[Sui Research] 1. Sui 개괄 및 Move 언어와의 연관성
새로운 L1, Sui의 구조에 대해 알아보자.
본 아티클에서는 Mysten Labs에서 개발하고 있는 새로운 L1인 Sui의 아키텍쳐, 컨센서스 엔진 및 토크노믹스와 Diem 재단에서 개발한 블록체인 프로그래밍 언어인 Move에 대해 다룹니다. 필자는 Sui나 Move와 아무런 연관이 없으며, 본문은 정보 제공을 목적으로 작성된 글로 투자 의사 결정에 대한 근거로 사용될 수 없음을 밝힙니다.
Authors
Taron(@taronsung)
Seoul Nat’l Univ. Blockchain Academy Decipher(@decipher-media)
Reviewed By 정재환

Sui Research
1. Sui 개괄 및 Move 언어와의 연관성
2. 아키텍처 및 컨센서스 엔진
목차
1. Introduction: Sui가 해결하려는 문제
2. Move: Sui가 채택한 이유
3. Sui의 Tokenomics
1. Introduction: Sui가 해결하려는 문제
Sui는 Diem(구 Libra) 프로젝트 출신의 개발자들이 구현한 새로운 L1입니다. 그 외에도 Diem 출신 개발자들이 만든 L1으로 Aptos가 있는데, 본 글에서는 Sui를 집중적으로 분석합니다.
Sui의 공동 창립자 중 한 명인 Evan Cheng은 블록체인은 자산이 존재하는 네트워크로, 자유롭게 자산을 생성하고, 효율적으로 자산을 이동할 수 있어야 한다고 합니다. 나아가 이러한 자유로움을 게임 산업에 충분히 활용하고자 합니다. 기존의 웹2 게임들을 대중이 ‘AWS 게임’이라고 명명하지 않듯, 웹3 게임들도 ‘블록체인’ 게임이라고 인식될 필요가 없다는 것입니다. AWS나 블록체인이나 결국 게임이 구동되는 네트워크에 불과하기 때문입니다.
다만 블록체인 위에 구현된 게임이 가질, 나아가 대중에게 인식되어야 하는 특질은 ‘한 게임의 자산을 다른 게임에서 자유롭게 사용할 수 있다는 점’이라고 주장합니다. 예컨대, 게임에서 귀중하게 취급되는 무기가 NFT로 발행되면, 해당 NFT를 웹사이트 미니 게임에서도 활용할 수 있는 등 기존 웹2 게임과는 달리 무한히 확장 가능한 게임이 출시될 수 있다는 것입니다.
Evan Cheng은 위 인터뷰에서 이러한 확장 가능성이 현실화되기 위해서는 블록체인에 대한 디자인부터 근본적으로 바뀌어야 한다고 주장합니다. 모든 데이터를 스마트 컨트랙트 내부에 넣는 것은 결국 동일한 스마트 컨트랙트에 수많은 사람들이 동시에 접근해 자신의 자산에 변화를 가해야 함을 의미하고, 이는 불필요한 경쟁을 발생시키는 구조라는 것입니다. 이를 해결하기 위해 블록체인에는 ‘소유권에 대한 증빙’이 저장되어야 한다고 주장합니다. 이로써 자산은 하나의 객체로 취급될 수 있고, 객체화된 자산은 게임과 게임, 플랫폼과 플랫폼 사이를 자유롭게 노니는 확장 가능성을 가집니다.
권리에는 책임이 따르듯, 위와 같은 자유로움을 활용하기 위해서는 충분한 보안이 보장되어야 합니다. 자산에 대한 보안이 보장되면서, 상기한 (1) 자유로운 자산 생성과 (2) 효율적인 자산 전송을 이루기 위한 새로운 L1이 바로 Sui입니다. 기존 이더리움 구조의 문제점에 착안한 체인이기 때문에, Sui는 L2가 아닌 새로운 L1을 제시하고, 나아가 합의 알고리즘과 실행 엔진에 변화를 가하는 방식으로 문제를 해결하고 있습니다.
Sui는 Move 프로그래밍 언어로 구현되어 있습니다. 아래에서는 Move 언어의 특징과 왜 Move가 새로운 블록체인 언어로서 등장했는지, 최종적으로는 Sui에서 Move 언어를 선택한 이유를 알아보겠습니다.
2. Move: Sui가 채택한 이유
- Move란?
Move는 리브라 재단(現 디엠)에서 개발한 블록체인 프로그래밍 언어로, 디지털 자산 관리에 적합한 언어라는 표어를 내세우고 있습니다. 종래 Move는 리브라 체인에서만 사용되고 있었지만, 현재는 Aptos, Sui, Celo와 같이 다양한 프로젝트에서 사용되는 등 그 사용성이 확장되고 있는 상황입니다. Sui가 Move를 채택한 이유를 알아보기 이전에, 블록체인 프로그래밍 언어의 특성에 대해 간략하게 살펴보겠습니다.
Solidity, Move, Clarity와 같은 블록체인 프로그래밍 언어는 공개된 시스템인 블록체인의 상태와 상태 간 전이를 표현하는 규칙을 정의합니다. 블록체인은 본질적으로 ‘공개된’ 시스템이기 때문에 누구나 현재의 상태를 확인하고, 상태를 변경하기 위한 트랜잭션을 보낼 수 있습니다. 이는 현실의 자산이 시스템을 통해 접근을 제한하고, 제한된 상황 하에서 개개인이 보유한 자산의 증감을 관리하는 것과 공개성의 측면에서 대조됩니다.

Move는 블록체인 상의 디지털 자산을 관리하기 위한 언어를 표방하고 있는데, 이를 위해 Move가 정의하는 블록체인의 상태는 특정 시점에 유저가 보유한 디지털 자산을 인코딩하고 있습니다. 상태가 표상하는 것이 디지털 자산이기에, 상태 간 전이는 자연스럽게 자산의 전송을 의미하게 됩니다. 하지만 자산의 존재와 그것이 전송되는 것을 정의하는 것만으로는 현실 자산의 속성을 충분히 반영할 수 없습니다. 예컨대, 조개껍질이라는 자산이 바닷가에 존재하고, 해변가에서 조개껍질을 주워 다른 나라에 살고 있는 친구에게 우편물로 전송하는 경우를 생각해볼 수 있습니다. 조개껍질은 여전히 현실에서 자산으로 취급받지 못하며, 자산으로 취급받으려면 (1) 굉장히 희소한 조개 품종의 껍질이고, (2) 해당 조개껍질을 아무나 와서 들고 가지 못한다는 제어 장치가 있어야 할 것입니다.
요컨대, 현실의 자산의 두 가지 중요한 속성 (1) 희소성과 (2) 자산에 대한 접근 제어를 구현하는 것이 디지털 자산이 현실의 자산과 동등하게 취급받을 수 있는 첫걸음이 된다는 것입니다. 만일 두 속성 중 하나라도 지켜지지 않는다면 — 자산이 무한히 복제되거나 소유자가 아님에도 해당 자산을 다른 곳으로 옮길 수 있다면 — 해당 자산은 자산으로서의 가치를 인정받지 못할 것이기 때문입니다. 위의 두 속성이 충족되려면, 최소한 (1) 자산의 총 공급량이 한정되어 있어야 하고(희소성), (2) A가 B에게 X라는 자산을 n만큼 보내는 경우 (i) A가 X 자산을 최소 n개 이상 보유하고 있고, X 자산이 B에게 이동함에 따라 (ii) A가 보유한 X 자산 중 n만큼이 차감되고 (iii) B가 보유한 X 자산에 n만큼이 가산된다는 사실(접근 제어)이 보장되어야 할 것입니다.
비트코인 스크립트의 경우 UTXO를 도입해 위와 같은 이중지불 문제를 해결했고, 이더리움 가상머신의 바이트코드 또한 상태머신의 상태 전이를 통해 위와 같은 문제를 해결했습니다. 기존의 블록체인 언어를 사용하더라도 디지털 자산이 현실의 자산과 동등하게 취급받을 수 있음에도 새로운 Move 언어를 개발한 이유는 무엇일까요? 우선, 비트코인 스크립트의 경우 유저가 다양한 종류의 자산을 생성할 수 있는 자유가 제한적입니다. 이더리움은 이러한 문제를 해결하고 Solidity와 이더리움 가상머신을 사용하는 유저는 본인이 원하는 ERC-20 토큰을 발행할 수 있지만, 이러한 자율성이 되려 자산의 복제, 재사용, 해킹에 따른 소멸 등 여러 보안상 취약점을 야기했습니다. 예컨대, 이더를 스마트 컨트랙트로 전송하는 경우 동적 디스패치가 일어나게 되는데, 이는 재진입 공격과 같은 새로운 양상의 취약점을 생성했습니다. 동적 디스패치와 재진입 공격에 대해서는 아래에서 자세히 서술하고 있습니다.
따라서 기존의 블록체인 언어가 해결하지 못하는 문제점을 해결하기 위해, Move는 아래와 같은 디자인 원칙에 따라 설계되었습니다.
- 일급 객체(First class object)
- 유연성
- 보안성
- 검증 가능성
일급 객체란, 일반적으로 적용되는 연산을 지원하는 객체로, 변수나 데이터 구조 내에 포함할 수 있고, 파라미터나 리턴값으로 사용할 수 있는 등의 특성을 만족하는 객체를 의미합니다. 일반적으로 프로그래밍 언어에서 사용하는 자료형에는 참값(Boolean), 정수(integer), 문자열(string) 등이 있는데, 이와 같은 자료형은 프로그래밍 언어에서 변수, 데이터, 리턴값 등 일반적인 연산에 사용될 수 있습니다. Move의 디자인 원칙이 일급 객체라는 뜻은, Move가 문제를 해결하는 방식이 일반적인 연산이 불가능한 자료구조 및 시스템 구조를 만드는 것이 아닌, 보다 범용성을 가진 방법이라는 것을 의미합니다.
요컨대, Move는 기존의 블록체인 프로그래밍 언어가 자산에 대한 지나치게 간접적인 표현방식을 취하고 있다는 점, 자산의 희소성에 대한 구현을 언어 자체에서 정의하고 있지 않다는 점, 그리고 접근 제어가 유연하지 않다는 점을 해결하기 위해 개발된 언어라고 볼 수 있습니다.
다만 언어가 프로그램으로 변환, 실행되는 과정에서 차이를 보이는바 이를 살펴보겠습니다. Solidity와 Move는 모두 컴파일러를 통해 소스 코드를 기계어로 번역한 뒤, 실행파일을 실행하는 언어입니다. 소스코드와 기계어 중간에 있는 코드를 바이트코드라고 하는데, 이는 0과 1로 표현되는 기계어와 1대1로 대응됩니다. 컴파일 언어는 컴파일을 실행한 뒤 실행한다는 점에서 실행 시 별도의 컴파일 과정을 거치지 않습니다. 따라서 실행 시간은 빠르지만, 규모가 클 경우 컴파일 과정에 부담(Overhead)이 발생할 수 있습니다. 대중적으로 알려진 프로그래밍 언어인 파이썬의 경우 인터프리터(Interpreter) 언어에 해당하는데, 이는 소스 코드를 컴파일러를 통해 한번에 기계어로 변환하는 것이 아니라, 한 줄씩 읽어 실행하는 언어를 의미합니다. 별도의 컴파일 시간이 소요되지는 않으나, 실행파일을 별도로 생성하지 않고 실행할 때마다 각 줄을 읽어 처리하는 과정이 반복적으로 실행되어 컴파일러 언어에 비해 속도가 느리다는 단점이 있습니다.
결론부터 언급드리면, Solidity는 컴파일 과정에서 데이터 타입을 체크하고, 생성된 바이트 코드를 실행하는 반면 Move는 컴파일된 바이트 코드를 바탕으로 데이터 타입을 체크한다는 차이점이 있습니다. 이는 결과적으로 코드에 대한 검증(Verification)을 처리하는 방식에 차이를 야기하는 바, 상기 언급드린 보안성 및 검증 가능성이라는 Move의 디자인 원칙과 관련되어 있습니다.
그렇다면, Sui가 지향하는 1) 병렬 처리 2) 자산 표현이라는 지점이 어떻게 Move와 맞닿아 있는지를 탐구해보기 위해, Move의 구조를 깊게 살펴보려 합니다.
- Move의 구조
Move는 모듈(Module)과 트랜잭션 스크립트(Transaction Script)로 구성되어 있습니다. 모듈은 이더리움의 스마트 컨트랙트와 유사합니다. 모듈 내에는 상기 Move의 특징인 리소스 타입과 해당 리소스를 생성, 수정, 삭제하기 위한 프로시져(Procedure)가 정의됩니다. 모듈은 다른 모듈에서 선언된 프로시져나 타입을 부를 수 있지만, 타입의 경우 모듈 내에서만 접근이 가능하기 때문에 해당 타입을 선언한 모듈 내에서 접근하는 식으로 부르게 됩니다.
트랜잭션 스크립트는 모듈의 프로시져를 호출한다는 점에서 기존 이더리움에서 스마트 컨트랙트의 함수를 호출하는 것과 유사하지만, 보다 유연하게 구성될 수 있다는 점에서 차이점이 있습니다. 예컨대, 이더리움 스마트 컨트랙트는 코드를 실행하는 횟수의 제한을 트랜잭션에 인코딩할 수 없지만, Move의 트랜잭션 스크립트는 이를 인코딩하여 일회성의 트랜잭션을 발생시킬 수 있습니다. 나아가 트랜잭션 스크립트가 일부만 실행되고 멈추는 경우, 이로 인해 발생한 상태의 변화는 전역 상태에 반영되지 않습니다.
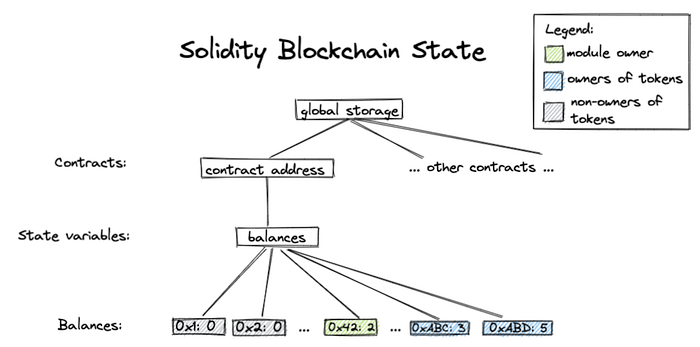
위와 같이 Solidity로 구현된 블록체인의 상태는 각각의 토큰 컨트랙트 주소에 올라간 컨트랙트에서 해당 토큰의 소유자와 잔고를 관리하는 구조입니다.
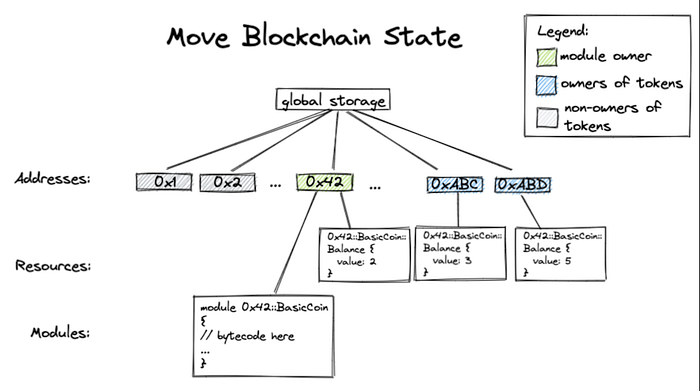
반면 Move로 구현된 블록체인의 상태는 각각의 주소에 모듈이나 특정 토큰의 잔고가 관리되는 형태입니다. 따라서, Solidity가 자산을 거대한 표에 정수를 증감시키면서 토큰의 소유자와 잔고를 변경하는 반면, Move는 자산에 타입을 지정해서 특정 작업을 수행할 수 있습니다.
Solidity는 EVM(Ethereum Virtual Machine)에서 실행됩니다. VM(Virtual Machine, 가상머신)은 프로그램이 실행되는 가상화된 환경으로, 여기서 가상화란 사용자가 프로그램을 실행시키는 환경에 변경을 가할 수 있음을 의미합니다. 예컨대, 현재 글을 작성하고 있는 환경에서는 컴퓨터 메모리에 접근할 때 가장 최근에 접근한 메모리부터 접근하지만 효율성을 위해 이를 가장 자주 접근한 메모리부터 탐색하는 형태의 환경에서도 실행할 필요가 있을 수 있는데, 이때 그러한 환경을 제공하는 것이 가상머신입니다. 보다 간단한 예시로는, 컴퓨터에서 모바일 안드로이드 휴대폰에서 구동되는 어플리케이션을 개발하는 경우, 컴퓨터의 사양이 아닌 해당 휴대폰의 사양에서 구동해볼 필요가 있을 것입니다. 그 경우 휴대폰을 연결하는 것이 아니라 가상머신을 통해 실험을 해볼 수 있습니다. 이와 같이 서로 다른 환경을 사용하는 경우 대부분 가상머신을 사용하는 것이라고 볼 수 있습니다.
보다 추상적으로 살펴보면, 가상머신이 구동될 때 물리적으로 사용되는 컴퓨팅 자원을 보유한 머신을 호스트 머신이라고 합니다. 가상머신은 호스트 머신과 별개의 운영체제를 가질 수 있습니다. 운영체제란 컴퓨터의 자원을 관리하는 프로그램의 일종으로, 흔히 사용하는 Windows나 Mac OS, Linux가 이에 해당합니다. 따라서 운영체제는 커널(Kernel), 컴파일러 등으로 구성됩니다. 요컨대, 가상머신이 다르다는 것은 컴퓨터 자원을 관리할 때 상이한 방식을 취한다는 것을 의미합니다.
Move는 EVM이 아닌 Move VM이라는 별도의 가상머신을 활용합니다. 전술한 바와 같이, 이는 곧 프로그램이 구동되는 양태 및 환경이 다르다는 것을 의미하기에 환경상 어떤 차이점이 존재하는지 식별하는 것이 중요합니다. 환경상의 차이점은 상술한 Move와 Solidity의 차이에서 비롯됩니다. Move는 Solidity에 비해 언어의 표현성에 제약을 두는 대신, 적확한 검증(Verification) 장치를 제공합니다. 이에 관해 아래에서 구체적으로 설명드리겠습니다.
- EVM과 Move VM의 차이
Move VM이 EVM과 대비되는 3가지 주요 특징, (1) 동적 디스패치, (2) 리소스 타입, 그리고 (3) 검증 장치에 대해 알아보겠습니다.
동적 디스패치란, 코드를 실행하는 로직이 컴파일 시점이 아니라 컴파일된 파일이 실행되는 시점(런타임)에서 확정되는 방식을 의미합니다. 이는 다형성(Polymorphism)이라는 강력한 기능을 제공합니다. 다형성이란, 하나의 객체가 여러 타입을 가질 수 있는 특성입니다. 동일한 이름을 가진 함수를 다양한 상황에 정의하여 보다 효율적인 객체 지향 프로그래밍에 기여하는 메소드 오버로딩 등이 다형성이 실제 구현된 예시라고 할 수 있습니다.
이렇듯 동적 디스패치는 프로그래밍 언어의 유연성을 제고하지만, 역으로 보안상 취약점을 발생시킵니다. 상술했던 재진입 공격의 예시를 들어보겠습니다. Solidity는 이진 검색(Binary search)을 통한 동적 디스패치를 지원합니다. 예컨대 특정 컨트랙트로 이더를 전송하는 경우, 이러한 작업이 동적 디스패치를 통해 일어나기 때문에 이러한 전송이 어떤 메소드를 통해서 이루어질지 컴파일 시점에서는 알 수 없고, 실행되는 시점에 비로소 어떤 메소드를 통해 전송되었는지 확인할 수 있습니다. 재진입 공격은 보통 다른 컨트랙트의 fallback 함수를 호출하는 형태로 시행됩니다. 본질적으로 다른 컨트랙트와의 상호작용으로 공격이 이루어지는 것인데, 상기한 바와 같이 동적 디스패치는 컴파일 시점에서 어떤 컨트랙트의 메소드로 특정 작업을 수행하는지 감지할 수 없기 때문에 재진입 공격을 프로그래밍 언어 내지 머신 단에서 방지할 수 없는 것입니다.
나아가, Solidity는 프리 메모리 포인터(Free memory pointer)를 사용해 메모리를 관리합니다. 메모리 포인터는 현재 컴퓨터에서 접근하고 있는 메모리의 위치를 의미하는데, 해당 포인터가 정해지지 않았다는 것은 Solidity의 바이트코드가 처음으로 하는 작업이 포인터의 위치를 확정하는 것임을 의미합니다. 구체적으로 살펴보겠습니다. 메모리의 특정 위치(0x40)에 “프리 메모리 포인터"가 있는데, 이는 해당 포인터가 가리키고 있는 메모리 위치에서 메모리 할당을 시작하는 방식으로 활용됩니다. 이는 곧 해당 메모리가 이전에 사용되지 않았다는 보장이 없고, 메모리에 저장된 값이 0이 아님을 의미합니다. C언어의 경우 메모리를 명시적으로 할당(malloc() 등)하거나 풀어주는(free()) 함수가 있는데, 이와 달리 Solidity는 메모리를 통제하는 별도의 함수가 없습니다. 때문에 Solidity 독스에서는 아래와 같이 어셈블리어를 활용해 메모리를 통제하는 방안을 제시하고 있습니다.
function allocate(length) -> pos {
pos := mload(0x40)
mstore(0x40, add(pos, length)
}다음으로 리소스 타입에 대해 알아보겠습니다. 리소스 타입이란, 상기 Move의 등장배경으로 제기되었던 ‘자산’의 디지털 표현에 대한 문제의식에서 비롯된 것으로 자산을 위한 자료형입니다. Solidity가 토큰의 수량 및 잔고를 정수(integer)의 증감으로 표현하여 ‘자산’이라는 객체에 특수한 제약을 가하기 어려운 반면, Move를 통해 자산을 새로운 자료형, 리소스(Resource) 타입으로 정의하여 특수한 제약을 가할 수 있습니다. 상기 Move로 구현된 블록체인의 상태에서 언급했듯, 리소스는 모듈에서 내부의 데이터를 정의하는 경우 사용되는 자료형입니다. 리소스 타입에 부과되는 제약 조건은 해당 리소스 타입이 선언된 모듈에서만 변경하거나 삭제할 수 있다는 것입니다. 요컨대, (1) 외부 모듈이 리소스 타입의 내용에 변화를 가할 수 없고 (2) 리소스 타입은 변수 사이에서 이동(Move)하거나 함수의 인자로서만 전달될 수 있다는 것입니다. 이러한 제약조건을 통해 리소스 타입으로 정의된 현존하는 토큰의 총량은 유지되거나 소모되기만 한다는 것 — 다시 말해 복제되지 않는다는 사실이 보장됩니다.
리소스 타입이 이동하는 방식은 C++나 Rust의 이동 시맨틱(Move semantic)과 유사합니다. 이는 깊은 복사(Deep copy) 대신 얕은 복사(Shallow copy)를 수행해 무의미한 임시 객체가 메모리를 할당받는 비효율을 막는 방법입니다. 깊은 복사란 변수의 실제 값을 새로운 메모리를 할당받아 복사하는 것을 의미하고, 얕은 복사는 변수의 주소 값을 복사하는 것을 의미합니다. EVM에서도 어셈블리를 통해 얕은 복사를 구현할 수는 있지만, 메모리 위치를 특정하는 형태로 코딩해야 하는 바 이 경우 개발 난이도가 높아지게 됩니다. Move 백서에서 언급한 아래 예시들을 살펴보겠습니다.
public main(payee: address, amount: u64) {
let coin: 0x0.Currency.Coin = 0x0.Currency.withdraw_from_sender(copy(amount));
0x0.Currency.deposit(copy(payee), move(coin));
}해당 함수는 sender로부터 토큰을 인출한 뒤 deposit을 통해 receiver(payee)에게 토큰을 예치하는 함수입니다. deposit은 아래와 같이 이루어집니다.
public deposit(payee: address, to_deposit: Coin) {
let to_deposit_value: u64 = Unpack<Coin>(move(to_deposit));
let coin_ref: &mut Coin = BorrowGlobal<Coin>(move(payee));
let coin_value_ref: &mut u64 = &mut move(coin_ref).value;
let coin_value: u64 = *move(coin_value_ref);
*move(coin_value_ref) = move(coin_value) + move(to_deposit_value);
}위 deposit 함수는 payee의 주소로 토큰을 보내는 함수입니다. 수신자인 payee의 주소, 전송될 토큰인 to_deposit을 인자로 받은 뒤, Unpack을 통해 리소스 타입 객체인 to_deposit을 파괴한 뒤 리턴된 값을 저장합니다. 이때 Unpack은 Move 언어에서 리소스 타입을 파괴할 수 있는 유일한 기능입니다. 그 뒤의 코드는 토큰 자체가 아닌 토큰 리소스의 주소 값을 복사하는 얕은 복사를 활용해 연산을 진행하고 있습니다. 그렇다면, Unpack, move와 같은 메소드는 어떻게 구현이 되는 것일까요? 이를 알아보기 위해서는 Move의 바이트코드 인터프리터와 검증장치를 살펴보아야 합니다.
바이트코드 인터프리터란, 바이트코드를 한 줄씩 읽고 실행하는 프로그램을 의미합니다. Move의 경우 LIFO(Last-in-First-out) 자료구조인 스택을 활용해 인터프리터를 구현하고 있습니다. Move의 바이트코드 역시도 EVM과 유사하게 각각의 명령어마다 가스 유닛 가격이 할당되어 있습니다. 이때 인터프리터는 가스 유닛을 확인하다가 만일 실행 도중에 0이 된다면 실행을 중단시키는 역할을 합니다. Move에 구현된 명령어는 Move 백서의 Appendix. A를 참고하시면 됩니다. 주요 명령어에는 지역 변수를 스택으로 옮기는 CopyLoc, MoveLoc과 그 정반대의 역할을 수행하는 StoreLoc, 그리고 모듈에서 선언한 타입을 생성하거나 파괴하는 Pack, Unpack 등이 있습니다. 이와 같이 명령어의 층위에서 모듈 선언 타입에 대한 기능이 정의되어 있음을 확인할 수 있습니다.
바이트코드와 스택 기반 인터프리터의 특질을 활용해, Move의 바이트코드 검증장치(Bytecode Verifier)는 바이트코드를 기반으로 보안성을 담보하기 위해 여러 검증을 진행합니다. Solidity의 경우 소스 코드가 컴파일될 때 타입 체크를 진행하고, 컴파일러가 바이트코드를 생성한 경우 별도의 타입 체크를 진행하지 않습니다. Move는 이와 달리 컴파일 당시 타입 체크를 진행하지 않고 컴파일을 통해 생성된 바이트코드가 검증장치를 통해 타입 체크를 진행합니다. 이를 통해 얻을 수 있는 보안성을 알아보기 위해, 우선 바이트코드 검증장치가 어떤 방식으로 검증을 진행하는지 알아보도록 합시다.
우선, 검증장치는 기본 블록(Basic block)으로 명령어의 연속 배열을 분해(Control-Flow-Graph Construction)합니다. 기본 블록은 항상 분기(Branch) 혹은 리턴 명령어로 끝나야 하며, 이러한 기본 블록으로 분해된 경우 분기를 통해 도달하는 명령어는 항상 어떤 기본 블록의 시작점이라는 사실이 보장됩니다. 이러한 분해 방식으로 부터 (1) 스택 안전성 (2) 타입 안전성 (3) 리소스 안전성 (4) 레퍼런스 안전성을 확보할 수 있습니다. 각각이 보장되는 방식을 차근차근 살펴보고, 이 중 (3) 리소스 안전성을 중점적으로 살펴보겠습니다.
스택 안전성이란 함수 호출자의 스택에 호출된 함수가 접근하지 못한다는 것을 의미합니다. 이는 검증장치가 스택의 높이를 파악하고 있다가, 특정 조건이 발생했을 때 에러를 발생시킴으로써 보장됩니다. 함수가 호출되기 직전의 스택 높이가 n이라면, 함수가 호출되고 동작이 끝난 경우 스택 높이는 n보다 같거나 커야 합니다. 호출된 함수가 리턴값을 가지는 경우 해당 리턴값이 스택에 저장되어 스택의 높이가 높아질 수는 있지만, 스택의 높이가 n보다 낮다는 것은 호출된 함수가 기존의 스택을 처리했다는 사실을 방증하기 때문입니다.
이를 기반으로 검증장치는 타입 안전성, 즉 각각의 명령어와 함수가 적절한 타입의 인자로 호출되었음을 보장할 수 있습니다. 명령어의 피연산자는 지역 변수(local variable) 혹은 스택에 저장된 변수 중 하나에 해당합니다. 지역 변수의 경우 그 타입이 바이트코드에 인코딩되어 있지만, 스택에 저장된 변수는 그렇지 않습니다. 그러나 스택 변수의 타입 또한 추론될 수 있는데, 이는 상술한 스택 안전성을 통해 가능합니다. 변수의 타입을 저장하는 스택을 활용해서, 기본 블록이 처리됨에 따라 어떤 변수 타입이 스택에 들어가고(push) 나오는지(pop) 확인한다면, 각각의 기본 블록을 처리하면서 등장하는 변수의 타입을 모두 확정지을 수 있을 것입니다.
위의 안전성을 총체적으로 활용해, 리소스 타입의 안전성을 확보할 수 있습니다. 상술했던 것처럼, 리소스 타입 안전성의 핵심은 리소스 타입이 복제되지 않고, 해당 모듈이 아니면 파괴되지 않는다는 점이었습니다. 우선, 타입 안전성을 통해 어떤 변수가 리소스 타입인지 우선 확정지을 수 있습니다. 이를 통해 지역 변수 내지 스택 변수로 저장된 리소스 타입에 대해 복제하거나(CopyLoc등), 해당 타입이 저장된 메모리에 다른 값을 덮어씌워(StoreLoc, WriteRef 등) 결과적으로 리소스 타입을 파괴하는 명령어가 실행되는지 검증장치를 통해 검증할 수 있습니다.
이때 주의해야 할 점은 바이트 코드 검증자는 프로그램의 타입이 잘 정의되었음을 보장할 뿐이지, 실제 프로그램이 의도한 그대로 실행됨을 보장하지는 않는다는 점입니다.
지금까지 Move 언어가 등장하며 제기된 문제와 Move의 어떤 특징과 구조가 그러한 문제를 해결하는지 살펴보았습니다. Move 언어를 활용해 또 다른 층위의 문제를 해결하려는 L1, Sui의 구조를 자세하게 분석하기 전에, Sui의 토크노믹스를 간략하게 살펴보도록 하겠습니다.
3. Sui의 Tokenomics
Sui의 토크노믹스도 특기할 만 합니다. Sui는 토크노믹스의 참여자를 크게 3가지 집단으로 분류합니다. (1) Sui에 트랜잭션을 제출하고, 디지털 자산을 생성, 전송 등 여러 행위를 하는 ‘사용자(Users)’, (2) Sui 토큰을 위임하는 방식으로 PoS에 참여하거나 거버넌스에 참여하는 ‘Sui 토큰 보유자(Holders)’, 그리고 (3) Sui 플랫폼의 트랜잭션 처리와 실행을 담당하는 ‘검증인(Validators)’로 분류된 참가자 모두에게 적합한 인센티브 시스템을 구현하는 것을 목표로 합니다. 이를 위해 구현된 토크노믹스는 크게 5가지 핵심 요소로 구성됩니다. 아래에서 각각에 대해 살펴보고, 이를 통해 Sui 토크노믹스가 어떻게 생태계 참여자들의 인센티브를 촉진하는지 알아보겠습니다.
우선, 토크노믹스의 핵심 구성요소는 아래와 같습니다.
- SUI 토큰: Sui 플랫폼의 기초 자산(Native Asset)입니다. 총 발행량은 10,000,000,000(100억)개로, 지분 증명 매커니즘, 가스 요금 지불, 거버넌스 참여 등에 활용됩니다.
- 가스 요금
- Sui의 Storage Fund
- 지분 증명(Proof-of-Stake) 매커니즘
- 온체인 투표
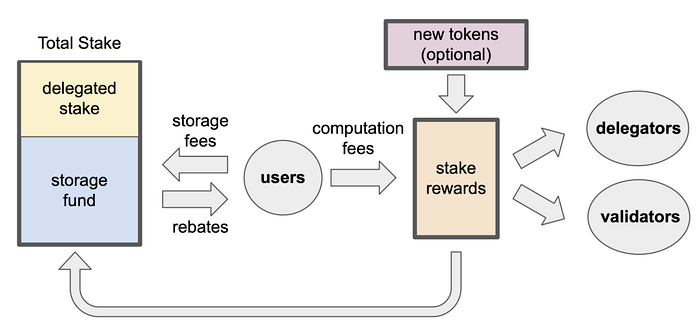
위 구성요소 중, Sui가 다른 메인넷과 차별화되는 지점인 가스 요금과 Storage Fund를 중점적으로 살펴보겠습니다. Sui의 가스 요금 책정 매커니즘은 (1) 저렴하고 사용자가 예측 가능한 수수료를 부과하고 (2) 트랜잭션 처리가 최적화될 수 있도록 검증인에게 적절한 인센티브를 제공하고 (3) 나아가 서비스 거부 공격(Denial of Service, DoS) 등의 공격을 방지하는 것을 목표로 설계되었습니다. 위의 3가지 목표를 달성하는 구체적인 방안은 다음과 같습니다.
다음 글(2. 아키텍처와 컨센서스 엔진)에서 구체적으로 다루겠지만, Sui에서는 Epoch 단위로 검증인들이 표준 가스 요금에 동의해야 합니다. 합의된 표준 가스 요금을 지키지 않는 검증인에게는 페널티를 받고, 반대로 신의성실하게 트랜잭션을 처리한 검증인은 추가 보상을 받습니다. 이로서 위 표준 가스 요금은 사용자에게 신뢰성 있는 가격 지표로 작용합니다.
Sui는 ‘실행(Execution)’과 ‘저장(Storage)’를 분리하고, 각각에 대해 별도의 비용을 지불하는 구조를 가지고 있다는 점에서 Near 프로토콜과 유사합니다. 상기 검증인의 합의로 도출되는 표준 가스 요금은 ‘실행’에 대한 비용을 의미합니다. ‘저장’을 위한 저장소 가격(Storage Prices)은 거버넌스 제안을 통해 설정됩니다. 저장소에 대한 비용은 블록체인 내생변수라기 보다는 외생변수에 가깝기 때문에 외생적으로 저장소에 대한 비용이 절감된 경우 거버넌스 제안을 통해 저장소 가격을 재설정하는 형태를 상정하고 있습니다. Near 프로토콜이 Storage Staking을 통해 해결하는 방법을 제안하고 있는 것과는 사뭇 다른 형태입니다. Near 프로토콜과 관련된 구체적인 내용은 본 글의 범위를 벗어나기 때문에, 첨부 링크를 참고하시면 됩니다.
Sui 토크노믹스의 핵심인 Storage Fund는, 검증인 구성원(Validator Set)이 변화하는 경우도 고려하여 새로운 층위의 지속가능성을 확보했다는 점에서 주목할만 합니다. 현 시점에서 데이터를 처리하는 검증인과 해당 데이터를 저장하는 검증인이 동일하다는 보장이 없기 때문에, 만일 현재 데이터를 처리한 검증인이 ‘실행’에 대한 요금만 지불한다면 미래의 검증인에게 부정적인 네트워크 외부성(Negative Network Externality)이 야기된다는 문제점이 있습니다. 이를 해결하고자 설계된 수단이 Storage Fund입니다. 사용자는 실행과 저장에 대해 선불로 요금을 지불하고, 저장에 지불된 금액은 Storage Fund에 예치되어 검증인들 간 SUI 지분율에 따라 네트워크 보상에 원금이 아닌 지분율을 가산하는 방식으로 검증인에게 인센티브로 제공됩니다. Storage Fund 금액 자체를 보상으로 지급하는 것에 비해 지분율에 따라 비율을 가산하는 방식은 Storage Fund가 고갈되어 다시금 부정적인 네트워크 외부성이 발생하는 사태를 방지합니다. 나아가 Sui의 저장소 모델에 따를 때 사용자는 과거에 저장한 온체인 데이터를 삭제할 때마다 ‘저장’에 대한 비용을 환급받을 수 있기 때문에, 최악의 경우 저장소 비용이 기하급수적으로 증가해 Storage Fund가 정상적으로 작동하지 못하는 경우에도 사용자에 대한 인센티브 구조로 해결될 수 있습니다.
지금까지 Sui와 Move의 등장배경과 기본적인 정보, Move의 구조와 Sui의 연관성을 알아보았습니다. 이어지는 글에서는 Sui의 아키텍처와 컨센선스 엔진을 분석하고, Sui 높은 TPS를 견인하는 병렬처리가 어떻게 이루어지는지, 그리고 이에 따라 Sui가 어떤 특성을 가지는지 알아보겠습니다.
참고문헌
Move 백서
Move github
Solidity docs
Sergey, I. & Hobor, A., “A Concurrent Perspective on Smart Contracts”, Financial Cryptography and Data Security, 2017.
Knecht, Markus & Stiller, Burkhard, “SCUR: Smart Contracts with a Static upper-bound on Resource Usage”, IEEE TrustCom, 2021.
Sui Tokenomics 백서