT.
- Debezium captures before state and after state of the transaction.
- Using this SMT we only pick the after state.
- Then it inserts four metadata field which we will use with Iceberg.
opdefines the operation on the record (insert, delete, update, ...)tabledefines the table name.source.ts_mstimestamp of the operation defined in MySQL binlog.dbdefines database name.
It will become clear why we need these metadata field once we use IcebergSink connector. For Iceberg we use getindata Iceberg sink implementation.
apiVersion: kafka.strimzi.io/v1beta2
kind: KafkaConnector
metadata:
name: iceberg-debezium-sink-connector
labels:
strimzi.io/cluster: cdc-connect-cluster
annotations:
strimzi.io/restart: "true"
spec:
class: com.getindata.kafka.connect.iceberg.sink.IcebergSink
tasksMax: 1
config:
topics: INPUT_TOPIC
table.namespace: "k8s_lackehouse"
consumer.override.max.poll.records: 2000
table.auto-create: true
table.write-format: "parquet"
iceberg.catalog-impl: "org.apache.iceberg.aws.glue.GlueCatalog"
iceberg.warehouse: "alluxio://alluxio-master-0:19998"
iceberg.io-impl: "org.apache.iceberg.hadoop.HadoopFileIO"
iceberg.fs.alluxio.impl: "alluxio.hadoop.FileSystem"
iceberg.alluxio.master.rpc.addresses: "alluxio-master-0:19998"Explanation:
- Since we were using EKS, we stick to
GlueCatalog. However, other catalogs can be used. - Instead of directly pointing to S3, we point sink connector to Alluxio master.
iceberg.warehouse: "alluxio://alluxio-master-0:19998"defines the endpoint of Alluxio master within Kubernetes.iceberg.fs.alluxio.impl: "alluxio.hadoop.FileSystem"defines Alluxio file system implementation which transparently forwards read/write requests to Alluxio workers. Alluxio provides Hadoop compatible interface.
Note that above configuration assumes Alluxio jars are in the plugin subdirectory of connect cluster:
- Extend Strimzi connect image and add Alluxio dependencies.
- Let Strimzi download maven dependencies while building the image.
Refer to Strimzi docs in order to properly implement this for production. This article by Strimzi team provides great detail on this.
Querying with Trino
Trino emerges as a highly efficient and flexible distributed SQL query engine, designed for interactive analytics across large datasets. When integrated within a lakehouse architecture, especially one that utilizes the Iceberg table format, Trino’s capabilities are significantly enhanced. A pivotal enhancement is Trino’s ability to interface with Alluxio, a powerful caching layer that optimizes data access from object storage systems like AWS S3.
The integration of Trino with Alluxio brings forth a synergistic effect that substantially reduces query times on data stored in S3. Alluxio serves as an in-memory cache that serves frequently accessed data. When Trino queries are executed, they can retrieve cached data from Alluxio instead of directly accessing the slower object storage. This not only speeds up query execution but also reduces costs associated with data transfer from cloud storage services.
When Trino queries data, Alluxio checks its cache for the requested data blocks. If present, data is served directly from Alluxio’s cache, significantly reducing the I/O latency compared to fetching data from AWS S3. For data not in the cache, Alluxio efficiently retrieves and caches it for future access, ensuring subsequent queries are accelerated. This mechanism is particularly effective for analytics workloads that involve repeated access to the same datasets, as the initial query populates the cache, and subsequent queries benefit from the cached data.
The ability of Trino to leverage cached data from Alluxio transforms the analytics landscape, enabling real-time or near-real-time data analysis. Organizations can now run complex analytical queries across their data lakes without the traditional latency penalties associated with accessing data stored in object storage. This capability is crucial for time-sensitive decision-making processes and enhances the overall agility of data-driven organizations.
Configuring Trino with Alluxio
In order to create Trino table, we need to use Iceberg connector. However, we need to point it to Alluxio’s master endpoint which transparently forwards the requests to AWS S3.
CREATE TABLE iceberg.k8s_lackehouse.person(
id bigint,
name varchar,
created_at timestamp,
__op varchar,
__deleted boolean,
__source_ts_ms bigint,
__table varchar
)
WITH (
format = 'ORC',
location = 'alluxio://alluxio://alluxio-master-0:19998/k8s_lackehouse/person'
partitioning = ARRAY['day(__source_ts_ms)']
);Explanation:
locationparameter refers to Alluxio master. Trino already comes with Alluxio dependencies. Refer to documentation for more detail.- Four metadata columns are added by Debezium SinkConnector which helps in the ETL process down the line.
__deleteddefines when the record is deleted.
The combination of these metadata columns can be used by ELT pipelines to merge newly arrived data into cleaned up tables.
SELECT id, name, created_at, __op, __deleted, __source_ts_ms, __table
FROM iceberg.k8s_lackehouse.person
WHERE __source_ts_ms >= unix_timestamp('2024-01-01', 'yyyy-MM-dd') * 1000Which would produce a sample output like below:
| id | name | created_at | __op | __deleted | __source_ts_ms | __table |
|----|------------|---------------------|------|-----------|-------------------|------------|
| 1 | John Doe | 2024-01-01 08:00:00 | 'c' | false | 1641024000000 | 'person' |
| 2 | Jane Smith | 2024-01-01 09:15:00 | 'u' | false | 1641028500000 | 'person' |You need to make sure compaction jobs are run regularly to remove delta files generated during update and delete operations. Refer to Iceberg’s doc for maintenance operation.
Last Mile Cache With Cube
As businesses increasingly rely on real-time insights to inform decision-making, the integration of advanced caching solutions like Cube into their data architecture becomes critical. Cube, standing at the forefront of query acceleration and caching, offers a sophisticated layer designed to store the results returned by Trino, thus serving as an efficient last-mile cache which enhances the accessibility and performance of data for BI tools and dashboards.
Cube’s integration with Trino brings forth several compelling advantages. First, Cube caches query results, significantly reducing the load on Trino and speeding up the response time for frequently executed queries. It efficiently handles spikes in query load, ensuring that dashboards and BI tools operate smoothly, even under heavy usage. By reducing the number of queries executed against Trino, Cube helps in lowering operational costs associated with computational resources. Cube supports a wide array of BI tools (since it exposes all data sets via standard JDBC protocol plus REST and GraphQL API), offering seamless integration capabilities and thus, broadening the choice of analytics tools for organizations.
Additionally, it’s possible to build data model in Cube. It uses Javascript or Yaml to build data model. Refer to Cube’s docs for more information on data modelling. Here is a sample based on previously defined table in Trino:
cube(`person`, {
dataSource: 'trino',
sql: `SELECT * FROM k8s_lackehouse.person`,
dimensions: {
person_id: {
sql: `id`,
type: `number`,
primaryKey: true,
shown: true
},
name: {
sql: `name`,
type: `string`
},
created_at: {
sql: `lastname`,
type: `time`
}
},
measures: {
person_count: {
type: `count`
}
},
});measures section defines aggregates that will be performed and cached by Cube’s workers.
Conclusion
The journey through building and optimizing a lakehouse data platform on Kubernetes has traversed the integration of several cutting-edge technologies: Alluxio for caching, Trino for SQL querying, Debezium for change data capture (CDC), Iceberg as the table format, and Cube for last-stage query result caching. Each component plays a pivotal role in creating a robust, scalable, and efficient data ecosystem capable of supporting real-time analytics, machine learning, and data-driven decision-making at scale.
The orchestrated combination of Kubernetes, Alluxio, Trino, Debezium, Iceberg, and Cube represents a comprehensive approach to building a data platform that is not only scalable and resilient but also capable of delivering high-performance data processing and analytics. This architecture leverages the strengths of each component to address specific challenges in data management and analysis, from ingestion and storage to querying and caching. By carefully integrating these technologies, organizations can achieve a level of agility and insight previously unattainable, unlocking new opportunities for innovation and growth in an increasingly data-driven world.
