Announcing Zafin Integrate & Orchestrate (IO) and Data Fabric
By Charbel Safadi, President, Adnan Haider, SVP Analytics and Shahir A. Daya, Chief Technology Officer
De-risking business transformation by accelerating integration
One of the biggest lessons we have learned over the years in implementing Zafin at some of the largest financial institutions is that integration and orchestration remain the single most challenging aspect of a core modernization journey. How you modernize a core while simultaneously transforming the business and continuously extracting business value along the way is critical to ensure a successful outcome. Supporting the coexistence of multiple cores is crucial.
We are a SaaS and offer standard and stable interfaces to integrate. We have a REST API for which we have published Open API specifications, we have a batch file interface for which we have a published file layout specification, and we have an event messaging interface for which we have published the Kafka Topics and corresponding AVRO schemas. The Zafin SaaS interfaces cannot accommodate the varying differences between the banks. It’s not possible to incorporate every unique requirement from each bank directly into the interfaces, that is where Zafin IO serves as a connecting bridge.
Our extensive experience with core modernization has led to the development of repeatable approaches and patterns, which in turn have transformed into reusable assets and accelerators. These innovations have now evolved into two products; Zafin Integrate & Orchestrate (IO) and Zafin Data Fabric.
What is Zafin IO
Zafin IO is a foundational technology platform that accelerates integration between a bank’s ecosystem and Zafin’s cloud-native SaaS. It provides accelerators that leverage well known design patterns and low-code approaches, to ease the development effort of bank-side data and application integration. This enables bank’s to rapidly simplify their core product systems and launch new personalized propositions at scale and at speed.
Our platform enables developers to build innovative integration solutions that enhance a bank’s business capabilities and drive time-to-value for their clients. With the support of our implementation team, Zafin IO will reduce risk in core modernization efforts while lowering implementation costs and time horizons, all while continuously delivering business value.
Zafin IO empowers the creation and delivery of cutting-edge solutions that accelerate and enhance a Bank’s core modernization journey.

Technology Stack
The following diagram illustrates the building block components that comprise Zafin IO.
- Redpanda, Apache Nifi, and Apache Flink will provide data movement and Streaming ETL capability. They are also used in our approach to delta detection and operational (i.e. are the fees posted to an account accurate) and data (i.e. did data successfully make it from source to sink) reconciliation.
- Temporal provides the ability to run highly durable workflows.
- Hasura provides a mechanism to expose GraphQL APIs.
- API Bridges will be developed as Java Spring Boot applications and deployed to the Application Node Pool in AKS.
- The Logging, Monitoring, & Observability Plane leverages the Azure Monitoring service to provide real-time metrics and logs for application and infrastructure components.
- Cosmos DB for PostgreSQL, Redis and Azure Blob Storage will be the data service used.
As our product roadmap evolves and progresses, additional components will be added.

Connectors and Accelerators
Zafin IO provides connectors to core banking platforms, collaboration tools, and business applications.
- Core banking — Zafin IO provides a portfolio of pre-built core banking connectors with end-to-end observability, scalability, and resiliency,
- Collaboration — Our collaboration connectors expose the business capabilities of the Zafin product suite through everyday communication tools that connect your entire business, like Microsoft Teams.
- Application — Our application connectors connect your customer support, sales, and other customer communications directly with Zafin, streamlining digital workflows for the enterprise.
Foundational Capabilities
With respect to integration, there are two key foundational capabilities that comprise Zafin IO. Zafin IO provides the capabilities to accelerate the data and application integration between the bank’s core systems and the Zafin SaaS.
Data Integration — When implementing the Zafin solution to externalize Product and Pricing from core systems, the bank must send reference data such as customers, accounts, customer to account relationships, and transactions to the Zafin SaaS for ingestion and use in its pricing engine.
Zafin IO can handle batch, change data capture (CDC), and streaming. We treat batch files as bounded streams. The following are some of the capabilities of the data integration component:
- Schema transformation — Basic schema transformation from the bank’s schema to the schema that Zafin SaaS expects.
- Filtering — It is often easier for the bank to send us batch files they already produce and let Zafin IO handle filtering data we do not need. Our data integration component has that capability. It is also used for incremental roll out of products from core to Zafin by filtering out products that are not yet managed by Zafin.
- Delta detection — After the initial load of all the reference data, we expect the bank to send us only delta files daily for ingestion and processing. This can be difficult to do. The Zafin IO data integration component has the capability of producing delta files by comparing newly received files with what was successfully processed on the previous day, thus giving an accurate delta of what needs to be processed.
- Reconciliation — Both operational (for example, were the correct fees posted) and data (for example, did any records fail to reach their target destination) reconciliation capabilities provide additional trust in the Zafin IO platform.
- Auto data classification and sensitive data leakage — The ability to leverage AI to identify sensitive data and potential PII data spanning across multiple datasets based on schemas and metadata, triggers field level encryption of those data attributes. Ongoing sampling of data as it traverses the data pipelines alerts to any potential leakage in sensitive data.
- Parallel and Continuous Run Validation — Zafin IO provides the capability to compare the fees calculated by Zafin to those posted by the core banking platform during a parallel run period when the core continues to be the system of record for fee calculations. Once parity has been achieved, we cutover to Zafin becoming the system of record for fee calculation and switch to continuous run validation when we compare fees calculated to actual fees posted to identify any deviations.
API Bridging — With any core modernization, the impact on channel applications can be significant and must be considered early. When you externalize a product from your core and make Zafin the system of record for product, all API calls from channel applications for products, eligible products, product details, etc.,all must be redirected to go to Zafin’s REST APIs. To help minimize this effort for integrating channel applications, Zafin IO provides the patterns and frameworks to build bridging integration façade APIs that bridge from the existing specification to the Zafin specification.
Development Features
Local Development Environment and CLI — To enable the development of data integration pipelines and API Bridges, we have created a local development environment to lessen the burden on developers and achieve a level of consistency in the development lifecycle. It also ensures a level of environmental parity with our Zafin IO SaaS.
We leverage Kind (Kubernetes IN Docker), a tool for running local Kubernetes clusters using Docker containers. A Command Line Interface (CLI) built using the Cobra framework provides the mechanism to start, interact, and stop the local Zafin IO environment. We envision that the Zafin IO CLI will also provide the ability to interact with remote instances of Zafin IO.
The screenshot in the figure below shows the use of the CLI to start a local Zafin IO development environment.
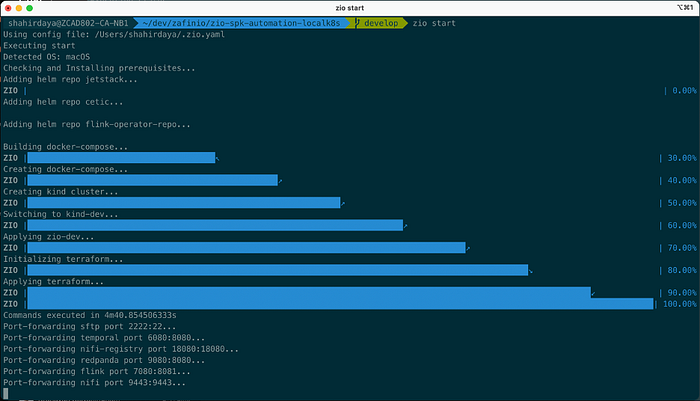
We will dedicate a blog to the Local Development Environment and the CLI in the coming months. There has been some significant engineering effort on those pieces, and we’d like to share the many lessons learned.
Connector Development Kit (CDK) — We are working on a connector development kit that will enable partners and clients to create their own connectors and leverage them within Zafin IO.
Low-Code Builder Platform — We envision a low-code builder platform that will provide an option to build commonly encountered scenarios rapidly. The following figure provides a designer’s rendition of the builder.
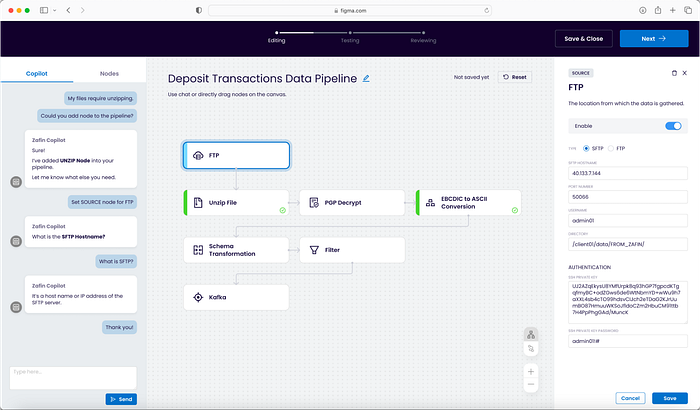
The builder platform will have Zafin Copilot as a first-class citizen. Zafin Copilot serves as a knowledge assistant as well as an agent of action enabling building through conversation. The following three builders are planned:
- Data Pipeline Builder — The Data Pipeline Builder will facilitate rapidly building your typical basic data pipelines to transform data to the Zafin format. The option to directly create Nifi flows, and Flink stream processing applications exists for more complex scenarios.
- API Bridge Builder — The concept behind the API Bridge Builder is to enable visually building anAPI Bridge façade from an existing API specification to the Zafin API specification. A hardened Microservices/API framework is available for creating these API bridges for complex scenarios with cross-cutting concerns including observability implemented to ensure that even the most stringent non-functional requirements can be met.
- Data Product Builder — Having all data flowing in and out of Zafin lO opens the possibility to easily create data products that solve business problems. Data of interest can be selected, joined with other data, enriched via many different means, and materialized into a view for API access or report creation.
Zafin IO feeds the Zafin Data Fabric, and the Data Product Builder can be used to build data products leveraging the data streaming through IO and in the Data Fabric. Now, let’s switch to the Zafin Data Fabric.
Why do we need the data fabric?
Until recently, Zafin’s flagship application, Relationship Pricing Engine (RPE) was the point of data ingestion. RPE ingested data based on the specified interface specification, validated the data — and then, we extracted and loaded the data for analytics.
This pattern works well when a single monolithic application does the processing of the business logic associated with pricing and billing, but as Zafin grew and built more applications, we started to run into issues.
There are three challenges in particular:
- Timeliness: When data comes in via the monolith, it is only available after it has gone through the validation. This introduces latency, especially if the pricing execution is using daily batches. Downstream applications would wait a day for the data to be ingested, validated and made available.
- Data volume: The execution of pricing and billing is computationally intensive, mission critical and the processing needs to be completed within tight SLA envelopes. For this reason, there is an inherent trade-off between ingesting higher data volumes to enable downstream analytical use-cases, which comes at the cost of more time and compute, and limiting the data to only what’s required, which comes at the cost of limiting downstream use-cases.
- DRY-ness: Pricing and billing is inherently about metrics, for example the number of international transfers performed, or minimum monthly balance. The logic for calculating these metrics was embedded within the core application. But as we expanded, we found that the same metric was in fact needed in different modules. The Offers & Rewards module may need aggregated transaction value for qualifying transactions to compute a reward, and the Martech stack would need the same metric to push personalized nudges.
While we were working through these interesting technical challenges, we found that our banking clients were having similar issues internally. In fact, their problems were magnified due to the scale of their operations. We work with the largest banks globally, and they operate in a multi-core environment. Each core has a different data model and taxonomy, making it difficult to stitch together a view across lines of business. We already help banks build multi-product propositions, but as we dug deeper, we found an important job-to-be-done: making their first party data actionable. What started out as an internal initiative transformed into a platform for internal teams as well as the bank’s engineers.
Enter the Zafin Data Fabric
Zafin Data Fabric is a centralized data store to simplify data transformation and distribution. Zafin IO sinks data into the raw zone of the Data Fabric. From there, the data is transformed into datasets; these datasets can be BIAN-aligned or use-case-aligned. The transformed datasets are modelled into metrics using the semantic layer. These metrics are exposed as aggregates via Data APIs. The datasets will also be exposed through a GraphQL engine to enable flexible and performant querying.
There are two data storages: The Analytical Data Store is for transformations and advanced analytics model development. The Operational Data Store is for Data APIs.
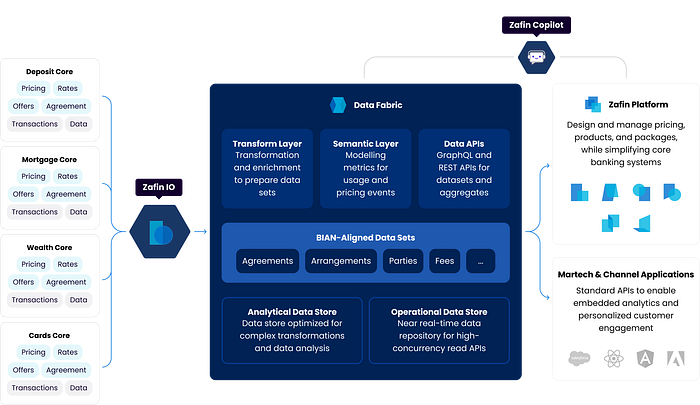
Transform Layer
The transform layer on the data fabric is for non-latency-sensitive transformations, as Zafin IO handles latency-sensitive transformations through streaming applications.
The transformation layer on the Data Fabric is Data Build Tool (dbt), a tool already in use at Zafin and widely adopted in the modern data stack. Dbt allows us to easily transform our datasets, and it provides a simple declarative mechanism to incorporate data quality tests into the pipeline, as well as lineage tracking. The analytics engineers on our team implement dbt models to transform raw reference and pricing execution data into curated data sets.
Semantic Layer
The semantic layer is used to model metrics. These metrics are aggregates on reference data or derived data. The user can create metrics at the customer or account level (and in the future, additional levels such as Groups and Pricing Arrangements). Metrics can be created for events relating to fees or usage. An example of a metric is: a transaction rule based on volume, value or a combination of the two (“number of transactions performed by customer, where the txn_value is greater than $20 and txn_code is ‘TC1’”).
Data APIs
Once created, metrics can be queried using a standard API. The API publishes the computed metric for the requested time period (e.g., 1/Jan/2022–1/Aug/2022) and window (e.g., per day, month, total). The API-based approach enables the distribution of revenue and usage data to the channels, as well as personalized messages by downstream systems. The data can also be displayed in relationship manager dashboards so that they can monitor the metrics of interest. In addition to metrics, the data fabric exposes curated BIAN-aligned and use-case specified data sets such as:
BIAN-aligned curated datasets for:
- Agreements
- Arrangements
- Fees
- Party-account relationships
- Offer fulfillments
These datasets are available through a performant GraphQL endpoint that supports high-concurrency reads to embed these insights into channel applications, for bankers and end-customers.
Conclusion
Zafin IO and Zafin Data Fabric provide speed and value while de-risking a core modernization journey by accelerating integration efforts and providing the capability to orchestrate across multiple core systems.
Over the coming months, we plan to delve further into the technology underlying the Zafin IO and Data Fabric components.
We are always learning and appreciate any comments or suggestions.
References
- Zafin IO webpage: Zafin. (2023). Zafin IO. Available at: https://zafin.com/zafin-io/ (Accessed: 23 October 2023).
- Zafin Data Fabric webpage: Zafin. (2023). Zafin Data Fabric. Available at: https://zafin.com/zafin-data-fabric/ (Accessed: 23 October 2023).
- Platform (2023) Zafin. Available at: https://zafin.com/platform/ (Accessed: 23 October 2023).
- The streaming data platform for developers, Redpanda. Available at: https://redpanda.com/ (Accessed: 23 October 2023).
- Apache NiFi. Available at: https://nifi.apache.org/ (Accessed: 23 October 2023).
- Apache Flink® — stateful computations over data streams (no date) Apache Flink. Available at: https://flink.apache.org/ (Accessed: 23 October 2023).
- Open source durable execution platform: Temporal technologies (no date) Open Source Durable Execution Platform | Temporal Technologies. Available at: https://temporal.io/ (Accessed: 23 October 2023).
- Instant graphql apis on your data: Built-in Authz & Caching (no date) Hasura. Available at: https://hasura.io/(Accessed: 23 October 2023).
- Kind. Available at: https://kind.sigs.k8s.io/ (Accessed: 23 October 2023).
- Cobra.Dev. Available at: https://cobra.dev/ (Accessed: 23 October 2023).
- BIAN. Available at: https://bian.org/ (Accessed: 23 October 2023).
- GraphQL (2023) Wikipedia. Available at: https://en.wikipedia.org/wiki/GraphQL (Accessed: 23 October 2023).
- Transform data in your Warehouse (no date) dbt Labs. Available at: https://www.getdbt.com/ (Accessed: 23 October 2023).
