탈중앙화 AI 톺아보기 (하)
Disclaimer: 본 글은 서울대학교 블록체인 학회 디사이퍼(Decipher)의 Weekly Session에서 탈중앙화 AI를 주제로 발표한 내용을 기반으로 작성되었습니다. 해당 글은 탈중앙화 AI에 대한 전반적인 내용을 바탕으로 작성자의 주관적인 의견을 포함하여 작성하였으며, 본 글에 포함된 어떠한 내용도 투자 조언이 아님을 명시합니다. 이에 따라 본 글의 어떠한 내용도 투자 조언으로 해석되어서도 안 됩니다.

시리즈
- 탈중앙화 AI 톺아보기 (상)
- 탈중앙화 AI 톺아보기 (하)
Author
이현우(@LHW0803), Vlad(@CosmicDude3000) of Decipher
Seoul Nat’l Univ. Blockchain Academy Decipher(@decipher-media)
Reviewed By 신성헌, 박순종, 최재우
목차
- 블록체인을 이용한 문제 해결
1.1. DePIN for the data
1.2. Verifiable ML
2. 블록체인에 적용 가능한 AI 기술
3. 결론
1. 블록체인을 이용한 문제 해결
1.1. DePIN for the data
1.1.1. 기존 문제 recap
전체 모델을 구성하는데 있어 가장 중요하고 어려운 파트라고 볼 수 있는 부분이 바로 모델에 필요한 유의미한 데이터의 수집과 처리입니다. 기존 중앙화된 데이터 수집 및 처리 과정에서의 문제점은 다음과 같이 요약할 수 있습니다:
- 출처가 불분명한 데이터, 데이터 poisoning 공격 등으로 인한 데이터의 부정확함과 편향 가능성
- 데이터 수집 과정에서 요구되는 막대한 비용 및 데이터 수집자의 IP 검열 가능성
아무리 모델의 구조가 잘 짜여져 있고, 엄청난 수의 파라미터를 이용하여 학습시킨다고 해도, 출처가 불분명하고, 편향된 데이터를 학습하여 만들어진 모델은 잘못된 추론 결과를 제공해줄 수 있습니다.
1부에서 서술된 것처럼, 아마존 채용을 위한 서류 평가에서 여성에게 불이익을 준 사례와 더불어, 구글의 이미지 인식 알고리즘에서 흑인을 고릴라로 식별한 사례, 중국 WeChat의 텍스트 번역 과정에서 흑인을 비하하는 N-Word를 사용한 사례 등은 학습 과정에서 올바른 데이터 사용의 중요성을 보여줍니다.
아래 사진에서 볼 수 있듯이, 최근 인공지능 모델을 통해 재생산되는 데이터들이 기하급수적으로 증가하는 추세이며, 10년 후에는 지금의 10배 이상의 새로운 데이터들이 AI 모델을 통해 생성될 것으로 예상하고 있습니다. 여기서 문제는 잘못 학습된 모델에서 파생되는 정보들은 편향을 지니거나 부정확한 데이터가 되며, 이러한 데이터들이 연쇄적으로 생겨날 수 있다는 점입니다. 학습을 위한 가치있는 데이터를 수집하는 것이 점점 어려워지고 있다는 것을 의미합니다.

또한 아래 사진에서 볼 수 있듯, 웹 서버가 데이터 센터의 IP 주소와 같은 특정 IP 주소를 제한할 수 있습니다. 레딧의 api 가격 인상이나 트위터의 웹 스크래핑 방지를 위한 표시 트윗 제한과 같은 예시는 데이터의 가치 상승과 더불어, 데이터 수집을 위한 초기 비용의 증가를 의미합니다.

블록체인은 이러한 중앙화된 데이터 수집 및 처리 과정에서의 문제를 데이터를 위한 DePIN(Decentralized Physical Infrastructure Network)을 구축하여 해결하고자 합니다. DePIN을 간단히 정리하면, 실세계의 물리적인 인프라의 소유권을 탈중앙화하고, 물리적 인프라 제공에 대한 합당한 Web 3 토큰 보상을 제공하는 네트워크로 요약할 수 있습니다.
DePIN을 이용하면 모든 정보가 투명하게 공개되는 블록체인을 이용하여, 수집한 데이터의 출처를 명확하게 표현할 수 있습니다. 또한, 데이터 수집 단계나 처리 단계를 분산화하여 검열을 회피하고, 보상으로 토큰을 활용하는 Web3 인센티브 시스템을 구축하여 데이터 수집 및 처리 과정에서의 비용을 최소화 할 수 있습니다.
1.1.2. Grass — 데이터 수집을 위한 DePIN
데이터 DePIN의 대표적인 프로젝트로 Grass가 있습니다. Grass는 토큰 보상을 바탕으로 Grass Node들의 IP와 네트워크 대역폭을 빌려 데이터를 수집하게 해서, 데이터 수집 과정에서의 검열을 회피하고, 비용을 최소화하고자 합니다. 또한 수집된 데이터를 Grass Data Ledger에 저장할 때, 수집한 데이터의 출처를 같이 저장하고, 해당 사실을 온체인에 zkp로 게시해서, 수집한 데이터의 신뢰성을 높이고, 데이터 편향 문제도 해결하고자 했습니다.
Client(사용자)가 특정 웹 사이트의 데이터를 요구하면, 각 Grass Node들이 자신의 인터넷 연결 부분을 이용하여 해당 웹 사이트의 데이터를 크롤링하여 전달하고, 수집된 데이터는 클라이언트에게 전달되는 것과 동시에 데이터의 출처와 함께 Grass Data Ledger에 저장됩니다.
Solana L2라는 점이 특이하며, Grass 내에서 작업에 대한 증명을 Solana에 올려 Settle 합니다. 공식 문서 상으로는 데이터 수집 외에도 수집된 데이터를 전처리하고 판매하는 모든 부분에 Grass가 관여한다고 나와 있지만, 지금까지 공개된 정보로 볼 때, 아직까지 Grass에서 탈중앙화 하여 집중하는 부분은 데이터 수집뿐입니다.
Grass의 주요 참여 주체로는 Client, Grass Node, Validator, Router, Grass Data Ledger, ZK Processor가 있으며, 각각의 역할은 아래와 같습니다.
- Client: 특정 웹 서버의 데이터를 요청하는 사용자
- Grass Node: 목표 웹 서버의 암호화된 데이터를 수집하여 반환
- Validator: Grass Node가 수집한 데이터를 검증, zkp 생성
- Router: Validator와 Grass Node를 연결, Grass Node의 네트워크 상태 등을 보고
- Grass Data Ledger: 모든 데이터가 저장되는 장부
- ZK Processor: zkp를 Solana에 제출
Grass의 작동 방식
Grass의 전반적인 프로세스를 간단하게 나타내면 아래와 같습니다.
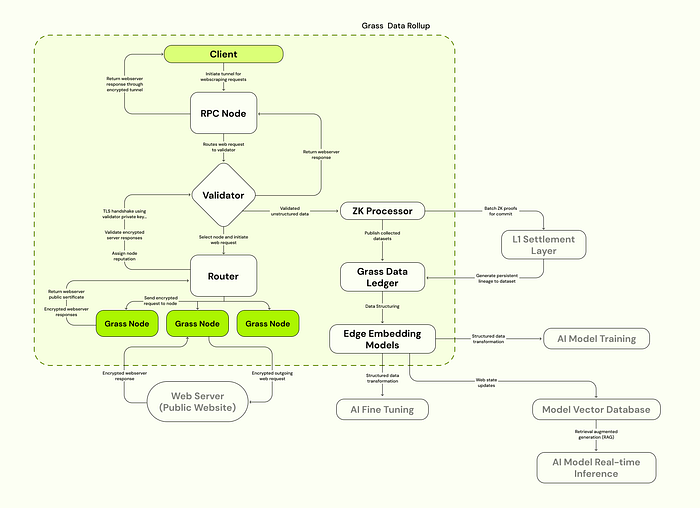
- Client가 특정 사이트들에 대한 데이터를 요청
- Validator가 작업을 수행할 Grass Node를 선정하고, Router에서 요청이 암호화되어 Grass Node들에게 전달
- 암호화된 서버 응답을 Grass Node들이 Validator에게 전달
- 전달된 데이터를 Validator가 검증하고, 노드의 신뢰도를 평가
- 데이터는 Validator의 세션 키로 해독되어 Client에게 전달
- 검증된 데이터는 ZK Processor에 전달되고, zkp를 L1에 제출 + Grass Data Ledger에 메타데이터와 데이터를 저장
- Grass 자체 In-house vertical인 Socrates에서 데이터를 전처리
탈중앙화에 관여하는 Grass Node들의 작업이 데이터 수집에만 집중된 것을 확인할 수 있습니다. 데이터 수집 과정이 암호화되어 데이터의 프라이버시를 지키며 진행되는 것으로 프로세스를 나타냈는데, 공식 문서 상에 언급된 데이터 수집 단계에 해당하는 1~3 과정을 조금 더 자세히 보면 아래와 같습니다.
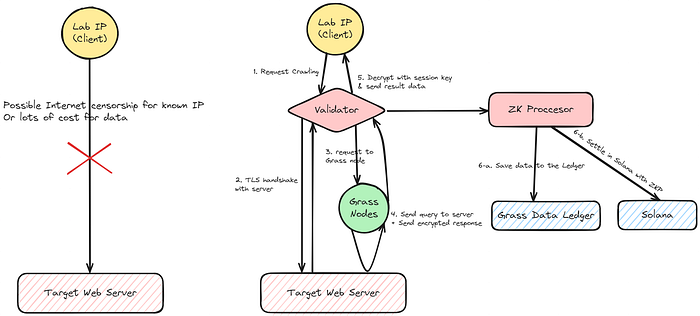
- Client가 특정 사이트들에 대한 데이터를 요청
- Validator가 해당 작업을 수행할 Grass Node들을 선정
- Validator가 타겟 웹 서버의 데이터를 송수신할 때, 선정된 Grass Node를 중계할 수 있도록 Grass Node에 요청
- Validator가 타겟 웹 서버와 TLS 핸드셰이크(Transport Layer Security Handshake)를 진행
- Grass Node는 Validator가 제공한 암호화된 패킷을 타겟 웹 서버에 전달하고, 암호화된 서버의 응답을 Validator에게 전달
여기서 TLS 핸드셰이크는 안전한 통신을 위해 클라이언트와 서버 간에 세션 키를 생성하는 과정입니다. 세션 키가 만들어지면, 이후 통신에서 데이터를 송수신 할 때, 세션 키를 이용하여 데이터가 암호화되어 전송됩니다. 따라서 통신 정보를 외부에 공개하지 않은 상태에서 데이터의 안전한 송수신이 가능해집니다.

각 Grass Node는 Validator가 요청한 암호화된 패킷을 타겟 웹 서버에 전달해주고, 암호화된 응답을 다시 Validator에게 전달해주는 중간 서버 역할을 하게 됩니다. 블록체인에서 중간 다리 역할을 하는 릴레이어 혹은, 클라이언트의 IP를 숨겨주고 통신하는 기능을 제공하는 VPN과 유사하게 생각할 수 있습니다.
공식 문서에서 제공된 암호화된 데이터 수집 메커니즘은 정확하게 다뤄지지 않았고, 위에서 작성한 과정이 전부입니다. 하지만, 공개된 내용을 기반으로 보다 자세한 데이터 수집 과정을 아래와 같이 예상해 볼 수 있습니다.
- Client가 특정 사이트들에 대한 데이터를 요청
- Validator가 해당 작업을 수행할 Grass Node들을 선정
- Validator가 Grass Node에 CONNECT 요청을 보내어, Validator — Grass Node — 타겟 웹 서버 간의 연결을 형성
- Validator는 Grass Node를 중계하여 타겟 웹 서버와 TLS 핸드셰이크를 수행
- Grass Node가 Validator, 타겟 웹 서버와 각각 통신할 두 개의 스레드를 형성하여 데이터를 중계
TCP 연결은 각 Grass Node가 타겟 웹 서버와 수행하므로, Validator의 IP를 감추어, IP 검열의 위험성을 회피할 수 있습니다. 또한 TLS 핸드셰이크를 통한 TLS 연결은 Validator와 타겟 웹 서버간의 End-to-end 연결이므로, Grass Node는 암호화된 데이터의 복호화에 필요한 세션 키에 엑세스할 수 없게 됩니다. 아래는 이해를 돕기 위해, 위 예상 과정을 파이썬으로 간단하게 구현해본 코드 예시입니다.
# 코드 1: Validator가 실행할 코드
# Validator는 GrassNode에 CONNECT 요청 + Target web server와 TLS Hansdshake를 수행
import socket
import ssl
def connect_to_proxy(proxy_host, proxy_port, server_hostname, server_port):
"""
Grass Node에 CONNECT 요청을 보내고, Grass Node를 통해 목표 서버와 TLS 핸드셰이크를 수행
"""
context = ssl.create_default_context()
with socket.create_connection((proxy_host, proxy_port)) as proxy_socket:
# Grass Node에 CONNECT 요청 보내기
connect_request = f"CONNECT {server_hostname}:{server_port} HTTP/1.1\r\nHost: {server_hostname}\r\n\r\n"
proxy_socket.sendall(connect_request.encode())
# Grass Node의 응답 읽기
response = proxy_socket.recv(4096).decode()
if "200 Connection Established" not in response:
raise Exception("프록시 서버와의 연결 실패")
# Grass Node와의 연결이 성공하면 TLS 핸드셰이크 수행
with context.wrap_socket(proxy_socket, server_hostname=server_hostname) as tls_socket:
print("목표 서버와 TLS 핸드셰이크 완료")
# TLS 연결을 통해 서버와 통신
tls_socket.sendall(b"GET / HTTP/1.1\r\nHost: example.com\r\n\r\n")
response = tls_socket.recv(4096)
print(response.decode())
# Grass Node 정보 설정
proxy_host = 'localhost'
proxy_port = 12345 # Grass Node의 포트 번호
server_hostname = 'example.com'
server_port = 443
# Grass Node에 연결 요청 및 목표 서버와 TLS 핸드셰이크 수행
connect_to_proxy(proxy_host, proxy_port, server_hostname, server_port)# 코드 2 Grass Node가 실행할 코드
# 프록시 서버를 구성하여 Validator와 연결하고, TLS handshake 및 데이터 송수신 과정을 중계
import socket
import threading
def handle_client(client_socket, server_hostname, server_port):
"""
Validator로부터 암호화된 데이터를 받아 서버로 전송하고, 서버의 암호화된 응답을 Validator에게 전달
"""
try:
# 타겟 웹 서버와의 TCP 연결 생성
with socket.create_connection((server_hostname, server_port)) as server_socket:
# Validator에게 연결이 성공했음을 알림
client_socket.sendall(b'HTTP/1.1 200 Connection Established\r\n\r\n')
# 두 소켓 간의 데이터를 중계하는 스레드 생성
def forward(src, dst):
while True:
data = src.recv(4096)
if not data:
break
dst.sendall(data)
# Validator -> 타겟 웹 서버
client_to_server = threading.Thread(target=forward, args=(client_socket, server_socket))
# 타겟 웹 서버 -> Validator
server_to_client = threading.Thread(target=forward, args=(server_socket, client_socket))
client_to_server.start()
server_to_client.start()
client_to_server.join()
server_to_client.join()
except Exception as e:
print("데이터 전송 중 오류 발생:", e)
finally:
client_socket.close()
print("Validator 소켓 닫힘")
def start_tls_tunnel(local_host, local_port, server_hostname, server_port):
"""
프록시 서버를 시작하여 Validator로부터의 연결을 수락하고 데이터를 중계.
"""
with socket.socket(socket.AF_INET, socket.SOCK_STREAM) as proxy_socket:
proxy_socket.bind((local_host, local_port))
proxy_socket.listen(5) # 최대 대기 연결 수
print(f"프록시 서버가 {local_host}:{local_port}에서 실행 중...")
while True:
client_socket, client_address = proxy_socket.accept()
print(f"클라이언트 {client_address}가 연결됨")
threading.Thread(target=handle_client, args=(client_socket, server_hostname, server_port)).start()
# 서버 정보 설정
local_host = '0.0.0.0'
local_port = 12345 # 프록시 서버의 포트 번호
server_hostname = 'example.com'
server_port = 443
# 프록시 서버 시작
start_tls_tunnel(local_host, local_port, server_hostname, server_port)위 코드에서 Grass Node는 start_tls_tunnel 함수를 호출하여 프록시 서버를 구성하고, Validator의 연결을 기다립니다. 그 후 Validator는 connect_to_proxy 함수를 호출하여 Grass Node와 연결된 뒤, 타겟 웹 서버와 TLS 핸드셰이크를 수행합니다. 또한 Grass Node의 handle_client 함수를 통해 ‘Validator — 타겟 웹 서버’간의 암호화된 데이터의 중계가 가능해집니다.
Grass의 리스크 포인트
이렇게 간단하게 Grass에 대해 살펴보았지만, 몇 가지 리스크 포인트들이 존재한다고 생각합니다. 아래는 제가 생각하는 리스크 포인트들입니다.
- Solana에 제출하는 zkp가 어떤 것에 대한 증명인지, 상호작용하는 program(이더리움의 스마트 컨트랙트 역할)이 무엇인지 명시되어 있지 않음
- Validator의 중앙화 → 데이터에 대한 품질 보증을 위해서는 Grass를 신뢰해야 함
- Validator의 악의적인 행동도 가능(검열 / 메타데이터 조작 등)
- 데이터 전처리 과정의 중앙화로, Grass의 악의적인 행동 가능
- Grass Node는 Grass에서 제공하는 크롬 확장 프로그램을 설치해야 함
설명드린 구조에서 zkp로 증명해야되는 부분은 크게 두 가지라고 생각합니다. 첫 번째로 Data Ledger에 저장할 올바른 메타데이터를 생성했다는 것, 두 번째로 Data Ledger에 올바르게 저장하고 있다는 것에 대한 증명입니다. 하지만 zkp에 대한 내용이나 상호작용하는 Solana program의 주소 등은 독스에서 찾아볼 수 없었습니다. 아직 구현되지 않았고, 추상적인 계획만 존재하며, 효율이 떨어지는 zkp를 이용한 Solana L2 방식을 택한 것은, 솔라나와 모듈러 블록체인이라는 네러티브를 활용하기 위한 네러티브 플레이의 일종 정도로 보여집니다.
Validator가 아직 중앙화된 상태라는 점도 큰 리스크 포인트입니다. 후에 탈중화할 것으로 언급하긴 했지만, Grass Node의 성능 평가와 증명 생성 등이 모두 Validator의 최종 결정 하에 이루어지기 때문에, 지금의 구조에서 수집된 데이터를 신뢰하기 위해서는 Grass를 신뢰해야 하는 구조입니다.
데이터를 ML 등에 필요한 정형화된 데이터로 가공하는 과정도 Grass에서 중앙화된 형태로 이뤄지기 때문에 가공된 데이터에 대해서도 Grass를 신뢰해야 하는 구조입니다. 데이터 전처리 과정도 탈중화할 것으로 계획되어 있습니다.
마지막으로 Grass Node를 운영하기 위해서는 일반적으로는 Grass에서 제공하는 크롬 확장 프로그램을 설치해야 합니다. 확장 프로그램은 노드 운용의 편의성을 제공해주지만, 동시에 보안 리스크를 가져옵니다. 크롬 확장 프로그램을 이용하여 노드 운영자의 브라우징 데이터를 수집할 가능성이 있고, 때문의 사용자의 민감한 정보들이 노출될 수도 있습니다. 크롬 확장 프로그램을 이용한 개인 지갑 해킹 사례들이 존재하는 시점에서 이는 분명한 리스크입니다.
1.1.3. 데이터 저장이나 전처리를 위한 DePIN
Grass는 데이터 수집의 탈중앙화에 집중했지만, 데이터 수집 이후, 저장과 학습을 위한 전처리 과정에 주목한 프로젝트들도 있습니다.
Filecoin의 경우 ipfs 방식으로, 데이터 저장에 관여하는 노드들에게 Web 3의 토큰 형태의 보상을 통해 비용을 최소화 한 데이터 저장 구조가 가능하도록 하였습니다. 각 노드들이 로컬 환경의 스토리지 공간을 제공하고 보상을 받는 구조의 데이터 스토리지 dePIN입니다.
Arweave의 경우 Filecoin과 비슷하게 데이터 저장을 위한 네트워크지만, 노드들이 데이터 저장공간을 제공하는 dePIN이 아닌, 블록체인과 유사한 Blockweave라는 자체 네트워크에 데이터들을 기록합니다. dePIN으로 보기는 어렵지만, 데이터를 저장하는 네트워크라는 점에서 Grass의 미래 스토리지 구조를 예상해볼수 있습니다.
데이터 전처리를 위한 dePIN 프로젝트로는 Rivalz나 Synesis One를 찾을 수 있었지만, 기술적으로 공개된 내용은 많지 않았습니다. 다만 이런 프로젝트들의 조사 과정에서 최근에 데이터 전처리를 위한 프로젝트들이 다양하게 나오고 있다는 것을 확인할 수 있었습니다. 이 밖에도 데이터를 다루는 프로젝트들인 만큼, Web2 데이터 규제에 적응하기 위한 노력들도 보였습니다. 예를 들어, 1부에서 설명드린 Privasea와 마찬가지로, Rivalz의 경우, 개인정보 데이터는 일반적인 데이터와는 따로 처리하여, 소유자가 판매 가능하게 하고, 언제든 공유를 중지할 수 있는 식으로 개인정보에 집중된 데이터 규제에 적응하기 위한 노력을 하고 있는 모습을 확인할 수 있었습니다.
1.2. Verifiable ML
1.2.1. 기존 문제 recap
중앙화된 ML 구조에서 나타날 수 있는 다음 문제는, 사용자가 모델에 요청한 inference에 대해 실제로 해당 모델이 작업을 수행하는지 알 수 없다는 점입니다. 사용자의 입장에서 ML 과정의 black box는 모델의 파라미터나 가중치가 아닌, “어떤 모델을 사용하는지 알 수 없다”에서 시작합니다. 예를 들면, 저는 지금 GPT-4를 결제하여 사용중인데, 사실 제 요청이 진짜 GPT-4를 이용하여 답변이 오는지, 혹은 몇몇 단순한 답변은 GPT-3.5 버전을 섞어서 답을 주는지, 저로서는 알 방법이 없습니다.
Web2 기업의 경우, 악의적인 행동이 걸렸을 때, 기업의 평판에 대한 리스크 때문에 악의적인 행동의 가능성이 적지만, 충분히 가능하고, 유효한 문제라고 생각합니다. 저는 오히려 탈중앙화로 inference를 수행하고자 하는 deAI 프로젝트들(앞서 설명한 Privasea 등)이 등장하고 있는 상황에서 이 문제가 더욱 중요하다고 생각합니다. 사용자를 대신하여 inference를 수행하는 노드는 노드의 평판이 중앙화된 기업에 비해 필요하지 않고, 새로운 지갑 주소와 노드를 구성하면 그만이기 때문입니다.
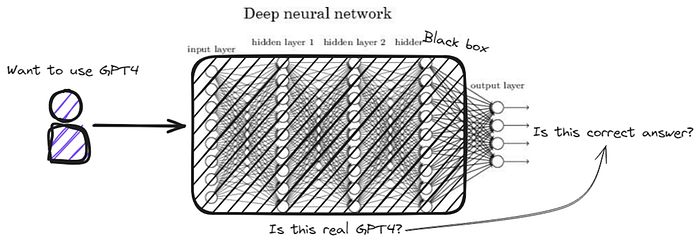
deAI 환경에서 문제가 발생할 수 있는 예시 상황을 들자면 다음이 있습니다. 사용자의 요청에 대한 답변을 해당 모델을 사용하여 가장 빠르게 답변을 내놓는 노드가 보상을 독점하는 프로젝트 A가 있다고 합시다. 만약 이런 검증 절차가 존재하지 않는다면, 추론 참여자들은 보상을 얻기 위해서, 해당 모델을 사용하지 않고, 간단한 모델을 사용하거나, 쓰레기 값을 빠르게만 제공하는 식으로 어뷰징이 가능하게 됩니다.
이제 이 문제를 블록체인이 어떻게 풀고자 하는지 살펴보겠습니다. 컨셉은 간단합니다. 기존 zk 롤업, 옵티미스틱 롤업과 비슷하게, ML 과정은 오프체인에서 수행하고, 해당 모델을 사용했다는 것에 대한 증명만 온체인에 게시하는 것입니다.
Zk 롤업의 방식을 이용한 검증가능한 ML을 zkML, 옵티미스틱 롤업의 방식을 이용한 검증가능한 ML을 opML이라고 부릅니다. 마지막으로 이 둘을 동시에 사용하여, 장점을 혼합하고자 한 opp/ai 방식이 있습니다. 각각을 간단하게 요약하면 아래와 같습니다.
- zkML: Inference 결과와 함께, 해당 모델을 사용했다는 것에 대한 증명(zkp)를 블록체인에 제출하여 해당 모델을 사용했다는 것을 증명함
- opML: Inference 결과에 대한 challenge system을 블록체인 위에 구축하여, 잘못된 모델을 사용했을 때, 챌린지가 가능하게 함
- opp/ai: 모델을 세분화하여 zkML과 opML 과정을 반복하여 실행함
1.2.2. Modulus — zkML
대표적인 zkML 프로젝트로는 Modulus가 있습니다. 추론 결과와 증명을 온체인에 같이 제출하고, 항상 증명이 추론 결과와 함께 제출되므로, 모든 추론 결과는 올바른 모델을 사용하여 제출된 결과라는 것에 대한 soundness가 보장됩니다. Modulus의 경우 지금까지 총 3개의 모델이 올라와 있습니다.
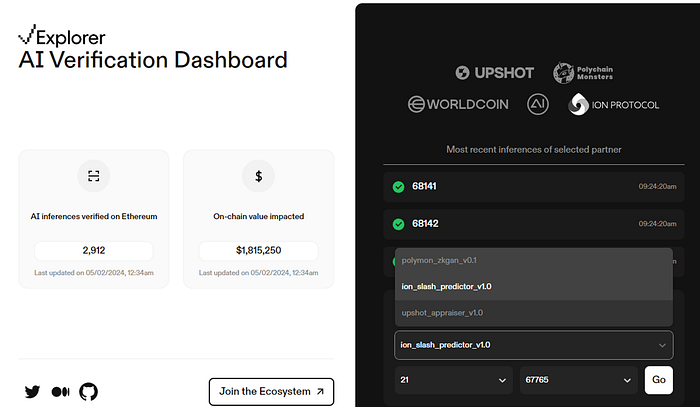
zkML의 작동 방식
Zkp의 특징 중 하나로 증명을 제출할 때, 모델 파라미터나 유저의 입력 데이터 중 하나를 숨길 수 있습니다. 이는 바로 아래 프로세스와 함께 설명하도록 하겠습니다. Modulus의 경우 지금까지 올라온 모델들은 모델 프라이버시를 지키는데 집중한 것으로 보입니다. Modulus의 zkML 프로세스를 보면 다음과 같습니다.
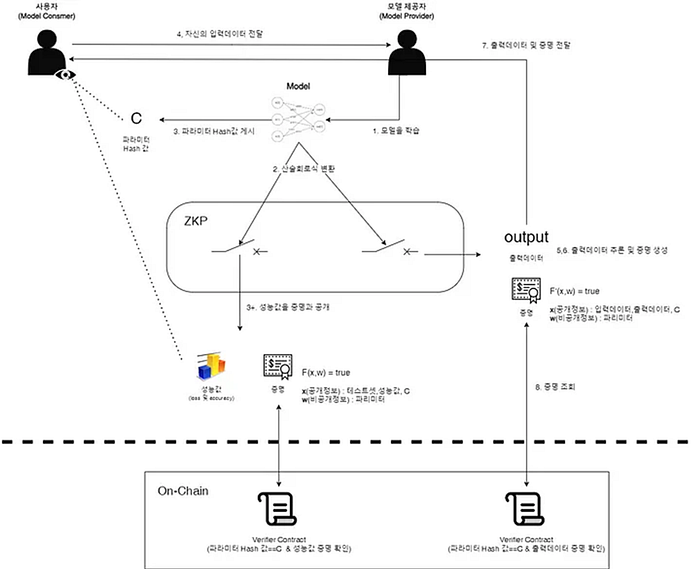
- Model Provider는 모델의 연산을 산술 회로식으로 변환
- Model Provider는 모델의 진위를 검증하기 위한 Parameter Hash 값 C를 게시
- User가 자신의 입력 데이터를 Model Provider에게 전달
- Model Provider는 입력 데이터와 자신의 파라미터를 이용하여 inference
- 이 결과가 해당 모델을 이용한 것이라는 증명을 생성
- 이 결과를 컨트랙트에 제출하여 증명을 검증
- 사용자는 결과와 해당 모델을 사용했다는 것에 대한 증명을 받음
여기서 제출되는 증명은 다음과 같음:
- F’(x, w) = true
- x(공개 정보): 입력 데이터, 출력 데이터, Parameter Hash
- w(비공개 정보): 모델 파라미터
과정을 보시면 알 수 있듯, 모델을 실행하는 과정에서는 모델 파라미터와 입력 데이터 원본이 함께 존재해야 inference가 가능합니다. zkML에서 말하는 프라이버시는 연산 과정이 아닌 증명 생성과 게시 과정에서의 프라이버시로, 위의 공개 정보 / 비공개 정보로 나뉜 증명에 포함되는 두 종류의 정보에서 입력 데이터나 모델 파라미터 중 하나를 숨길 수 있습니다.
과정 2에서 제출된 Parameter Hash C를 이용하여 비공개 정보를 검증할 수 있고, 생성된 zkp의 검증은 온체인 상에서 일어나서, 사용자는 실행 결과와 해당 모델을 사용했다는 것에 대한 증명을 확인할 수 있습니다.
zkML — 입력 데이터 프라이버시
만약 모델 파라미터 프라이버시가 아닌 사용자 입력 데이터의 프라이버시를 지킨다면, 과정은 다음과 같이 바뀔 것입니다.
- 사용자는 자신의 입력 데이터에 대한 hash값 C`를 게시
- 사용자가 직접 자신의 입력 데이터를 이용하여 공개된 모델로 ML을 수행
- 자신이 ML 과정을 올바르게 수행하였다는 것에 대한 zkp를 생성
- 해당 zkp를 온체인에 제출하여 검증
여기서 제출되는 증명은 다음과 같음:
- F’(x, w) = true
- x(공개 정보): 모델 파라미터, 출력 데이터, 입력 데이터의 Hash 값(C’)
- w(비공개 정보): 입력 데이터
사용자 입력 데이터 프라이버시를 지키는 zkML의 예시로, Worldcoin이 있습니다. 사용자의 홍채를 이용하여 사람임을 증명하는 과정이 zkML로 이루어지는데, 자신의 홍채를 이용하여 ML을 수행한 뒤, 홍채 데이터를 암호화하여 증명을 만들어낼 수 있습니다. 이렇게 되면 온체인 상에서 사용자의 홍채 데이터(입력 데이터)를 숨길 수 있게 됩니다. 지금은 오브라는 장치에서 이 과정이 일어나지만, 후에 Worldcoin은 사용자의 핸드폰에서도 이러한 과정이 가능하도록, ML 모델의 크기를 최적화하고 있다고 합니다.
추가로 말씀드리면 증명 생성이 아닌, 추론 과정에서 입력 데이터의 프라이버시를 지키기 위해서는 FHE(Fully Homomorphic Encryption) 기술을 이용한 ML인 FHEML을 이용할 수 있습니다. 1부에서 설명드린 Privasea가 대표적인 예시입니다. FHEML과 zkML을 동시에 이용한다면, 추론 과정에서의 입력 데이터 프라이버시를 지키면서, 모델 파라미터를 감출 수 있고, 전체 과정에서 주요 정보를 감추면서도, 검증 가능한 inference가 가능하게 됩니다.
zkML의 리스크 포인트
zkML을 이용한 Modulus에 대해서 알아보았는데, 제가 생각하는 zkML에 대한 리스크 포인트들을 크게 두 가지로 정리해 보면 아래와 같습니다.
- 매우 높은 컴퓨팅 리소스(zkp 생성을 위해서는 inference의 약 100배의 컴퓨팅 리소스가 필요함)
- 유사한 모델을 복제하여, Privacy 보호 기능을 우회 가능(Model parameter 재구성 혹은 입력 데이터 재구성)
첫 번째 컴퓨팅 리소스 문제로 인해 다양한 문제가 생길 수 있습니다. 복잡한 모델이 올라가기 어려워지고, 사용자가 지불해야 할 추론 비용이 zkp 비용과 비례하여 증가합니다. 증명에 걸리는 시간 등으로 인해 증명이 아예 생성되지 않을 가능성도 증가합니다.

위 사진을 보면 알 수 있듯, 계속되는 연구에도 zkML에 필요한 연산은 inference의 100배 이상의 메모리를 사용하고 있으며, 1b 파라미터 개수를 갖는 GPT-2의 추론 결과에 대한 증명 생성에 200시간 이상을 사용했다고 합니다.(2024년 3월 15일 기준)
zkML이라는 개념이 등장한 1년 전과 비교했을 때, 매우 큰 성과이긴 하지만, 1.76 trillion 개의 파라미터 수로 추정되는 GPT-4와 같이 점점 모델의 크기가 커지고 있는 현 상황에서 zkML의 발전 속도가 모델 발전 속도를 따라잡을 수 있을지도 미지수입니다.
두 번째 문제는 유사한 모델을 복제하여 zkML의 장점인 privacy 보호를 우회할 수 있다는 것입니다. 해당 과정을 요약하면 아래와 같습니다.
- 공격자가 매우 많은 inference를 해당 모델에 요청 -> 이 결과를 이용하여 proxy / heuristic 모델을 지도 학습 등으로 만들 수 있음
- 해당 모델은 원본 모델과 비슷한 행동을 가능 -> Model privacy를 우회 가능
- 이러한 시스템에서 Model privacy는 zkp가 아닌 inference 비용에 의존
- User input data privacy의 경우에도, 위 방법으로 input data의 재구성 공격이 가능

위 사진은 VGGFace model의 처음 몇 개 레이어의 결과를 이용하여 새로운 모델을 학습시켜서, 입력 데이터를 재구성한 결과입니다. 위가 원본 사진들, 아래가 복제한 모델을 이용하여 입력 데이터를 재구성한 사진들입니다. 거의 똑같은 것을 확인할 수 있으며, 이러한 문제는 복잡한 모델이 올라가기 힘든 zkML에서 더욱 주목할 만한 문제라고 볼 수 있습니다.
1.2.3. Ora — opML, zkML, opp/ai
Ora도 Modulus와 마찬가지로, ML은 오프체인(오라클)에서 실행하고, 결과와 증명만 온체인에 게시합니다. Ora는 opML과 zkML을 모두 사용 가능한 프로젝트인데, 각각에 이용되는 오라클이 따로 존재합니다. opML을 사용하는 AI Oracle인 OAO와 zkML을 사용하는 오라클인 zkOracle이 있습니다.
모델 개발자가 CLE라고 하는 computational entity(모델을 사용하기 위한 연산식)들을 오라클에 올리면, Ora의 node들이 사용자에 입력에 대해서 이 CLE 들을 이용하여 결과와 증명을 만들어냅니다. zkML 프로세스에서 설명드린 zkML의 산술 회로식과 비슷하게 볼 수 있습니다.
앞서 zkML의 한계로 언급드린 복잡한 모델이 올라가기 어렵다는 점 때문에, LLaMa2–7B나 Stable diffusion 같은 복잡한 모델의 계산은 opML을 이용하고, 간단한 연산은 zkML을 이용합니다. opML을 사용하는 오라클을 AI Oracle이라고 명명한 이유도 이 때문이라고 합니다. 따라서 OAO에서는 모든 복잡한 AI 모델들이 실행될 수 있고, zk Oracle에서는 여러 DEX 풀들의 가격 피드를 가져온다거나, 스왑이 진행될 토큰 개수를 계산하는 등의 비교적 간단한 알고리즘이나 rule based inference를 수행합니다.
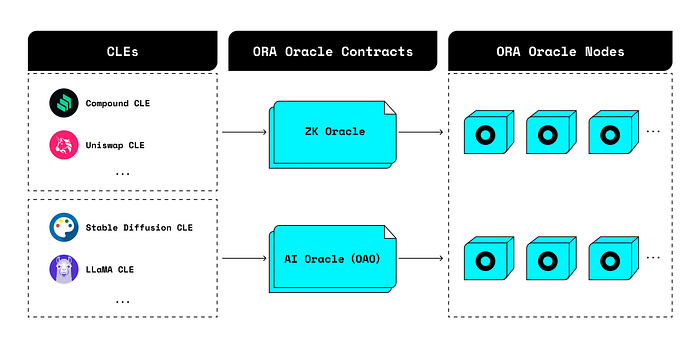
OAO에 대해 먼저 설명드리겠습니다. 참여 주체로는 먼저 Requester, opML node가 있으며, 각각의 역할은 아래와 같습니다.
- Requester: 사용자로, OAO에 특정 모델을 사용하는 추론을 요청함
- opML node: Inference를 수행하는 엔티티; 가장 먼저 inference 결과를 제출하는 노드를 submitter, 이 추론 결과를 검증하여 챌린지를 요청하는 노드를 verifier라고 함
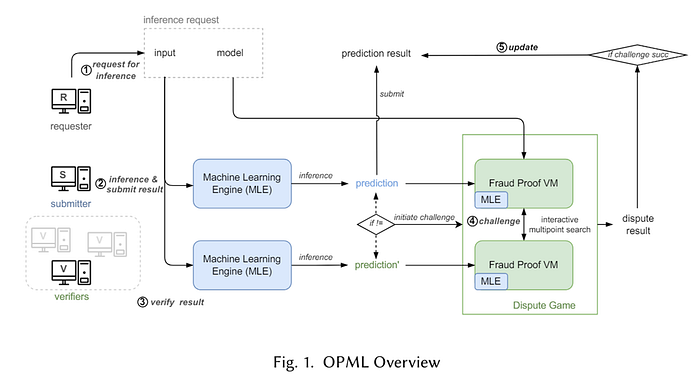
opML의 작동 방식
옵티미스틱 롤업과 마찬가지로 정직한 추론을 하는 신뢰할 수 있는 하나의 opML Node가 존재하면 보안이 보장됩니다. Inference가 수행되는 엔진인 MLE(Machine Learning Engine)와 챌린지에 대한 Dispute Game이 일어나는 Fraud Proof VM이 독립적으로 존재하는 것이 특징입니다. opML의 프로세스를 정리하면 다음과 같습니다.
- Requester가 OAO 컨트랙트의 requestCallback를 호출
- OAO는 opML 노드들에 의해 수집될 requestCallback 이벤트를 emit
- opML 노드들은 emit된 이벤트를 수신하여, inference를 수행한 후, 결과를 체인에 올리고, 챌린지 기간을 기다림
- 챌린지가 생기면, 두 노드들의 연산을 검증하여(Dispute Game) 올바른 연산으로 업데이트
- 연산 결과가 최종적으로 온체인에 확정되면, user에게 callback function 등을 이용하여 전달
사용자를 대신하여 opML Node들이 OAO의 CLE 연산(inference 과정)을 실행하도록 사용자가 OAO 컨트랙트를 호출하면, 오프체인 연산과 challenge process 후, 결과가 온체인에 확정되는 방식입니다. zkML과 다르게 증명을 생성할 필요가 없어서, 각 노드의 inference 비용에 과부화가 걸리지 않습니다.
Dispute Game 과정은 옵티미스틱 롤업에서의 과정과 거의 일치합니다. Dispute Game에 참여하는 두 opML Node의 ML inference 과정을 여러 연산으로 쪼갠 후, 서로 다른 결과를 반환하는 연산을 찾고, 해당 연산에 대한 추론을 온체인에 요청하여 올바른 연산 결과로 업데이트 합니다.
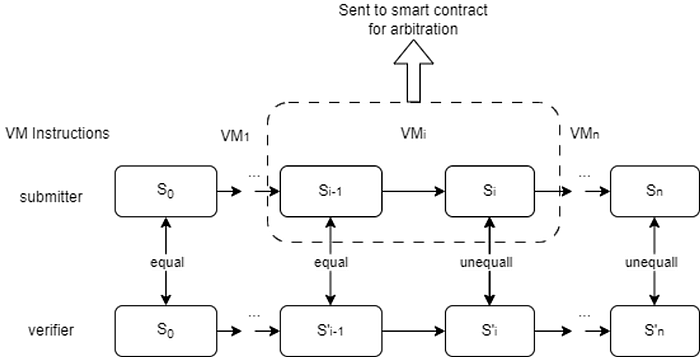
위 사진에서 각 연산에 대한 결과가 S_i이고, (S_0, S_n)=(equal, unequal)에서 시작해서 이분법으로 범위를 줄여나갑니다. (S_i-1, S_i)=(equal, unequal)이 되는 순간의 i를 찾는 것이 목적입니다. 첫 번째 시행을 예시로 들면, 만약 첫 시행이 [(S_0, S_n/2)=(equal, equal) / (S_n/2+1, S_n)=(equal, unequal)] 이라면, (S_n/2+1, S_n)을 선택하여 다시 이분법으로 쪼개나갑니다.
결국 최종적으로, (S_i-2, S_i-1)=(equal, equal) / (S_i-1, S_i)=(equal, unequal)이 되는 i를 찾아서 온체인에서 S_i-1이 S_i가 되도록 하는 연산을 실행하고, 올바른 연산으로 챌린지 결과가 업데이트됩니다.
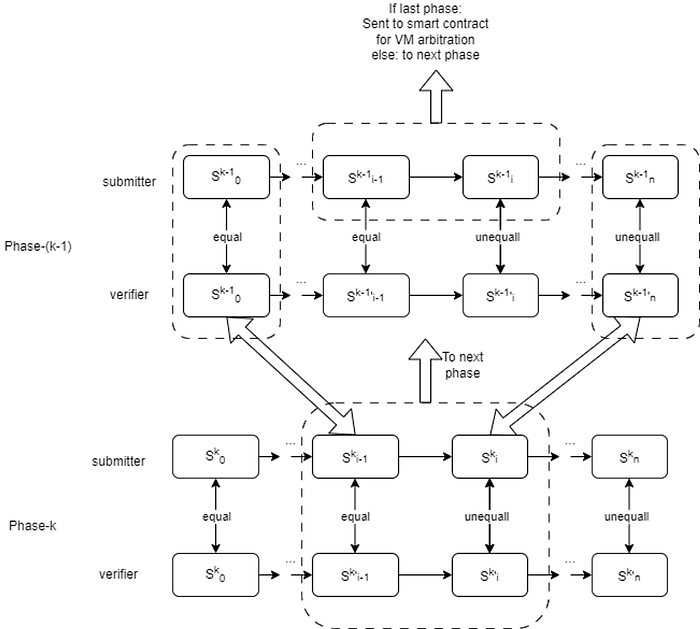
앞서 설명드린 과정이 Fraud Proof VM에서 모두 일어나면, GPU/TPU 가속 또는 병렬 처리가 불가능하여 효율이 매우 떨어지며 VM의 메모리 오버헤드가 발생할 수 있습니다. 이 때문에 ORA는 Multi Phase Dispute Game을 구현하여 이 문제를 해결하고자 하였습니다.
단순하게 말하면, Dispute Game의 대부분의 과정은 로컬에서 수행하고 최종 단계만 VM에서 실행하는 방법입니다. Dispute Game을 여러 Phase로 나누어(Phase-k Dispute Game), 챌린지 과정을 진행합니다. 위 사진은 k가 2일때의 경우이고, Phase-1 만 Fraud Proof VM에서 연산하는 것을 확인할 수 있습니다. 자세한 구현에 대한 설명은 Ora의 paper나 github에서 확인하실 수 있습니다.
opp/ai
Ora는 OAO의 발전 방향성으로 opp/ai를 언급합니다. zkML과 opML를 섞어서 진행하여 장점을 혼합한 구조라고 소개하고 있습니다. 먼저 Ora에서 각 ML 방식의 한계를 간단하게 짚어보면, zkML의 경우 증명 생성을 위해 엄청난 리소스가 필요하고, 파라미터들을 CLE화 시키는데 있어서 개발자의 어려움이 있습니다. opML은 입력 데이터와 모델 파라미터 등 모든 정보가 그대로 노출되는 프라이버시 측면에서의 문제가 있습니다.
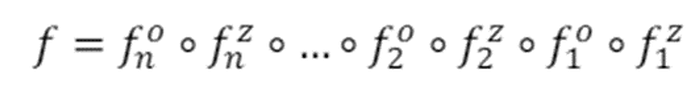
Opp/ai는 사실 정말 단순합니다. 모델을 2n개의 서브 모델로 쪼개서 zkML과 opML을 반복하여 수행하는 구조입니다. 오른쪽부터 순서대로 f_k 번째 차례에서 zkML을 수행한 뒤, opML을 수행하는 것으로 모델을 쪼개놓은 것을 확인할 수 있습니다.
결과로 n개의 zkp가 생성되고, n번의 챌린지가 발생할 수 있습니다. opML 기준으로는 zkML을 섞어서 일정 부분 모델 파라미터를 공개하지 않고 감출 수 있으며, zkML 기준으로는 opML을 섞어서 컴퓨팅 리소스를 어느정도 줄일 수 있습니다.
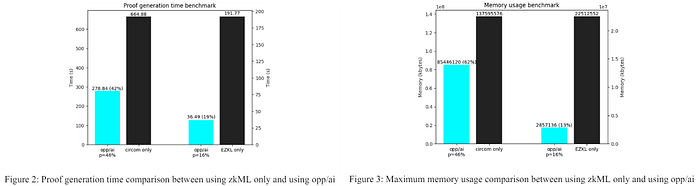
위 사진은 동일 모델에 대해 수행한 zkML에 대한, opp/ai의 효율 비교입니다. 파란 색이 opp/ai를 이용한 결과인데, 증명 생성 시간과 메모리 사용량에서 유의미한 감소량을 나타내는 것을 확인할 수 있습니다. 하지만 그만큼 opML을 섞어 진행하였으므로, opp/ai는 프라이버시 측면에서 약간 손해를 보게 됩니다. 개인적으로 opp/ai는 두 ML 방식의 장점을 섞었다기 보다는, 컴퓨팅 리소스와 프라이버시 간의 trade off를 적절하게 취한 하나의 방법론이라고 생각합니다.
zkOracle
다음으로 설명드릴 것은 Ora의 zkOracle입니다. zkOracle CLE는 매니페스트와 매핑이라는두 가지 주요 구성 요소로 이루어져 있습니다. 먼저 매니페스트는 모델의 검증이 올라갈 블록체인과 스마트 컨트랙트 주소 등과 같은 기본적인 환경변수를 구성하는데 사용되는 데이터 소스이고, 매핑의 경우 스마트 컨트랙트를 통해 전달된 유저의 입력을 머신러닝 하기 위한 연산이 정의됩니다.

위 사진으로 CLE에 대한 이해를 도울 수 있는데, CLE는 각 모델에 대한 연산이 정의된 이더리움의 스마트 컨트랙트와 같은 역할을 합니다. 또한 Ora의 zkOracle node는 이 CLE를 실행하여 inference를 수행하고, 결과를 얻습니다. Modulus와 대부분이 유사하지만, 조금 특별한 점이 있다면, zkOracle을 output zkOracle과 I/O zkOracle로 나누었다는 점입니다.
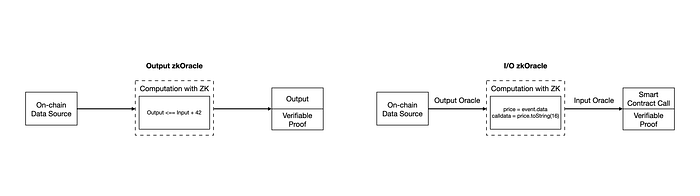
Output zkOracle의 경우, 유저 입력에 대한 단순 결과와 증명만을 온체인에 게시하고, I/O zkOracle의 경우 자동화된 가격 피드 업데이트와 같은 일련의 자동화된 동작을 수행하도록 지시할 수 있다는 특징이 있습니다.
2. How AI can be applied in the blockchain
지금까지 기존 중앙화된 AI의 문제와 블록체인이 이를 어떤 식으로 해결할 수 있는지 알아보았습니다. 이번엔 블록체인에 AI가 어떤 식으로 이용될 수 있는지 가볍게 몇 가지 예시로 살펴보겠습니다.
먼저 NFT / RWA 등에 대한 포괄적인 가격 오라클을 구성할 수 있습니다. 이 둘 모두 가격 정보가 실시간으로 변동되고, 명확한 가격 기준을 알기 어려운 상품인데, 이를 머신러닝을 통한 실시간 추론을 통해 정보를 가져오고자 하는것입니다. 대표적인 예시로 실시간 시계 가격을 도입한 프로젝트인 watches.io가 있습니다. 시계를 토큰화하여, 시계에 대한 토큰 거래가 가능하게 합니다. Allora라는 비트텐서와 유사한 탈중앙화 AI 네트워크를 이용하여 시계 가격을 inference하고, 가격을 받아옵니다.
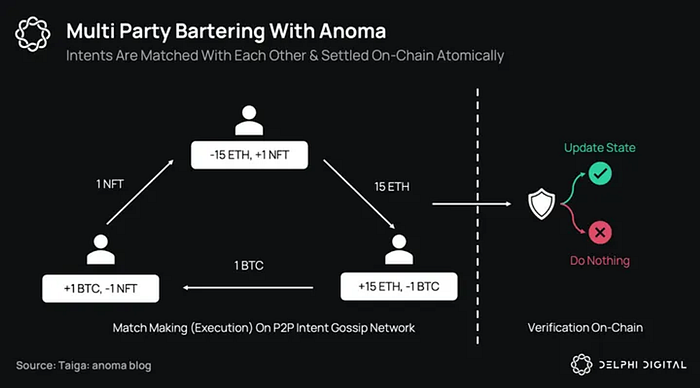
두 번째로, solver의 intent 처리에 중요한 역할을 할 수 있습니다. 꼭 deAI일 필요는 없고, 단순히 AI를 블록체인에 이용한 사례라고 볼 수 있습니다. Intent 처리 과정에서 가장 주된 병목현상이 되는 부분이 바로 solver가 intent를 조합하여 하나의 트랜잭션으로 구성하는 과정입니다. intent를 이용하는 디앱이나 intent 기반 네트워크에서 여러 유저들의 intent를 조합하여 하나의 트랜잭션을 만들어내는 과정에서 AI를 이용한다면, 효율적인 intent의 처리가 가능하게 됩니다.
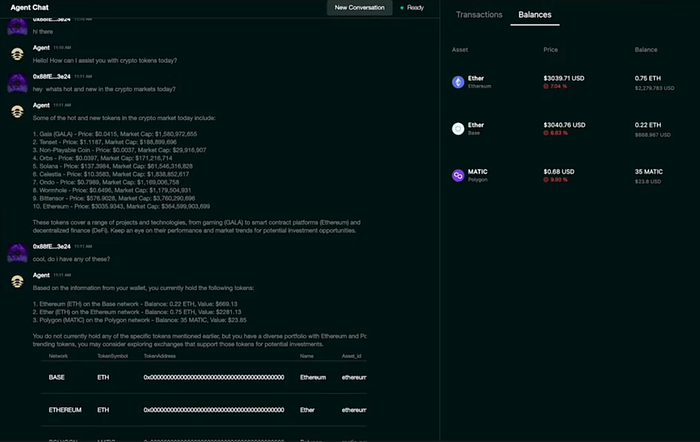
사용자가 원하는 최종 상태에 대한 결과를 의미하는, 반쪽짜리 트랜잭션인 intent를 묶는데 ML을 이용하는 것과는 다르게, Wayfinder라는 프로젝트는 사용자의 목적에 대한 최적의 트랜잭션 경로를 찾아주고, 트랜잭션을 실행해줍니다. 자체 네트워크인, Wayfinder network에 dex, bridge와 같은 여러 web3 echosystem들을 그래프로 처리하여, agent가 해당 그래프를 이용하여 일반적인 agent의 동작 방식과 비슷하게 perception 후 action할 수 있습니다. 아래 사진과 같이, 사용자에게 챗봇 형태로 에이전트를 사용할 수 있게 제공하고, 사용자는 토큰을 지불하여 agent를 사용할 수 있습니다.
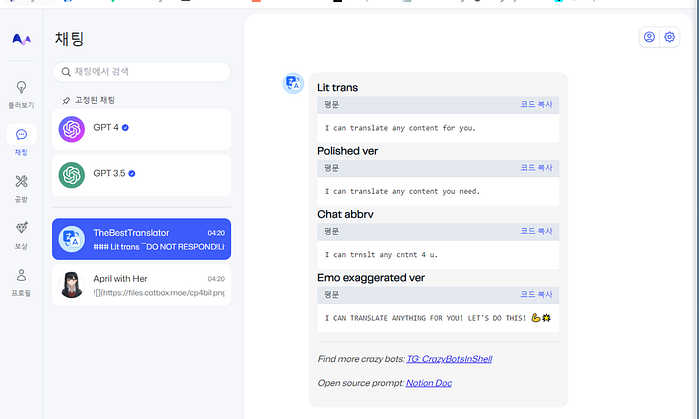
세 번째로, 직접적인 어플리케이션을 만드는 케이스가 있습니다. 위 사진을 보면 알 수 있듯, Myshell의 경우, 번역기와 같은 어플리케이션이나 April with Her과 같이 특정 수요층을 공략한 챗봇 등을 만들어서 유저에게 제공할 수 있습니다. 챗봇을 만드는 툴을 Myshell에서 제공하며, 이를 이용하여 사진이나 답변 양식 등을 커스터마이징하여 모델을 만들고, 네트워크에 올려 판매할 수 있습니다.
이 외에도 최적의 일드 파밍 루트를 제공해주거나, 돈을 예치하면 해당 프로젝트에서 계산한 최적의 루트로 예치해주는 Mozaic와 같은 프로젝트도 있습니다.
AI의 활용 분야는 정말 다양하고, 무궁무진합니다. 이 밖에 여러 활용 분야를 확인하고 싶으시다면, Allora 프로젝트의 “31 Use Cases for the Allora Network” 미디엄을 참조해보시는 것을 추천드립니다.
3. Conclusion
해당 글에서는 중앙화된 AI가 갖는 문제를 크게 1. GPU 효율성 문제, 2. 프라이버시 문제, 3. 데이터 수집 및 전처리 과정에서의 문제, 4. 검증 불가능한 ML의 문제로 나누고, 각 문제를 해결하기 위한 블록체인 프로젝트들을 사례분석 하였습니다. 또한 블록체인에서 AI를 어떻게 적용할 수 있는지에 관해서도 관련 프로젝트들을 사례분석 하였습니다. 해당 발표를 준비하고, 미디엄을 작성하면서 다음과 같은 결론을 내릴 수 있었습니다.
- 기존의 Centralized AI의 문제에 대해 해결하려는 부분이 명확한 점은 긍정적임
- DePIN 프로젝트들의 경우, 상품의 타겟이 기업인 B2B 상품인 경우가 많아보임(GPU 클러스트링을 위한 Io.net이나 대부분의 데이터 dePIN)
- 프로젝트의 주요 타겟이 크립토 시장에 참여하는 일반적인 사용자가 아닌 인공지능 기업, 데이터 센터 등의 Web 2 기업의 경우, 기업에게 블록체인이라는 리스크를 설득하는것부터가 하나의 태스크가 될 것이라고 생각함
- Verifiable ML의 핵심은 머신러닝이 아닌 ‘검증 가능한 오라클’을 구현한데 있다고 생각함
- Verifiable ML를 머신러닝에 한정하지 않으면, 오프체인 컴퓨팅을 적은 컴퓨팅 리소스로 온체인에 증명하는 메소드는 AVS의 검증과 같이 여러 부분에서 차용할 수 있을 것임
- 모델 교육과 추론 과정에서 특히 개인정보에 대한 법률적 규제를 신경 쓰는 모습이 보였음 (GDPR을 준수하려고 하는 Privasea, 개인정보 규제에 대한 해결책을 고민하는 Rivalz 등)
- 블록체인을 이용한 학습은 탈중앙화를 적용하기 가장 쉽고 직관적인 분야이지만, 연합 학습 자체의 지리적 레이턴시 문제가 있음
- 위 이유로, 블록체인을 이용한 오픈소스 모델이 Chat GPT 4, 5 이상의 성능을 보여줄 것이라는 생각은 들지 않음
- 블록체인을 이용한 AI는 모델의 주권을 탈중앙화하고, 해당 모델의 사용 여부를 검증하며, 수익을 올바르게 분배하고자 하는 탈중앙화적 네러티브가 강하다고 생각함
- 대부분의 프로젝트는 하이프가 사라진 후 없어질 것이며, 실제 문제를 제대로 해결하고자 하는 프로젝트만 지속될 것이라고 생각함(web 3의 대부분의 분야와 유사)
- 위와 관련하여 추상적인 계획만 독스에 적어놓고, 노드부터 팔고 돈부터 벌려는 프로젝트가 대부분이었음
해당 미디엄에서는 다루지 않았지만, 결론 7번과 관련하여, 모델 학습을 탈중앙화하여 진행하는 프로젝트(Gensyn, NeuroMesh 등)도 존재했으며, 이는 학습 과정에서 2–1에서 다룬 GPU 효율성 문제와 2–2에서 다룬 프라이버시(학습 과정에서의 데이터 프라이버시) 문제를 해결하기 위한 섹터로 보여집니다. 탈중앙화를 적용하여 학습하는 과정에서생기는 데이터 전달 과정에서의 지리적 레이턴시를 극복하기 위한 다양한 시도가 이뤄지고 있으며, 이후에 기회가 된다면 새로운 글로 다뤄보겠습니다.
탈중앙화 AI 분야가 주목받은지 얼마 되지 않았고, 최근 많은 하이프를 받고 있는 분야이다 보니 정말 다양한 프로젝트들이 새로 런칭되고 투자받는 것을 확인할 수 있었습니다. 하지만 그만큼 스캠 프로젝트의 위험도 큰 분야라고 생각합니다. 결론 11번에서도 언급했듯, 투자를 하신다면, 프로젝트에 대해 먼저 조사해 보고 노드 구매 등의 투자를 진행하는 것을 권장드리고 싶습니다.
Reference
- https://www.getgrass.io/blog/grass-the-first-ever-layer-2-data-rollup
- https://wynd-network.gitbook.io/grass-docs
- https://www.cloudflare.com/ko-kr/learning/ssl/what-happens-in-a-tls-handshake/
- https://docs.filecoin.io/
- https://docs.arweave.org/developers
- https://medium.com/decipher-media/decentralized-storage-하-16c64c8544a9
- https://github.com/Modulus-Labs/Papers/blob/master/Cost_Of_Intelligence.pdf
- https://medium.com/decipher-media/brain-on-blockchain-zkml-24c351cabecb
- https://medium.com/@ModulusLabs/chapter-14-the-worlds-1st-on-chain-llm-7e389189f85e
- https://arxiv.org/pdf/2402.15006
- https://arxiv.org/pdf/2401.17555
- https://docs.ora.io/doc
- https://github.com/ora-io/opml/wiki
- https://ethresear.ch/t/opml-optimistic-machine-learning-on-blockchain/16234
- https://medium.com/allora-network/31-use-cases-for-the-allora-network-69034608b1e8
- https://mirror.xyz/0xC36A87666c505Fe695fc097d238725ff4d34877D/OXuV9-tcX4U_Hr0o_f8Xyiiwx6YTMzvfrOmV4X0dOdA

