Nedir Bu Destek Vektör Makineleri? (Makine Öğrenmesi Serisi-2)
Destek Vektör Makineleri (Support Vector Machine) genellikle sınıflandırma problemlerinde kullanılan gözetimli öğrenme yöntemlerinden biridir. Bir düzlem üzerine yerleştirilmiş noktaları ayırmak için bir doğru çizer. Bu doğrunun, iki sınıfının noktaları için de maksimum uzaklıkta olmasını amaçlar. Karmaşık ama küçük ve orta ölçekteki veri setleri için uygundur.
Daha açıklayıcı olması için görsel üzerinde tekrar inceleyelim.

Tabloda siyahlar ve beyazlar olmak üzere iki farklı sınıf var. Sınıflandırma problemlerindeki asıl amacımız gelecek verinin hangi sınıfta yer alacağını karar vermektir. Bu sınıflandırmayı yapabilmek için iki sınıfı ayıran bir doğru çizilir ve bu doğrunun ±1'i arasında kalan yeşil bölgeye Margin adı verilir. Margin ne kadar geniş ise iki veya daha fazla sınıf o kadar iyi ayrıştırılır.
Formüle bakacak olursak:

Aslında değişen pek bir şey yok. w; ağırlık vektörü (θ1), x; girdi vektörü, b; sapmadır (θ0). Yeni bir değer için çıkan sonuç 0'dan küçükse, beyaz noktalara daha yakın olacaktır. Tam tersi, çıkan sonuç 0'a eşit veya büyükse, bu durumda siyah noktalara daha yakın olacaktır.
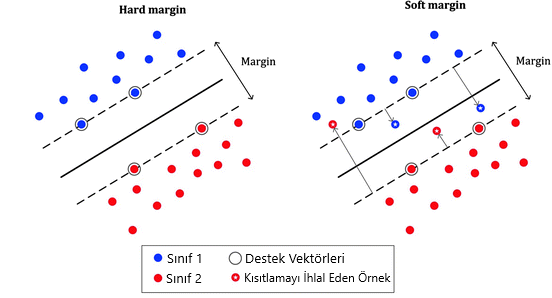
Hard Margin vs Soft Margin
Marginimiz her zaman bu şekilde olmayabilir. Bazen örneklerimiz Margin bölgesine girebilir. Buna Soft Margin denir. Hard Margin, verimiz doğrusal olarak ayrılabiliyorsa çalışır ve aykırı değerlere karşı çok duyarlıdır. Bu yüzden bazı durumlarda Soft Margin’i tercih etmemiz gerekebilir.

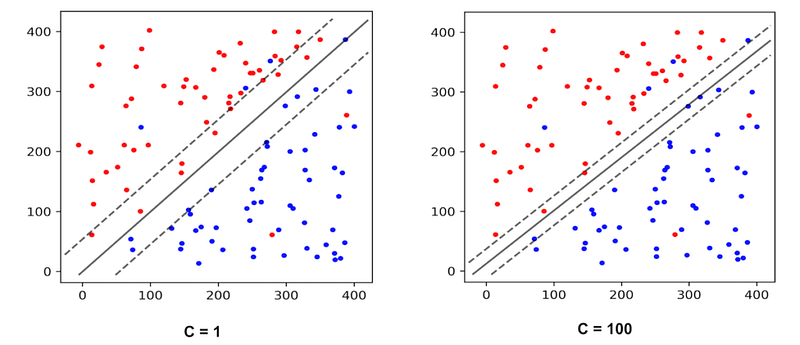
İkisi arasındaki dengeyi SVM içerisindeki C hiperparametresi ile kontrol edebiliriz. C ne kadar büyükse Margin o kadar dardır.

Ayrıca model overfit olursa C’yi azaltmamız gerekir.
Kernel Trick
Düşük boyutlar karmaşık veri setlerini açıklamada yeterli olmayabilir. Boyutu arttırsak işlemler artacağı için çok uzun sürer. İşte Kernel Trick burada devreye giriyor. Elimizdeki koordinatları belirli Kernel Fonksiyonları ile çarparak çok daha anlamlı hale getirebiliyoruz.
Bu yöntemlerden en çok kullanılan ikisini detaylı olarak açıklayacağım.
1-) Polynomial Kernel:
Bu yöntemde problemimizi çözmek için 2 boyuttan çıkıp 3 veya daha fazlası boyutta işlem yapıyormuş gibi hareket ediyoruz.

Soldaki (2 boyut) dağılımı bir doğru ile sınıflandıramayız. Bunun için bu gibi problemlerde Polynomial Kernel’i kullanabiliriz. 3. boyutta işlem yaparken sınıflara ayırmak için doğru yerine bir düzlem kullanılırız ve çok daha düzgün bir şekilde sınıflandırabiliriz.
Modelimiz overfit olmuşsa derecesini düşürmeniz, underfit olmuşsa derecesini yükseltmeniz gerekir. Ayrıca coef0 hiperparametresiyle modelinizin yüksek dereceli denklemlerden ne kadar etkileneceğini ayarlayabilirsiniz(sadece ‘poly’ ve ‘sigmoid’ kernelda etkili olur).
2-) Gaussian RBF (Radial Basis Function) Kernel:
Anlaması biraz güç olabilir ama sonsuz boyuttaki Destek Vektör Makinelerini bulur ve her bir noktanın belirli bir noktaya ne kadar benzediğini normal dağılım ile hesaplar, ona göre sınıflandırır. Dağılımın genişliğini gamma hiperparametresi ile kontrol ederiz. Gamma ne kadar küçükse dağılım o kadar geniş olur. C hiperparametresindeki gibi, model overfit olmuşsa gamma değerini düşürmemiz, model underfit olmuşsa gamma değerini yükseltmemiz gerekir.

Veri setiniz aşırı büyük değilse genellikle RBF Kernel tercih edilir.
ÖZET:
1-) Destek Vektör Makineleri (SVM), düzlem üzerindeki noktaların bir doğru veya hiper düzlem ile ayrıştırılması ve sınıflandırılmasıdır.
2-) Küçük veya orta büyüklükteki veri setleri için uygundur. Scale’e duyarlıdır. Scale edilmesi gerekir.
3-) Hard Margin ve Soft Margin arasındaki dengeyi C ile kontrol edebiliriz. C büyüdükçe Margin daralır.
4-) Model overfit olursa C’nin azlatılması gerekir.
5-) 2 boyutta açıklanamayan değişimleri boyut arttırarak çözüyormuş gibi yapılan hilelere Kernel Trick denir.
6-) 2 boyutta açıklayamadığımız veri setimizi daha fazla boyutta açıklamak için kullanılan Kernel Trick metoduna Polynomial Kernel denir.
7-) Model overfit olursa derecesi düşürülür, underfit olursa derece yükseltilir. Coef0 hiperparametresi ile yüksek dereceli denklemlerden ne kadar etkileneceğini ayarlayabilirsiniz.
8-) Her bir noktanın belirli bir noktaya ne kadar benzediğini normal dağılım ile hesaplayan, ona göre sınıflandıran Kernel Trick metoduna RBF Kernel denir.
9-) Dağılım genişliğini kontrol ettiğimiz gamma değeri ne kadar küçükse dağılım o kadar geniş olur. Model overfit olmuşsa gamma değerini düşürmemiz, model underfit olmuşsa gamma değerini yükseltmemiz gerekir.
10-)

SVM Uygulama:
Destek Vektör Makineleri bu kadardı. Okuduğunuz için teşekkür ederim.
Esen Kalın.

{kind=link}
{kind=link}
{kind=link}
{kind=link}