A Technical Overview of the Internet Computer 日本語訳
Medium の DFINITY 公式の記事 A Technical Overview of the Internet Computer(2020/9/18) の日本語訳です。
ブロックチェーンネットワークのインフラについての説明と、キャニスターのスマートコントラクトがどのようにしてウェブサービスを無制限にスケールすることを可能にしているのかを説明します。

世界初のウェブスピードであり、インターネットスケールのパブリックブロックチェーンである Internet Computer の本格始動に向けた最後のマイルストーンが間近に迫っています。DFINITY Foundation は、9月30日に開催される Sodium のリリースのバーチャルイベントで(訳注: 既に終わった2020年のイベントです)、Internet Computer を制御するオープンアルゴリズムのガバナンスシステムである Network Nervous System を公開します。また、このイベントでは、高度な暗号技術、コンセンサスプロトコル、トークンエコノミクスに関する詳細な技術資料を公開します。
この記念すべき日に先立ち、ネットワークの仕組みを非常に高いレベルの概要を一般の方々に提供したいと思います。
Network Nervous System
Internet Computer は、Internet Computer Protocol(ICP) と呼ばれるブロックチェーンコンピュータプロトコルに基づいています。ネットワーク自体は、組み立てたブロックの階層により構成されています。一番下には、専用のハードウェアノードをホストする独立したデータセンターがあります。これらのノードマシンを組み合わせてサブネットを作ります。サブネットは、キャニスタースマートコントラクトをホストします。キャニスタースマートコントラクトとは、ユーザーがアップロードした相互運用可能な演算ユニットで、コードとステートの両方を含みます。

ICPをユニークにしている要素の一つは、ネットワークの制御、設定、管理を行うNNS(Network Nervous System)です。
データセンターは NNS へ申請することでネットワークに参加し、NNSはデータセンターを導入する責務があります。NNS自体はオープンなガバナンスシステムを持つ一方で、ネットワークへの参加許可を統括しています。いわば、インターネットにおける ICANN のような役割を担っており、特にBGPルーターを走らせるための自律システム番号の付与などを行っています。NNSは、ノードマシンを監視して Internet Computer 上の統計的なばらつきを調べることで、パフォーマンスの低下や不具合を示す可能性があることを確認するなど、幅広いネットワーク管理の役割を果たします。
NNS は、ネットワークのトークンエコノミクスにおいても重要な役割を果たします。NNS は、データセンターで稼働しているノード と NNS 内で投票しているニューロンへ報酬を与えるために、新たにICPトークン(旧称:DFNトークン)を生成します。NNS 内での投票は、提出されたプロポーザルを決定するためのものです。NNS がデータセンターとニューロンに報酬を与えるために新たに ICPトークンを作ると、インフレになります。

(上図 VOTING REWARDS の文)NNS は、参加の割合に応じてニューロンへ投票の報酬を支払います。
(上図 NODE REWARDS の文)データセンターで稼働している標準から逸脱していないノードマシンに対して、NNS はそのリージョンに割り当てられた標準的な月額報酬を支払います。
最終的には、データセンターのオーナーとニューロンのオーナーは、そのトークンを受け取り、キャニスターのオーナー及びマネージャーと交換することができます。キャニスターのオーナーとマネージャーは、このトークンを受け取り、サイクルへ変換し、そのサイクルを使ってキャニスターをチャージします。そのキャニスターが計算を行う または メモリを保存すると、例えば、サイクルは焼却(burn)され、最終的に継続して稼働するにはさらにサイクルをチャージしなければなりません。これはデフレです。
サブネット
Internet Computer を理解するには、ネットワーク全体の基本構成要素であるサブネットの概念を理解する必要があります。サブネットは、Internet Computer ネットワークによりホストされているソフトウェアキャニスターの異なるサブセットをホストする役割を担っています。サブネットは、NNS による制御により、異なるデータセンターから集められたノードマシンをまとめることで作成されたものです。これらのノードマシンは、それらがホストするソフトウェアキャニスターに関連するデータと計算を対称的に複製する(原文: replicate)ために、ICP を介して協働します。

(上図の文)サブネットは、データセンターから集められたレプリカノードで構成され、ホストされたキャニスターに関わるデータと計算を共同で複製します。
NNS は、サブネットを構築する際に、独立したデータセンターのノードを組み合わせます。これにより、ICPプロトコル演算は、DFINITY が開発したビザンチンフォールトトレラント技術と暗号技術を用いて、サブネットの改ざん防止と不停止が可能になります。サブネットは、Internet Computer ネットワーク全体の基本的な構成要素ですが、ユーザーやソフトウエアにとって透明性のあるものです。ユーザーとキャニスターソフトウェアは、キャニスターの ID を知るだけで、キャニスターが提供している関数を呼び出すことができます。
この透明性は、インターネットの基本的な設計原理の延長線上にあるものです。インターネットでは、ユーザーがあるソフトウェアに接続したい場合、そのソフトウェアを実行しているマシンのIPアドレスと、そのソフトウェアがリッスンしているTCPポートを知るだけでよいのです。Internet Computer 上で、ユーザーがある関数を呼び出したい場合、キャニスターのID と関数のシグネチャを知るだけでよいのです。インターネットがシームレスな接続性を作り出すのと同じように、DFINITY はソフトウェアのためのシームレスな領域を作り出しました。権限を与えられたあらゆるソフトウェアは、ネットワーク下層の仕組みについて何も知らなくても、あらゆる他のソフトウェアを直接呼び出すことができるのです。
Internet Computer は、他の方法においてもサブネットの透明性を確保しています。NNS は、例えばネットワーク全体の負荷のバランスをとるために、例えば、サブネットを分割・統合することができます。これも、ホストされたキャニスターに対して透過的です。
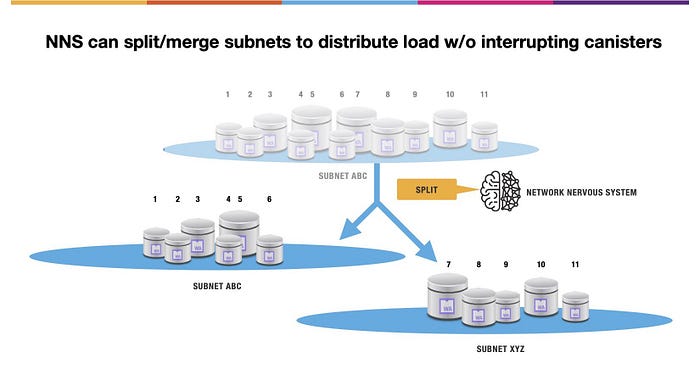
この例では、11個のキャニスターをホストする ABC という架空のサブネットがあるとします。NNS はこれを分割するように指示します。サブネットABC ではキャニスター 1–6 を持続し、そして新しいサブネット XYZ を生成し、サブネット XYZ ではキャニスター7–11を持続します。関係するどのキャニスターもサービスが中断されることはありません。
Internet Computer へキャニスターをアップロードする場合、特定のサブネットタイプを指定する必要があります。実は NNS をホストする特別なサブネットがあるのですが、あなたはそこにキャニスターをアップロードすることはできないのです。代わりに ”data”、”system”、”fiduciary “ のようなサブネットタイプを指定しなければなりません。
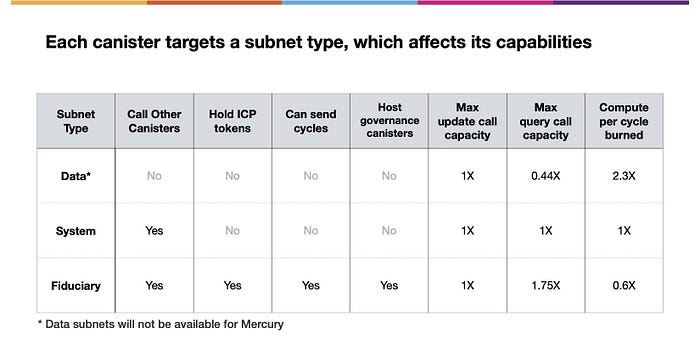
各サブネットタイプによって、キャニスターへ特定のプロパティと機能が与えられます。たとえば、キャニスタが Dataサブネット でホストされている場合、呼び出しを処理することはできますが、他のキャニスタに呼び出しを行うことはできません。そのためには、Systemサブネット が必要です。キャニスターに ICPトークンの残高を保持させたり、他のキャニスターへサイクルを送信させたい場合は、Fiduciary サブネット が必要です。このような理由から、ガバナンスキャニスターは Fiduciaryサブネット でのみホストすることができます。
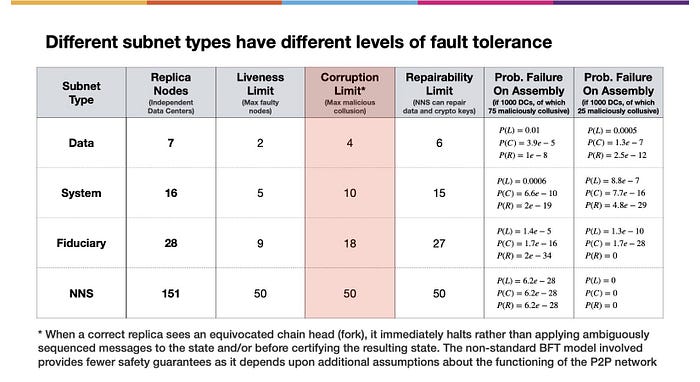
(上図の文)正しいレプリカが曖昧なチェーンヘッド(フォーク)を発見した場合 または その結果得られたステートを認定する前に、曖昧な順序のメッセージをステートに適用するのではなく、直ちに停止させます。非標準の BFT モデルは、P2P ネットワークの機能に関する追加的な仮定に依存するため、安全性の保証はあまりありません。
サブネットの性能は、基礎的なフォールトトレランスによるところがあります。NNS が壊れたサブネットを修復するための新しい暗号技術を含み、基礎科学は実にエキサイティングな領域であり、近いうちに一般公開したいと考えています。
キャニスター
サブネットの目的は、キャニスターをホストすることです。キャニスターは専用のハイパーバイザー内で実行され、公開された特定のAPIを介して互いに作用します。キャニスターの内部には、WebAssembly の仮想マシンとその中で動作するメモリのページで実行できる WebAssembly バイトコードがあります。通常、WebAssembly バイトコードは、Rust または Motoko のようなプログラミング言語をコンパイルすることで作成されます。そのバイトコードには、開発者が API と簡単にやりとりできるランタイムが組み込まれています。

(上図 ALLOWED CALL TYPESの文)キャニスターソフトウェアは、共有関数がアップデートコールまたはクエリーコールのどちらで呼び出されるかを明記する必要があります。アップデートコールによってメモリに加えられた変更は、(処理されない例外がスローされない限りは) 永続化されます。クエリ呼び出しによってメモリに加えられた変更は、すべて破棄されます。
Internet Computer では、キャニスターが提供する関数を2通りの方法のどちらかで呼び出す必要があります。アップデートコール または クエリコールのいずれかで呼び出すことができます。本質的な違いは、関数をアップデートコールで呼び出した場合、その関数がキャニスターのメモリ内のデータに加えた変更はすべて永続化されるのに対し、関数をクエリーコールで呼び出した場合は、メモリに加えた変更は実行後破棄されることです。
アップデートコールは変更を永続化し、ICPブロックチェーンのコンピュータプロトコルがサブネット内のすべてのノードで実行されるため、改ざんも防止されます。ご想像の通り、呼び出しは一貫したグローバルな順序で実行され、完全に決定論的な実行環境での同時実行を可能にするメカニズムが使用されています。アップデートコールはわずか2秒で完了します。
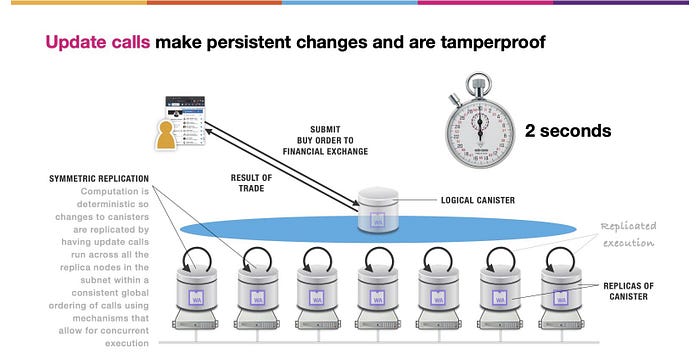
(上図 SYMMETRIC REPLICATIONの文)計算が決定論的であるため、キャニスターの変更は、同時実行を可能にするメカニズムを使用して、呼び出しの一貫したグローバルな順序で、サブネット内のすべてのレプリカノードをまたがってアップデートコールを実行させることで、複製されます。
この例では、ユーザーがキャニスター内でホストされている金融取引所に買い注文を出すとします。
一方、クエリーコールは、変更を永続化しません。メモリに加えたあらゆる変更は、実行後にすべて破棄されます。クエリーコールは非常に高性能かつ安価で、わずか数ミリ秒で完了します。これは、サブネット内のすべてのノードで実行されないためですが、セキュリティレベルが低いことも意味しています。

(上図 QUERY HANDLERの文)クエリコールは通常1つのレプリカで処理され、呼び出し側はその正しさを知ることができます。クエリーコールのセキュリティを高めるための別の手段を適用することはできますが、それはこのドキュメントの範囲外です。
この例では、ユーザーがカスタムのニュースフィードを要求しており、ほとんど生成されたばかりのコンテンツが即座に返されます。
直行永続性
Internet Computer の最も興味深い点は、開発者がデータを永続化する方法にあります。開発者は永続化について考える必要はありません。 — コードを書くだけで、自動的に永続化されます。直交永続性と呼ばれるものです。Internet Computer は、コードが実行されるメモリページを永続化するからです。
どのような仕組みなのか気になりますよね。メモリページを変更できるアップデートコールに関して、キャニスターはソフトウェアアクターです。つまり、キャニスターの内部では、常に1つのスレッドしか実行できません。
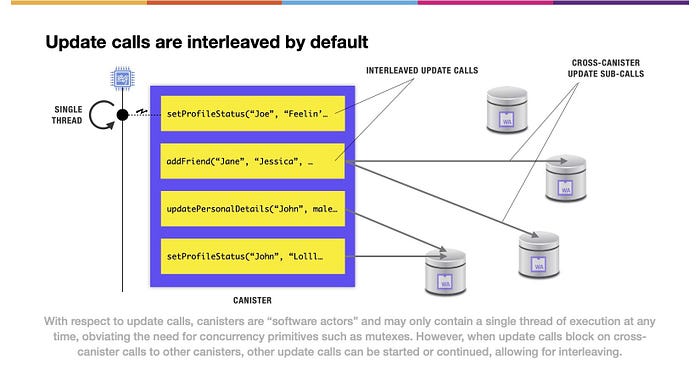
(上図の文)アップデートコールに関して、キャニスターは ”ソフトウェアアクター” であり、常に1つのスレッドしか実行できないため、ミューテックスのような並行処理プリミティブは必要ありません。しかし、アップデートコールが他のキャニスターへのクロスキャニスターでブロックされると、他のアップデートコールを開始または継続することができ、インターリーブを行うことができるようになります。
キャニスターの内部では実行スレッドは1つだけですが、デフォルトではキャニスター間のアップデートコールはインターリーブできます。これは、アップデートコールがキャニスタをまたがるアップデートコールを行い、それがブロックされると、実行のスレッドが新しいアップデートコールへ移動できるようになる場合に発生します。
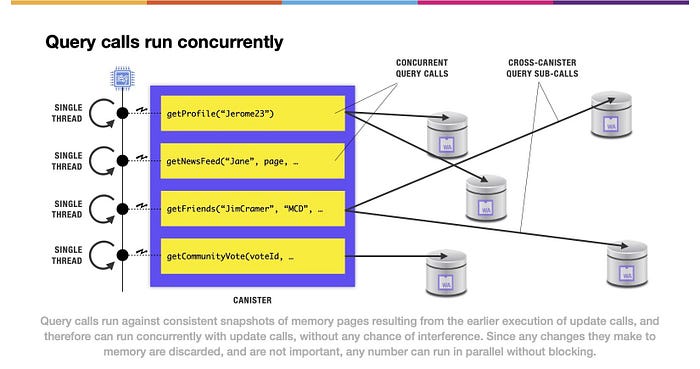
(上図の文)クエリーコールは、アップデートコールを先に実行した結果、メモリページの一貫したスナップショットに対して実行されるため、干渉の可能性はなく、アップデートコールと同時に実行できます。メモリに加えた変更はすべて破棄され、重要ではないので、ブロックすることなくいくつでも並行して実行できます。
これに対し、クエリーコールでは、メモリへの変更を永続化することはありません。このため、キャニスター内部でクエリーコールを処理するスレッドを、任意の数だけ同時に存在させることができます。これらのクエリーコールは、最後にファイナライズされたステートルートに記録されたメモリのスナップショットに対して実行されます。
最後に、キャニスターは新しいキャニスターを作成することができ、キャニスターは自分自身をフォークすることができることを述べなければ、キャニスターの議論は完全ではありません。新しいキャニスターはWebAssembly バイトコードを指定するだけで作成でき、メモリページは空で始まります。キャニスターが自分自身をフォークすると、新しく生成されたコピーが作成され、内部のメモリページまで全く同じになります。スケーラブルなインターネットサービスを作成する際には、フォークが非常に有効であることがわかります。
スケーラビリティ
さて、ここからはスケールアウトするインターネットサービスについて、ハイレベルな解説をします。キャニスターには、さまざまな種類の容量に上限があります。例えば、WebAssembly実装の制限により、キャニスターは4GBのメモリページしか保存できません。このため、数十億のユーザーにスケールアウトするインターネットサービスを作りたい場合、マルチキャニスターアーキテクチャを使わなければなりません。
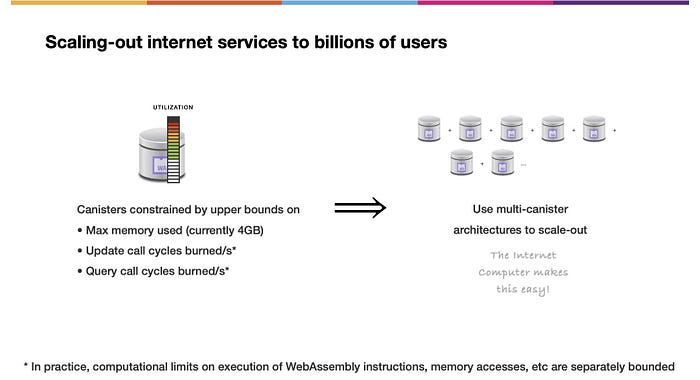
(上図の文)実際には、WebAssemblyの命令やメモリアクセスなどの実行に関する計算上の制限は別途定められています。
何か特別なキャニスターを作り、そのコピーをたくさん作り、ユーザーコンテンツを異なるキャニスターにシャーディングして、スケールアウトできるインターネットサービスを作れば十分と思うかもしれません。残念ながら、このアーキテクチャは多くの理由から単純すぎるのです。
キャニスターを追加するごとに、全体のメモリ容量が増えるのは事実です。また、キャニスターを追加するごとに、アップデートコールとクエリコールのスループットが全体的に向上することも事実です。しかし、特定のユーザーのコンテンツに対するクエリコールリクエストを増やすことはできません。また、キャニスターシャードを追加してシステムの容量を増やすたびに、ユーザーコンテンツのバランスを再調整する必要があり、エッジアーキテクチャとしてはあまり優れているとは言えません。また、エンドユーザーに近いレプリカからクエリコールを提供する方法も、明らかではありません。フロントエンドのキャニスターとバックエンドのキャニスターの両方が必要になるでしょう。
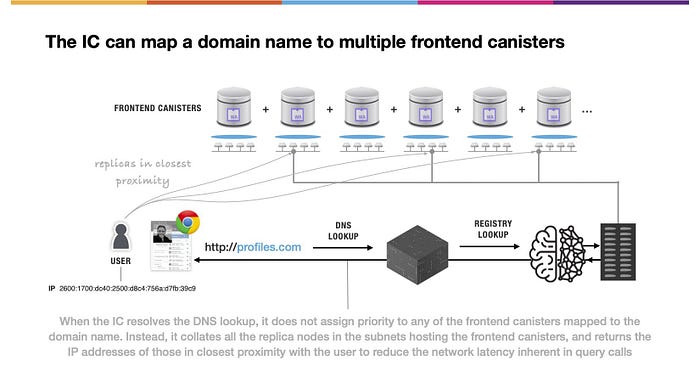
(上図の文)ICはDNSルックアップを解決する際、ドメイン名にマッピングされたフロントエンドキャニスターのいずれにも優先順位を割り当てません。その代わりに、フロントエンドキャニスターをホストするサブネット内のすべてのレプリカノードを照合し、クエリーコールに固有のネットワークレイテンシーを低減するためにユーザーに最も近いレプリカノードのIPアドレスを返します。
Internet Computer は、エンドユーザーとフロントエンドキャニスターを接続するために、いくつかの興味深い機能を提供しています。その1つは、NNSを介してドメイン名を複数のフロントエンドキャニスターへマッピングできることです。エンドユーザーがそのようなドメイン名を解決したい場合、Internet Computer は、フロントエンドキャニスターをホストするすべてのサブネットのレプリカノード全体を調べ、最も近くにあるレプリカノードのIPアドレスを返します。この結果、エンドユーザーは近くのレプリカでクエリコールを実行し、内在するネットワーク遅延を低減して、ユーザ体験を向上させ、コンテンツ配信ネットワークを介さないエッジコンピューティングの利点を提供します。

(上図の文)ブラウザは、クエリコールによって動的または静的なコンテンツを取得することを望みます。ICは、ドメイン名にマッピングされたフロントエンドキャニスターをルックアップします。キャニスターをホストするサブネットの全レプリカから、最も近いレプリカへDNSルックアップを解決します。これにより、どのフロントエンドキャニスターがその呼び出しを処理するかが決定します。
この機能を最大限に活用するためには、フロントエンドのキャニスターとバックエンドのデータバケットキャニスターを含む古典的なアーキテクチャが必要です。この例では、ウェブブラウザがプロフィール画像をロードしようとしています。
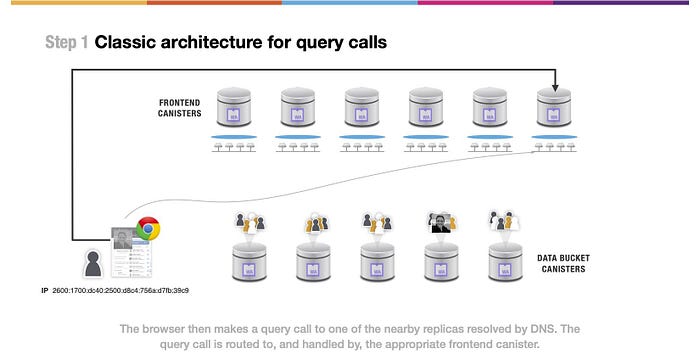
(上図の文)その後、ブラウザはDNSによって解決された近くのレプリカの1つに対してクエリーコールを呼び出します。クエリコールは適切なフロントエンドキャニスタにルーティングされ、処理されます。
まず、Webブラウザは、サブネットワーク上で動作している近くのノードのフロントエンドキャニスターにマッピングされます。そして、ウェブブラウザは、写真を取得するためのクエリコールリクエストをその近くのノードへ送信します。
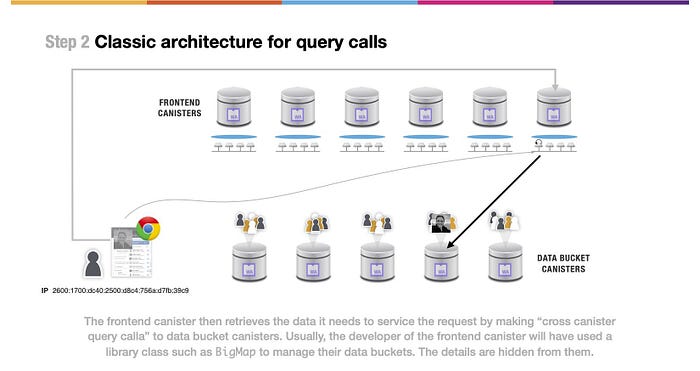
(上図の文)そして、フロントエンドキャニスターは、データバケットキャニスターに対して ”クロスキャニスタークエリーコール” を行うことで、リクエストに対応するために必要なデータを取得します。通常、フロントエンドキャニスターの開発者は、データバケットを管理するために、BigMapのようなライブラリクラスを使っているでしょう。その詳細は、彼らには隠蔽されています。
そして、フロントエンドキャニスターは、写真を保持するデータバケットキャニスターに対して、クロスキャニスタークエリーコールリクエストを行います。
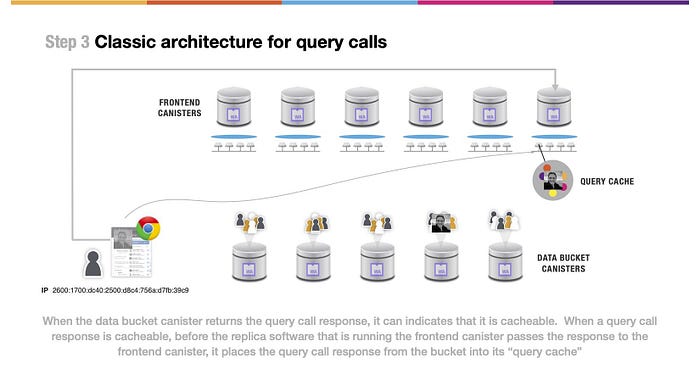
(上図の文)データバケットキャニスターは、クエリコールレスポンスを返すときに、それがキャッシュ可能であることを示すことができます。クエリーコールレスポンスがキャッシュ可能な場合、フロントエンドキャニスターを実行しているレプリカソフトウェアは、フロントエンドキャニスターにレスポンスを渡す前に、バケットからのクエリーコールレスポンスをその”クエリーキャッシュ”に入れます。
データバケットキャニスターが返すクエリーコールレスポンスが、写真のような静的コンテンツを含む場合、そのデータをキャッシュに格納することができます。そのような場合、フロントエンドキャニスターのクエリーコールを実行しているレプリカノードは、クエリーコールレスポンスをそのクエリーキャッシュへ入力できます。
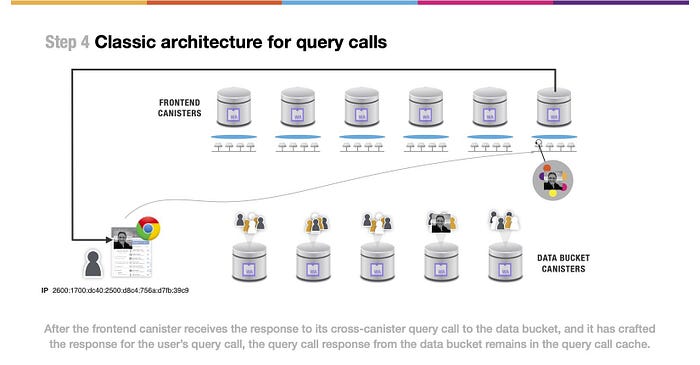
(上図の文)フロントエンドキャニスターがデータバケットへのクロスキャニスタークエリーコールに対するレスポンスを受け取り、ユーザーのクエリーコールに対するレスポンスを作成した後、データバケットからのクエリーコールレスポンスはクエリーコールキャッシュに残ります。
もちろん、クエリコールキャッシングのメカニズムは、フロントエンドキャニスターのコードに対して完全に透過的です。ユーザが呼び出したフロントエンドキャニスタが必要な情報をすべて集めたら、クエリコールレスポンスまたはHTTPエンドポイントを通じて、コンテンツを返すことができます。
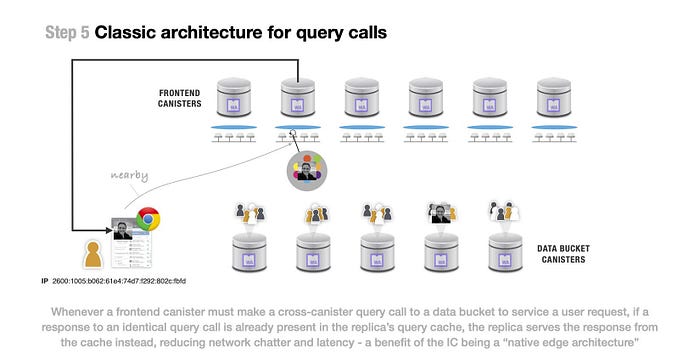
(上図の文)フロントエンドキャニスターがユーザーのリクエストを処理するために、データバケットに対してクロスキャニスタークエリーを呼び出す必要がある場合、同一のクエリーコールに対するレスポンスがすでにレプリカのクエリーキャッシュに存在すれば、レプリカは代わりにキャッシュからレスポンスを提供し、ネットワークチャッターとレイテンシーを削減します。 — ICの利点は「ネイティブエッジアーキテクチャー」であることです。
時間の経過とともに、ノードのクエリキャッシュは静的コンテンツを蓄積し、近くのユーザーが興味を持つようなデータを生成し、より速く、より良いユーザ体験を提供します。このようにして、Internet Computer のネイティブエッジアーキテクチャは、コンテンツ配信ネットワークの利点を提供しますが、開発者が特別なことをする必要はなく、別のプロプライエタリサービスの助けを得る必要もありません。
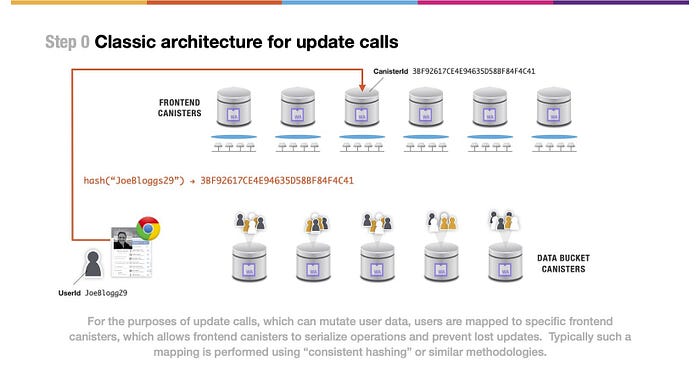
(上図の文)ユーザーデータを変更する可能性のあるアップデートコールのために、ユーザーは特定のフロントエンドキャニスターにマッピングされ、これによりフロントエンドキャニスターは操作を直列化し、更新の損失を防ぐことができます。通常、このようなマッピングは、”一貫したハッシュ” または同様の方法論を使用して実行されます。
アップデートコールについては、古典的なアーキテクチャは異なるアプローチを取ります。更新が失われるような問題を防ぐために、ユーザーのコンテンツやデータの更新をシリアライズする必要があります。一般的に、これはユーザーを特定のフロントエンドキャニスターへマッピングすることで、例えばユーザー名をハッシュ化することで実現されます。
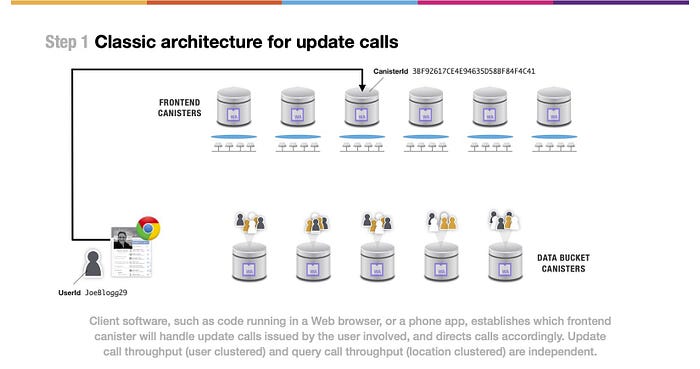
(上図の文)Webブラウザまたはスマホアプリで実行されるコードなどのクライアントソフトウェアは、関係するユーザーが発行したアップデートコールを処理するフロントエンドキャニスターを確定し、それに応じて呼び出しを指示します。アップデートコールのスループット(ユーザークラスタ)とクエリコールのスループット(ロケーションクラスタ)は独立しています。
Webブラウザ または スマートフォン で動作するUX/UIは、コンテンツまたはデータの変更を調整するフロントエンドキャニスターを決定すると、その標準インターフェースへアップデートコールを送信して、コンテンツまたはデータを変更することができます。
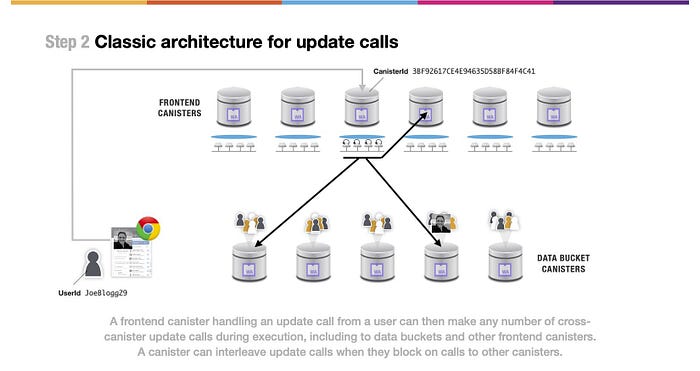
(上図の文)ユーザからのアップデートコールを処理するフロントエンドキャニスターは、データバケットと他のフロントエンドキャニスターを含め、実行中に任意の数のクロスキャニスターアップデートコールを行うことができます。キャニスターは、他のキャニスタへの呼び出しがブロックされたときに、アップデートコールをインターリーブすることができます。
そして、このフロントエンドキャニスターは、通常、必要な変更を行うために、さらにクロスキャニスターアップデートコールを呼び出します。
オープンインターネットサービス
最後に、フロントエンドキャニスターとバックエンドデータバケットキャニスターの2レベルアーキテクチャを用いた、オープンインターネットサービスの設計について説明します。まず、フロントエンドキャニスターのコードを書くときは、BigMapという既存のライブラリクラスを使って簡単に書くことができます。
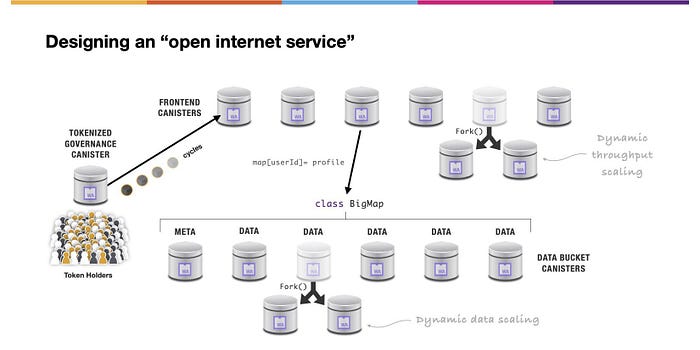
BigMapはエクサバイトのデータを保存することができ、たった1行のコードでオブジェクトを書き込むことができます。このアーキテクチャは、フロントエンドキャニスターとデータバケットキャニスターをフォークさせ、1つのキャニスターに割り当てられたオブジェクトの責務を2つのキャニスターに分割することで、透過的かつ動的にスケールアウトすることが可能です。
最後に、真なるオープンインターネットサービスを実現するために、すべてのキャニスターの責任をオープンでトークン化されたガバナンスキャニスターに割り当てることになるでしょう。あなたが起業家なら、初期にそのガバナンストークンの一部を販売することで、開発資金を調達するでしょう。そして、あなたはおそらく、あなたのインターネットサービスの初期参加者にガバナンストークンを与えることでインセンティブを与え、より良いネットワーク効果を得るためのスキームを設計するでしょう — そして、勝利を得るでしょう。
***
私たち DFINITY は、この新しいパブリックブロックチェーンが、インターネットを自由でオープンなルーツに戻しながら、ウェブの創造力を高めてくれることに、とてつもなく興奮しています。Sodiumのローンチイベントに参加して、Internet Computer を支える技術の詳細を学び、DFINITY Canister SDKをダウンロードしてコードを書き始めましょう。
_____
sdk.dfinity.orgでビルドを開始し、forum.dfinity.orgで開発者コミュニティに参加しましょう。

