Shakespeare, Maymunlar ve Genetik Algoritmalar

Bu yazıda Genetik Algoritmalardan; nasıl çalıştığından ve optimizasyon konusundaki yeteneklerinden kısaca bahsedeceğiz. Ayrıca yazının sonunda basit ve eğlenceli bir Python uygulamasıyla da öğrendiklerimizi uygulayacağız. Başlamadan önce: başlıktaki kavramlar birbirleriyle ilgiliymiş gibi gözükmüyor olabilir. Fakat sabırla okumaya devam edin ve Shakespeare’in unutulmaz eserlerinden biri olan Hamlet’in, yapay zeka ile yollarının nasıl kesiştiğini hep birlikte keşfedelim. 😊
Biyolojik Bir Problem Çözücü
Genetik Algoritmalar (GA), 1970’li yıllarda John H. Holland ve üniversitedeki çalışma arkadaşları tarafından geliştirilmeye başlanmış bir optimizasyon (iyileme) yöntemidir. Günümüzde optimizasyon denilince akla gelen ilk algoritmalardan birisidir. Bunun en büyük sebebi GA’nın doğrudan doğal yaşamdan, yani canlılığı oluşturan genetik materyallerin sorun çözme yöntemlerinden esinlenerek ortaya çıkarılmış bir algoritma olmasıdır, hiç şüphesiz. Burada ‘sorun’ ile kastedilen şey, canlının yaşadığı ortama ayak uydurmaya çalışmasıdır. Eğer canlının genetik özellikleri, onu hayatta tutacak kadar yeterli işlevleri (örn. anatomik özellikler) sağlıyorsa, kendinden sonra yerini alacak nesillere genlerini aktarabilecek şansa sahip olabiliyor. Kendini doğal ortama adapte edebilmiş her başarılı nesil, geçmiş nesillere göre biraz daha ‘optimize’ edilmiş genlerini sonraki nesillere aktarıyor. Sonuç olarak bu durum doğal seçilim denilen, doğanın canlı popülasyonlarını daha kaliteli bireyler için optimize ettiği bir sürece dönüşüyor. (Şekil 1)

Genetik Algoritmaların Özellikleri
GA, evrimsel süreçleri modellemeye çalışan bir algoritmadır. Bu alanda daha geniş kapsamlı çalışmalar, yapay zekanın da bir alt alanı olan ‘Evrimsel Hesaplamalar’ alanı altında yapılmaktadır. Genel hatlarıyla bir evrimsel süreç, aşağıdaki 3 kavram çerçevesinde ele alınabilir:
- Kalıtım: Bireylerin genetik özelliklerini kendilerinden sonraki nesillere aktarabilmesi.
- Çeşitlilik: Bir popülasyondaki bireylerin, birbirlerinden ayırt edilebilecek şekilde farklı özelliklere sahip olabilmesi.
- Seçilim (Seleksiyon): Bulunduğu ortama adapte olabilmiş seçkin bireylerin, kendinden sonraki nesilleri oluşturmaya aday olmasının sağlanması. En iyilerin hayatta tutulması.
Bu özellikler GA’nın oluşturulma sürecinde de birer karşılık bulur. Benzer şekilde canlıların hayatta kalma sorunu, bizim için çözümlemek istediğimiz problemin bir benzetimidir. Yani algoritmanın çözüm için istediğimiz değerlere ulaşmaya çalışması, aslında bir çeşit ‘hayatta kalma’ yarışından ibarettir.
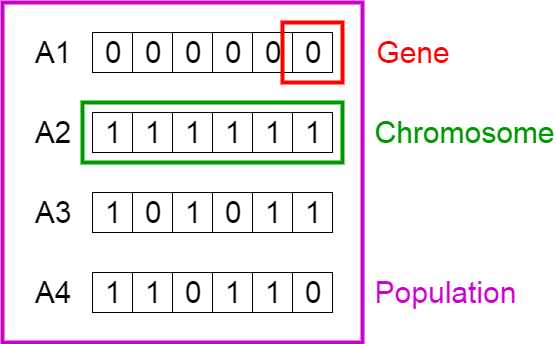
Bu kavramların da altında, genetik mekanizmaları sürdüren yapıtaşları vardır. Bunların bir kısmı GA’ya da aynı şekilde dahil edilmiştir ve aralarındaki hiyerarşi şu şekildedir (Şekil 2):

- Gen: Bireylerin özelliklerini belirleyen ve kalıtımla aktarılan birimler. Genellikle her bir gen bit olarak ifade edilir.
- Kromozom: Birden fazla genin bir araya gelmesiyle oluşan gen dizisi. Popülasyondaki bireylerin her biri. Her bir kromozom, problemin çözümünü temsil eden bir çözüm adayıdır. (Bkz. represantation)
- Popülasyon: Kromozomların bir araya gelmesiyle oluşan birey topluluğu. Olası çözümleri barındıran bir çözüm kümesi. Popülasyonun büyüklüğü, problem için belirlenen parametreler doğrultusunda seçilir.
GA’da oluşturulan popülasyonlar her nesilde bir değerlendirme sürecine tabi tutulur. Bu süreç, kromozomların (bireylerin) hayatta kalmaya ne kadar elverişli oldukları, diğer bir deyişle problemin çözümü için ne kadar uygun olduklarını saptamak içindir. Uygunluk değeri (ing. fitness) kavramı, GA’nın kilit noktalarından biridir. Çünkü GA; karmaşık matematiksel modeller yada üzerinde çalışılacak sistemi tanımlayan ön bilgiler olmadan, sadece uygunluk değeriyle çalışabilir. Bu yüzden uygunluk değerinin ölçümü ve değerlendirilmesi çok önemlidir. Uygunluk değerini ölçmek için kullanılan fonksiyonlara uygunluk fonksiyonu adı verilir. Uygunluk fonksiyonun oluşturulması yine problemin yapısına dayalıdır. Örneğin, GA’nın sıkça kullanıldığı yol bulma (ing. Path finding) uygulamalarında; bireylerin bulunduğu konum ile varış noktası arasındaki mesafeyi hesaplayan bir fonksiyon, uygunluk fonksiyonu olarak kullanılabilir. Bu durumda fonksiyondan alınan değerlerin 0’a yakınsaması, bireylerin hedefe daha çok yaklaştığı anlamına gelir ve bu da yüksek uygunluk değeri demektir.
Rastgelelik
GA’nın literatürdeki diğer bir tanımı ‘yönlendirilmiş rastgele arama algoritması’ şeklindedir. [1] Buradaki rastgelelik, doğal süreçlerin sitokastik (olasılıksal) parametrelere bağlı olmasından dolayıdır. Örneğin, popülasyonlarda çeşitliliği sağlayan en önemli olaylardan biri rastgele gerçekleşen mutasyon olayıdır. Çeşitliliğin daha çok sağlanması için yalnızca bireylerin kendi aralarında çoğalması (çaprazlama) yeterli olmaz. Çünkü belirli noktalardan sonra bu bireylerin birbirinin kopyası olmaya başlaması kaçınılmaz olabilir. Çeşitlilik için çaprazlamaya ek olarak mutasyonların gerçekleşmesi, yani bireylerin genetik özelliklerinin belirli oranlarda ‘güncellenmesi’ gerekir. Bu süreç, bir gereklilik olarak karşımıza çıksa da, aslında gereklilik olduğu için çalışmaz. Çünkü gerçekte mutasyonun oluşması, genlerin olması gerekenden farklı -hatalı- şekilde dizilmesinden kaynaklanır. (Şekil 3) Bazı dış etkenler yoluyla da (örn. radyasyon) mutasyonlar gerçekleşebilir.

Sonuç olarak; yeni bireylerin oluşması aşamasında kopyalanan genler, yüzde yüz doğrulukla kopyalanamadığı için birey mutasyona uğramış olur. Yani güncellenir. Bu güncellemelerin nerede ve ne şekilde olacağı ancak olasılıksal olarak öngörülebilir. Çünkü mutasyonları tetikleyen olayların kaynağı, rastgele gerçekleştiğini gözlemlediğimiz süreçlere dayanmaktadır. Mutasyonların sonucunda ortaya çıkan durum, canlının doğal ortama adapte olabilmesine pozitif etkilerde bulunabileceği gibi, negatif etkileri de olabilir. Kanser hastalığı, mutasyonların negatif etkilerine bir örnektir. Nitekim, GA’da gerçekleşen rastgele mutasyonların da, her zaman doğru sonuçlar ortaya çıkarmayacağını öngörmek gerekir.
Genetik Operatörler
GA’nın işlerliğini yürütebilmek için uygunluk fonksiyonunun yanı sıra, aday popülasyonundaki bireylerin (çözüm adaylarının) gelişimini sağlayacak çaprazlama ve mutasyon işlemlerine de ihtiyaç duyarız. Bu gibi süreçleri yürüten birimlere genetik operatörler denir. Burada genel olarak kullanılan mutasyon ve çaprazlama operatöründen bahsedeceğiz, fakat literatürde özel amaçlara yönelik geliştirilmiş çok çeşitli genetik operatörler bulunduğunu da not edelim.
- Mutasyon Operatörü: Nesiller boyunca çeşitliliğin sağlanması ve çözüme yönelik ideal değerlere ulaşma ihtimalini arttırmak için mutasyon operatörü kullanılır. Genel olarak; kromozom içinden rastgele seçilen (mutasyon oranına göre) genlerin değerinin, yeni değerlerle değiştirilmesi esasına dayanır. (Şekil.4.A) Diğer bir yöntemse, seçilen genin aynı kromozom içinden başka bir genle yer değiştirmesidir. (Şekil.4.B)


- Çaprazlama Operatörü: Uygunluk değeri yüksek ebeveyn bireylerden, yine uygunluk değeri yüksek yeni bireyler oluşturmak için kullanılan bir operatördür. Popülasyon içinden seçilen yüksek uygunluktaki iki birey, kromozomlarının rastgele noktasından seçilmiş (çaprazlama noktası) genlerini birbirleriyle birleştirerek yeni çocuk bireyler elde edebilir. (Şekil 5) Çaprazlanacak iki bireyin nasıl seçilebileceği konusunda epey yöntem bulunmaktadır. Örneğin rulet tekerleği seçimi bunlardan en bilinenidir. Bu konu fazlaca detay içerdiğinden, bu yazının kapsamı dışında bırakılmıştır. Fakat daha fazla bilgi edinmek isterseniz, şu yöntemler de ilginizi çekebilir: Ağırlıklı seçim, eşik değer seçim, turnuva seçimi, seçkinlik (elitism).

Bütün bu bilgiler ışığında, basit bir Genetik Algoritmanın çalışması şu şekilde özetlenebilir(Şekil 6):
- Rastgele adaylardan oluşan başlangıç popülasyonu oluşturulur. (Initialization)
- Adayların uygunluk değerleri hesaplanır.
- Doğal seçilim yoluyla en iyi adaylar seçilir (Selection) ve çaprazlanır. (Crossover)
- Çaprazlama sonucu oluşan yeni bireyler mutasyona uğratılır (Mutation) ve ebeveynlerinin popülasyondaki yerlerini almaları sağlanır.
- Adayların uygunluk değeri yeniden hesaplanır. Bu işlemler, adayların çözüme istenilen seviyede yakınsaması sağlanana kadar tekrar ettirilir. (Termination)

Uygulama: Sonsuz Maymun Teoremi

Sonsuz maymun teoremi (ing. infinite monkey theorem), bir maymunun daktilonun tuşlarına rastgele basarak Shakespeare’in Hamlet oyununu başından sonuna, yazım hatası bile olmadan yazabileceğini gösteren olasılıksal bir matematik teoremidir. İnanması güç gelebilir, fakat sonsuz bir zaman çizelgesinde bu durumun gerçekleşmemesi için matematiksel açıdan herhangi bir sebep bulunmuyor. Çünkü durumlar arasından en az birinde, maymunun tek seferde yaklaşık 300.000 karakterden oluşan Hamlet oyununu yazabileceği bir ihtimal var. Tabi ki bu ihtimal oldukça küçük, fakat kesinlikle ‘0’ değil.
Teoremle ilgili matematiksel ispatı buradaki videodan seyredebilirsiniz.
Peki bunun konumuzla ilgisi ne? Acaba, Genetik Algoritmaları kullanarak kendi oluşturduğumuz sanal maymunlarımıza Hamlet’i yazdırabilir miyiz? Bu yazıyı okuduğunuza göre, cevabımız evet.
Fakat… Hamlet’in tamamını Genetik Algoritmalarla bile yazmaya çalışmanın devasa bir zaman ve performans maliyeti olduğu için, biz bu örneği biraz daha basitleştirelim ve Hamlet’te geçen unutulmaz sözlerden birini: “Olmak ya da olmamak.” sözünü yazdırmaya çalışalım.
Öncelikle, maymunların genlerinin alacağı değerleri üreten bir fonksiyon ve her bir kromozomu (bireyi) temsilen ‘Chromosome’ sınıfını ‘classes.py’ dosyasında oluşturmakla işe koyulalım:

- ‘new_char’ fonksiyonu: ASCII tablosundaki büyük-küçük harflerin bulunduğu 63–122 satır numaralarındaki karakterlerden rastgele birini seçer ve geri döndürür. (63 ve 64 no’lu karakterler kullanılmayacağı için doğrudan nokta ve boşluk karakterine dönüştürülür.)
- ‘self.genes’ her biri ASCII tablosundaki karakterlerden biri olan genleri, ‘self.fitness ’ kromozomun uygunluk değerini, ‘self.target’ ise yazılacak cümleyi tutan özelliklerdir. Aşağıdaki döngü ile hedef cümlenin karakter sayısı kadar (19) gen oluşturulur.

- ‘fit_func’ uygunluk fonksiyonudur. Kromozomun genlerinin her biri için hedef cümleyi oluşturan eş sıralı karakterlerle eşleşip eşleşmediği kontrol edilir. Eşleşen durumlar, o genin doğru bir değer taşıdığını gösterir ve ‘score’ değeri bir arttırılır. Uygunluk değeri, skor değerinin toplam karakter sayısına oranıdır.

- Son olarak Chromosome sınıfımıza çaprazlama ve mutasyon operatörlerini de ekleyelim. Bu metotların çalışması, yukarıda açıklanan şekildedir.
- Şimdi de oluşturduğumuz Chromosome sınıfından türetilecek kromozomları tutan popülasyon sınıfını oluşturalım. Bu örnekte bir maymun popülasyonunu temsil ettiği için ‘Monkeys’ şeklinde isimlendirmeyi tercih ettim.

- ‘best_score_global’ değeri bütün nesillerde aranan en iyi uygunluk değerini, ‘best_score_local’ mevcut nesildeki en iyi uygunluk değerini ve self.monkeys listesindeki indeksini, ‘best_phrase’ mevcut neslin üretebildiği en iyi cümleyi, ‘mating_pool’ ise çaprazlanacak bireylerin tutulacağı değişkenlerdir.

- ‘calc_fitness’ her bir bireyin uygunluk değerini hesaplayan ve lokal en iyi değeri bulan metot; ‘natural_selection’ ise doğal seçilim işlevini yürüten ve bireyleri uygunluk değerleriyle orantılı şekilde çaprazlama havuzuna kopyalayan metottur. Bu orantılı kopyalama sayesinde; uygunluk değeri yüksek seçkin bireylerin, üreme için daha çok öne çıkan adaylar olması sağlanır.

- ‘generate’ metodu çaprazlama işlemini ve bunun ardından üretilen yeni bireylerin mutasyona uğramasını sağlayan metotdur. Yeni nesiller, bu metotla popülasyona kazandırılır.

- ‘evaluate’ ise bir diğer değerlendirme metodudur. Bireylerin hedef cümleyi üretip üretemediğini değerlendirir. Eğer istenilen hedefe ulaşıldıysa, ‘finished’ değerini doğrulayarak bütün süreci sonlandırır.
Bu sınıfı da tamamladıktan sonra, son olarak uygulamamızın asıl çalıştırılacağı dosya olan ‘main.py’ dosyasına geçelim ve buradaki ayarlamaları yapalım.

- Maksimum nesil, popülasyon büyüklüğü, mutasyon oranı parametrelerini ve hedef cümleyi tek tek belirliyoruz. Buradaki parametrelerin belirlenmesi yine GA’daki bir başka önemli konudur. Seçilecek değerlerin ne kadar ideal olduğu, problemin yapısına bağlıdır. Dolayısıyla parametreler hassas şekilde ayarlanmak isteniyorsa, problem ve elimizdeki verilerle ilgili daha detaylı analizler yapmak gerekebilir. Bizim burada belirlediğimiz değerler, genel olarak kullanılan ve önerilen değerlerdir.
- Siz de bu parametrelerle oynayarak, algoritmanın performansının nasıl değiştiğini gözlemleyebilirsiniz.

- Son olarak oluşturduğumuz adımları bir döngü içerisinde, belirlediğimiz maksimum nesil sayısı kadar çalıştıralım. Her neslin en iyi adayını ve neslin ortalama uygunluk değerini ekrana yazdıralım. İşlem tamamlandığında da; toplam kaç nesil oluşturulduğunu ve geçen zamanı ekrana yazdıralım.

Ve sonuç… Maymunlarımız başarılı bir şekilde hedef cümleyi ‘rastgele tuşlara basarak’ yazmayı başardı. Tabii bu sonuç, Genetik algoritmaların rastgeleliği istenilen sonuçlara başarılı bir şekilde yönlendirebilmesinin bir eseri. Siz de bu uygulamayı, 'phrase' değişkenine başka cümleler -örneğin kendi isminizi- atayarak deneyebilirsiniz.
Uygulamanın kaynak kodlarına buradan ulaşabilirsiniz.
Ek olarak bu yazı ilginizi çektiyse, GA’ya oldukça benzer algoritmalardan bir diğeri ‘Yapay Bağışıklık Sistemi Algoritmaları’ hakkında daha önce yazdığım yazıya da buradan ulaşabilirsiniz.
Kaynaklar
- [1] Prof. Dr. Derviş Karaboğa, Yapay Zeka Optimizasyon Algoritmaları
- [2] Daniel Shiffman, Genetic Algorithm: Shakespeare Monkey Example

{kind=link}