YOLO Algoritmasını Anlamak
Son yıllarda nesne tespiti alanında revaçta olan YOLO (You Only Look Once) algoritmasını ister istemez duymuşsunuzdur. Bu algoritma neden bu kadar popüler? Sebebi tahmin edebileceğiniz gibi tabii ki iyi olması. Peki bu zamana kadar olan algoritmalar kötü müydü? Hayır, YOLO’dan önce de şu anda da YOLO’dan iyi tahmin yapabilen algoritmalar vardı fakat temel sorun yavaş olmalarıydı. YOLO’yu diğer algoritmalardan ayıran en önemli özelliği gerçek zamanlı nesne tespiti yapabilmesi oldu. Peki YOLO’dan önce hiç gerçek zamanlı nesne tespiti yapabilen bir algoritma yok muydu? Vardı fakat genel ortalama kesinlik (mAP) değerleri yeterli değildi.

Yukarıdaki resimde YOLOv3 ve diğer algoritmaların COCO veri setinde 0.5 IoU (mAP-50) ile karşılaştırmasını görüyorsunuz. Grafikten de anlaşılacağı üzere YOLO rakiplerine karşı süre ve doğruluk açısından çok iyi durumda. Ayrıca istersek doğruluk ve hız arasında rahatlıkla takas yapabiliyoruz.
Peki YOLO nasıl hem bu kadar hızlı tahminler yaparken aynı zamanda çok iyi sonuçlar verebiliyor? Öncelikle isterseniz diğer algoritmaların neden yavaş olduğuna bakalım. Örneğin R-CNN gibi bölge bazlı nesne tespit algoritmaları önce nesne bulunması muhtemel alanları belirleyip ardından oralarda ayrı ayrı CNN (Convolutional Neural Network, Evrişimsel Sinir Ağları) sınıflandırıcıları yürütüyor. Bu yöntem her ne kadar iyi sonuçlar verse de bir resim iki ayrı işleme tabi tutulduğu için resim üzerindeki işlem sayımız artıyor ve düşük bir FPS (Frames per second, saniye başına kare) almamıza sebep oluyor.

Eğer isterseniz R-CNN’den sonra gelişmiş versiyonları olan Fast R-CNN ve Faster R-CNN algoritmalarında ayrı ayrı segmentasyon ile belirlenmiş bölgeler yerine tüm resmi tek seferde CNN yapısından geçirip ardından önceden yazılmış Region Proposal Network’e gönderen yapısıyla bu işlemi nasıl hızlandırdığını araştırabilirsiniz fakat algoritmaların içine bu yazıda girmeyeceğim.
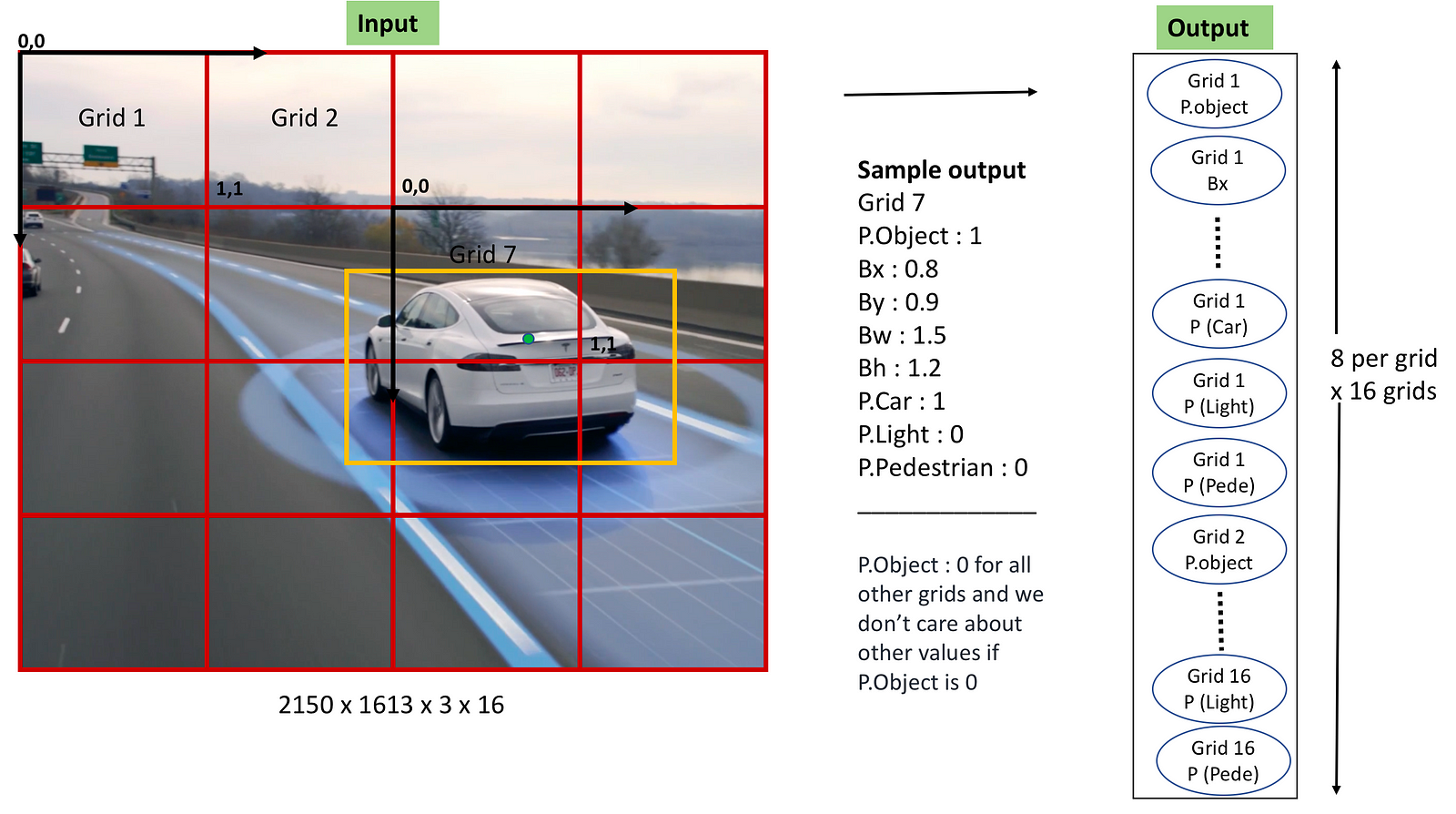
Sonuç olarak Faster R-CNN algoritması bile gerçek zamanda ortalama 7 FPS ile çalışıyor. YOLO algoritmasının bu kadar hızlı olmasının sebebi resmi tek bir seferde nöral ağdan geçirerek resimdeki tüm nesnelerin sınıfını ve koordinatlarını tahmin edebiliyor. Yani bu tahmin işleminin temeli, nesne tespitini tek bir regresyon problemi olarak ele almalarında yatıyor. Bunu yapmak için ilk önce girdi resmini SxS‘lik ızgaralara bölüyor. Bu ızgaralar 3x3 5x5 19x19 vs. olabilir. Buna bağlı olarak isterseniz resim nöral ağdan geçtikten sonra elimize geçen vektörü inceleyelim:

Her bir ızgara kendi içinde, alanda nesnenin olup olmadığını, varsa orta noktasının içinde olup olmadığını, orta noktası da içindeyse uzunluğunu, yüksekliğini ve hangi sınıftan olduğunu bulmakla sorumlu. Daha açık anlatmak gerekirse örneğin yukarıdaki resimde arabanın orta noktası 7. ızgaraya denk geldiği için arabanın tespit edilmesinden/etrafına kutucuk çizmesinden o ızgara sorumlu.
Buna göre YOLO her ızgara için ayrı bir tahmin vektörü oluşturur. Bunların her birinin içinde:
Güven skoru: Bu skor modelin geçerli ızgara içinde nesne bulunup bulunmadığından ne kadar emin olduğunu gösterir. (0 ise kesinlikle yok 1 ise kesinlikle var) Eğer nesne olduğunu düşünürse de bu nesnenin gerçekten o nesne olup olmadığından ve etrafındaki kutunun koordinatlarından ne kadar emin olduğunu gösterir.
Bx: Nesnenin orta noktasının x koordinatı
By: Nesnenin orta noktasının y koordinatı
Bw: Nesnenin genişliği
Bh: Nesnenin yüksekliği
Bağlı Sınıf Olasılığı: Modelimizde kaç farklı sınıf varsa o kadar sayıda tahmin değeri. Örn;
Yukarıdaki resimde Grid 7’ ye baktığımızda eğer araba olduğundan kesin olarak eminse:
Araba: 1, Yaya: 0 olacaktır.
Devam etmeden önce güven skoru nasıl hesaplanıyor onu görelim:
Güven skoru = Kutu Güven Skoru x Bağlı Sınıf Olasılığı
Kutu Güven Skoru = P(nesne) . IoU
P(nesne) = Kutunun nesneyi kapsayıp kapsamadığının olasılığı. (Yani nesne var mı yok mu?)
IoU = Ground truth ile tahmin edilmiş kutu arasındaki IoU değeri
Yani aslında hiçbir nesne olmayan ızgaralarda bağlı sınıf olasılığı 0 olması gerektiği için (aslında arka plan olarak tespit ediliyor) güven skoru 0 olacaktır.
Yukarıdaki çıktı vektörüne göre her bir ızgara sadece 1 tane nesne tanımlayabiliyor. Örneğin sadece 3x3’lük bir ızgara kullansaydık 9 tane nesne tahmini yapabilirdik. Peki bir ızgarada birden fazla nesne varsa ne olacak? Hatta bir ızgarada 2 farklı nesnenin orta noktası bulunursa ne olacak diye sorsak daha mantıklı olur.
Bu sorun ise YOLOv2’ de algoritmaya monte edilen Anchor Box’ları ile çözülüyor. Anchor Boxes methodu ilk olarak Faster R-CNN’ de kullanılmış ve mantığında el ile seçilmiş belli kalıpların yardımıyla nesnenin etrafındaki kutuyu tahmin etmemiz yatıyor. Ayrıca her bir ızgarada önceden belirlenmiş anchor box sayısı kadar tahmin yapıyoruz.

Anchor Box’larının da gelmesiyle çıktı vektörümüz şu şekilde şekilleniyor:
S x S x ( #A x (5 + #C )
Yani S x S toplam ızgara sayısını belirttiğine göre her bir ızgara için anchor box sayısı kadar Güven, x, y, w, h ve diğer sınıflar için olasılık hesaplayacağız. Yukarıdaki resimde 2 tane anchor box ve orta noktası aynı ızgaraya denk gelmiş iki tane nesne görüyorsunuz. İnsan şekli birinci anchor box’a araba ise ikincisine daha çok benzediği için de o ızgaranın vektörü de resimdeki gibi oluyor diyebiliriz. (Sarı kısım 1. Anchor box yeşil ise 2. si için) Anchor box’a ne kadar benzediğini hesaplamak için de IoU kullanıyoruz.
Amacımız tespit edilen nesnenin etrafına bir kutu çizmek olduğunu ve aynı zamanda bu kutuların belirli yükseklik-genişlik oranları olduğunu biliyoruz. YOLO v1’de nesnelerin etrafındaki kutuları ağın sonunda kurulu olan birbirine bağlanmış katmanlar ile direkt tahmin ediyorduk. Fakat artık anchor box’lar da elimizde olduğuna göre direkt olarak nesne kutucuğunun en benzediği anchor box’u bulup o kutucuğun anchor box’a göre yükseklik ve genişlik çıkıntılarını/farkını tahmin edebiliriz. Bu şekilde de YOLO v1’deki erken eğitme safhalarında karşımıza çıkan kararsızlık problemini azaltıyoruz. (Daha fazla bilgi için YOLO paper’ına bakabilirsiniz)
Bu tahminlerin pratikte yerini bulması için göreceli bir sistem kurulması gerekiyor. Elimizde neler var? Tx, Ty, Tw ve Th zaten her bir kutucuk için ağ tarafından tahmin ediliyor. Aynı zamanda işlem yaptığımız ızgaranın hangi ızgara olduğunu da biliyoruz, buna göre de ızgaranın sol üst köşeye olan uzaklığını bulabiliriz. Bu uzaklıklara da Cx ve Cy diyelim. Önceden belirlediğimiz anchor box’un genişlik ve yüksekliklerine Pw ve Ph dersek sistemimiz şu şekilde kuruluyor:

Ayrıca bu gördüğümüz sistemle parametreleri 0 ile 1 arasında normalleştirdiğimiz için ağımız daha kararlı oluyor ve bu parametreleri daha kolay öğreniyor.
Buraya kadar YOLO’nun her bir ızgara için nesne kutularını nasıl tahmin ettiğini ve bir kutu için kaç tane tahmin yaptığı hakkında genel bir fikrimiz oldu. Fakat algoritma çalışırken çok fazla gereksiz kutular çıkacaktır hatta sadece bir nesne için birkaç farklı kutu bile çıkabilir. Gereksiz kutuları atmak kolay olacaktır, zaten elimizde o ızgaranın içinde nesne olup olmadığını tahmin eden bir parametre var fakat ızgaranın içinde nesne varsa ve aynı nesne için birden fazla ızgara o nesnenin orta noktası olduğunu düşünürse ne olacak?

Burada devreye Non max Suppression algoritması devreye giriyor. İsterseniz gelin algoritmaya bakalım:
1-) Güven skoru belli bir seviyenin altında olan tüm kutuları at (örn. 0.5)
Kutu kaldığı sürece:
1-) En yüksek güven skorlu kutuyu seç ve onu çıktı olarak ver. Bu kutuya A diyelim.
2-) A ile IoU değeri 0.5’ten fazla olan diğer tüm kutuları at
Bu işlem sonucunda da elimizde her nesne için bir tane kutucuk kalmış oluyor.
Genel olarak algoritmanın nasıl çalıştığı hakkında belli bir bilgi sahibi olduğumuza göre son olarak gelin biraz yapısını inceleyelim. İlk olarak ağın yapısına bakalım:

Dediğimiz gibi, anchor box’ların gelmesiyle YOLOv1’deki birbirine bağlı katmanlar kaldırıldı. Ayrıca CNN’ler yapısı gereği girdi resmini küçülterek ilerliyor ve buda küçük nesnelerin tanınmasını zorlaştırıyor. Buna çözüm olarak örneğin SSD(Single Shot MultiBox Detector) algoritması farklı katmanlardaki feature map’lerden küçük nesneleri belirliyor. YOLO ise farklı bir yöntem kullanmış. Örneğin boyutu 28x28x512 olan bir katmanı 14x14x2048 boyutuna getirip bunu 14x14x1024’lük çıktı katmanının arkasına ekliyor.
En son YOLOv3’te geliştirilmiş olan Darknet-53’ ün yapısı ise şu şekilde (https://pjreddie.com/darknet/) :


YOLO’da hata fonksiyonlarını üç temel ana başlıkta inceleyebiliriz:
1-) Sınıflandırma kaybı: Tahmin edilen nesnenin ne kadar yanlış olduğu.
2-) Konum kaybı: Tahmin edilen kutunun ne kadar yanlış olduğu.
3-) Güven kaybı: Izgaranın içinde nesne olup olmadığının ne kadar yanlış olduğu.
Bunların hepsi genel kaybımızı etkileyen faktörler. Gelin üçünü kısaca inceleyelim.
Sınıflandırma Kaybı
Eğer geçerli ızgarada nesne varsa, her sınıf için:

Konum Kaybı
Eğer geçerli ızgarada nesne varsa:

Güven Kaybı
Eğer nesne varsa:

Eğer nesne yoksa:

Resmin ızgaralarında gezerken çoğu ızgara hiçbir nesne içermeyecektir. Yani arka plan olarak tespit ettiğimiz sınıflar çok fazla olacaktır. Bu durum sınıflarımız arasında bir dengesizliğe yol açıyor. Bunu azaltmak içinse eğer ızgarada nesne yoksa, yukarıdaki formülde de gördüğünüz gibi bu kaybı belirli bir sabitle (noobj ağırlığı) çarpıyoruz. (Genelde 0.5 olarak tanımlanır)
Bu üç hata fonksiyonun toplamı ise genel hata fonksiyonumuzu oluşturuyor:

Kaynaklar ve resimler:
https://pjreddie.com/media/files/papers/yolo_1.pdf
https://arxiv.org/pdf/1612.08242.pdf
https://pjreddie.com/media/files/papers/YOLOv3.pdf
(1): https://pjreddie.com/darknet/yolo/
(2): https://www.researchgate.net/profile/Giang_Son_Tran/publication/324549019
(3): https://cdn-images-1.medium.com/max/1600/1*lNZL03057Q4QH-zhzBD6tQ.png

{kind=link}