Expedia Group Technology — Data
Enhancing Data Reliability With An SLO Platform
How we improved service performance and decision-making within Expedia Group
Introduction

In our fast-paced, data-driven world, having reliable and timely access to information is critical. Key to this are Service Level Objectives (SLOs), which form the backbone of informed decision-making in the reliability domain of many organizations. Service Level Objectives are central to maintaining the performance and availability of services, providing measurable goals that services strive to meet. However, a key challenge that organizations face is to ensure consistent and reliable access to such critical data. A data platform for telemetry data, particularly focusing on the ingestion of SLOs and making it widely accessible across the enterprise, could be the solution to this problem.
In this article, we present the creation and development of an SLO Platform at Expedia Group™. We will explore the architecture of this platform, detailing its integrations. Additionally, we’ll examine the operational aspects of the platform, giving insights into it’s functionality and the role it plays in enhancing service performance and decision-making within Expedia Group.
How it started
Expedia Group strives to offer reliable services to its customers. Central to this goal is the effective monitoring and management of service quality. We have been using DataDog, a well-known observability platform, which supports the monitoring of SLO data that sheds light on how well our services perform. However, we encountered a series of significant challenges with our approach.
- Multiple DataDog instances: The data was distributed across multiple DataDog instances, complicating the analysis.
- Dependency on DataDog: Heavy coupling on DataDog for critical data could limit flexibility needed in the future.
- Augmentation with internal metadata: The SLO data needed to be augmented with the internal application metadata for customized insights.
- Rate-limiting constraints: DataDog’s API rate limits restricted timely access to data, inhibiting the ability to respond rapidly to data queries.
- Data redundancy: Lack of backup capabilities, creating potential risk for data loss and prompt recovery.
This led us to a fundamental problem:
How can we ingest, store and augment SLO data from DataDog in a centralized way for diverse needs like reporting, machine learning, analytics and API access, while ensuring easy access across our organization?
10,000-foot overview
The primary aim was to ingest, transform, augment, and store data from multiple sources, while making it widely accessible internally. The design was targeted to be robust, ensuring reliability and efficiency, while its integration with internal systems would provide value to stakeholders.
The decision to utilize a streaming data architecture was driven by the need for near real-time data-processing capabilities. Despite adopting streaming terminology, our architecture primarily undertook batch processing, especially on the consumer side. This was due to the nature of the data provided by DataDog, which doesn’t offer a continuous stream of SLO data. We realized that real-time data wasn’t a strict requirement for us, so our system was designed to handle data with an acceptable delay, simulating near-real-time processing.
Integrating various technologies such as Kafka for event streaming, PostgreSQL for data storage, and APIs for data querying, the platform was well-equipped to meet the processing requirements. This setup ensured that data was not only timely accessible but also presented in an actionable and comprehensible manner.
Architecture
We were looking for a system to manage multiple data sources and offer data in its raw form as well as in a transformed state, complete with internal metadata. The need to access data near real-time required a streaming methodology. The below diagram illustrates how the different components — data ingestion, transformation, storage and presentation work together seamlessly to enable efficient processing of data.
Data ingestion
The data ingestion layer serves the purpose of consuming data from DataDog and pushing it into a Kafka topic in its raw form. Here, we’ve created a Spring Boot micro-service that runs periodically and consumes SLO data from different DataDog instances. This data is then published into the initial Kafka topic, enabling consumption of raw data.
Enrichment and transformation
The enrichment layer focuses on refining and enhancing the data. This raw data retrieved from the first Kafka topic is transformed by using a KStream application, responsible for transforming the raw data, enriching it with necessary application metadata, and ensuring compliance with both our internal schemas and standards. Once transformed and enriched, this data is then stored into our PostgreSQL database. The choice of PostgreSQL as our database solution was driven by its reliability, data integrity, efficient data access, and scalability. The four primary goals at this stage are to:
- Enrich the raw SLO data with the application metadata;
- Address any rate limiting concerns with DataDog APIs;
- Extend the data retention period from DataDog’s 90-day limit to a year in our systems; and
- Create an internal repository for backup, analytical and machine learning purposes.
Data presentation
At the presentation layer, the transformed SLO data is made readily accessible through an API. This layer functions as a user-friendly facade to the PostgreSQL database, streamlining the data access for the users. The enriched data is then utilized in various platforms, such as our developer portal and Business Intelligence tools. The design of this layer ensures ease of data retrieval and utilization, enabling users to effectively use the data for a wide range of visualization and analytical purposes.
Integrations
DataDog: proactive monitoring and real-time alerting
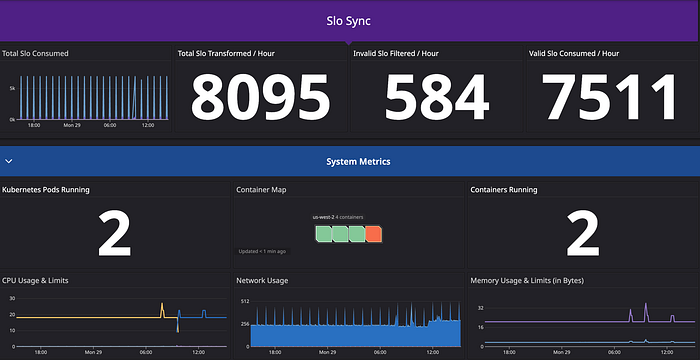
Our SLO platform extensively relies on DataDog for its critical observability functions. It currently processes ~10k records per sync, with a design to scale up to handling ~200k records. DataDog acts as our operational monitor, constantly monitoring for any deviations from our defined Service Level Objectives. It offers these features:
- Provide immediate alerts: Whenever our SLO metrics deviate from their expected thresholds, DataDog promptly alerts the application owners, allowing for swift issue identification and resolution.
- Facilitate near real-time monitoring: Its robust monitoring capabilities empower us to keep a close eye on our system’s health, ensuring we are continuously informed and well-prepared for immediate action.
Developer platform integration
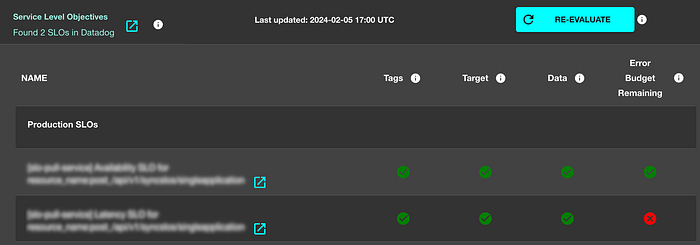
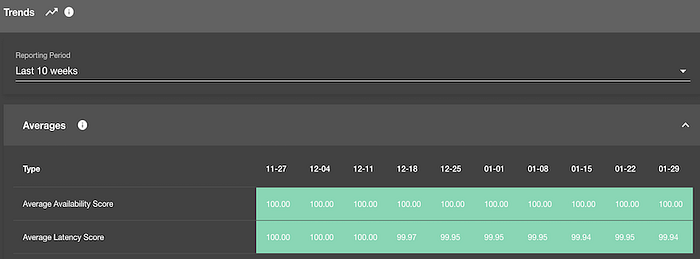
Our architecture seamlessly integrates with our developer platform to offer an in-depth, service-specific view for the thousands of services in our Service Catalog. This integration extends our capabilities in several key ways:
- Comprehensive SLO details: By integrating with the developer platform, we provide extensive details on SLOs, allowing application owners and developers to have visibility of their SLOs at one place.
- SLO trends: Our integration offers daily, weekly and monthly SLO trend analysis, empowering teams to track the historical performance of their SLOs and identify patterns and anomalies.
- Compliance and governance: The developer platform integration also includes compliance and governance checks for applications, ensuring that they adhere to defined standards and policies.
Next steps
Our primary focus remains on strengthening our technical capabilities. One of our key priorities is to further enhance the quality of our SLO data. By ensuring its accuracy and reliability, we aim to establish a solid foundation for making informed decisions.
SLO data quality
Our efforts to improve SLO data quality are focused on refining the accuracy of our SLO data. While the SLO Platform team has developed an interface for generating proposed SLOs for applications, it’s essential for them to undergo review by the respective application teams. This initiative aims to implement guardrail mechanisms, enabling the automatic identification of issues while proactively encouraging teams to refine their SLOs based on feedback.
Error budgets policy
Efficiently managing errors within Service Level Objectives is critical for maintaining system reliability and meeting stakeholder expectations. To address this, we are actively working on formalizing the Error Budgets Policy agreements. These agreements would outline the actions to take if error thresholds are breached across critical applications, ensuring a balanced approach between maintaining development velocity and addressing availability concerns. By establishing clear guidelines for managing errors within SLOs, we empower teams to proactively address issues and respond effectively to incidents.
Future innovations
We’re continually exploring ways to improve the performance and reliability of our services. As we plan for the future, we’re considering integrating our SLO Platform with additional tools to address ever-evolving challenges.
Integration with chaos engineering platform
To further enhance service reliability, we’re also planning to explore integrations with our Chaos Engineering platform. We anticipate this collaboration to validate system resilience, identify potential failure modes and strengthen our ability to handle unforeseen challenges. Additionally, it will provide valuable data for refining our strategies, ensuring proactive and well-informed decision-making, enabling us to anticipate and address potential issues swiftly.
Closing notes
At Expedia Group, our mission extends beyond technology development; we strive for excellence in service and reliability. We’re thrilled about the progress we’ve made, leveraging data as a powerful tool for decision-making and service optimization.
Building a platform capable of seamlessly handling data from multiple sources is a remarkable achievement, and it’s important to express our gratitude to the individuals who each played an important role in making this a reality. Special thanks to Rohit Kumar, Nikos Katirtzis, and the entire SLO Platform Team for their expertise and dedication in shaping the platform into what it is today.
Looking ahead, our focus extends beyond Service Level Objectives to include a wide range of operational data, from incident data to detailed service information. This expansion is part of our ongoing efforts to establish a more robust data-driven decision-making process.

