HTTP & the Request-Response Cycle
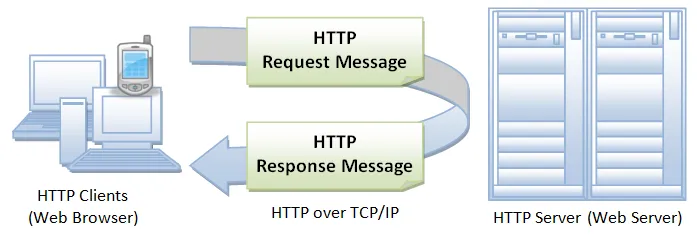
Hyper-text-transfer-protocol (HTTP) is a procedural system for fetching resources (for example, HTML documents) that was designed by Tim Berners Lee in 1989. It is a client-server protocol, meaning requests are made by the recipient (typically the browser). HTTP is the foundation for any data exchange made on the Web and is essentially the backbone of the internet. From all of the sub-documents fetched a complete document is reconstructed, including images, layout description, text, scripts, etc.
As a web developer, an important characteristic of HTTP to understand is that it is stateless. This means there is no link between two successive requests. If not addressed, this can pose issues when a user is coherently interacting with a web-page such as an e-commerce shopping basket or when logged-in to an account and navigating to different pages within that web-application. Without enabling HTTP cookies, the items that the user added to their cart would not be persisted and the logged-in user would be logged-out and lose authorization upon redirection to another web-page. HTTP cookies are added to the workflow using header extensibility, allowing for the use of stateful sessions. This means that each HTTP request is able to share the same context, or state- allowing for the persistence of user data.
Clients and servers communicate via individual messages, with clients making requests to the server and the server sending responses back. HTTP is highly extensible and because of this it is used not just in fetching hypertext documents, but also allows for actions such as the posting of content to servers and fetching of images or videos. HTTP is also used to fetch portions of documents to update individual parts of a Web page.
Components of the HTTP-based system include the user-agent (the client), the Web server, and Proxies.
User-Agent:
The user-agent is any mechanism that acts on behalf of the user — typically a web browser. In the dev world, the user-agent could also be a program used to debug an application. In order to display a Web page, the browser sends an initial request to the server to fetch the application’s HTML document. The browser then parses the file, in doing so making requests for scripts, CSS, and sub-resources contained within the HTML document. These resources are then mixed by the browser and are displayed to the user as a complete document.
The web-page that is rendered by the browser is a hypertext document, meaning that displayed text can take the form of a link able to be activated by a user (typically in the form a click) that triggers a request to the server. User’s are able to direct their user-agent to navigate through the web-application through these hypertext links. The browser sends HTTP requests associated with the link, interpreting the HTTP response sent back from the server to display the received information to the user.
Web Server:
On the other side from the user-agent is the server, which responds (or serves) to the requests of the user-agent with information. The server includes several parts that control how the user-agent accesses hosted files. The HTTP server is accessed through the domain name(s) it stores and the content of the hosted website(s) is delivered to the user-agent. The responses sent back to the user-agent always include a status code indicating whether the request was successful or unsuccessful and giving some information on why it may have succeeded or failed (I cover error codes in a previous post if interested).
Proxies:
A proxy is a server application that works as an intermediary for client resource requests to the servers that host those resources. In-between the user-agent (browser) and the server, a number of machines and computers relay HTTP messages. Proxies operate at the application layers and can be transparent or non-transparent. A transparent proxy forwards received requests without altering them, while a non-transparent proxy changes the request on its way to the server.
Functions performed by proxies can include caching (storing data so future requests for that data can be completed faster— can be public or private), filtering (such as parental controls or antivirus scans), load balancing (allowing multiple servers to serve different requests), authentication (control of access to different resources), and logging (storage of historical information).
HTTP flow is another important concept to grasp as a web developer. In order for a client to communicate with a server, several steps have to occur. The first of which being the opening of a TCP (Transmission Control Protocol)/IP connection. This connection is used to send a request (or requests) and receive a response. Clients may open a new connection, reuse an existing one, or open multiple connections to the servers. Next, an HTTP message/request needs to be sent. Then the response from the server needs to be read, which includes a status code and can include a number of different informational attributes. Lastly, the connection is either closed or kept open for future requests.

An HTTP request includes a method, path, version of HTTP protocol, optional headers, and optional body. The method is typically a verb such as GET (fetching a resource), POST (creating a resource), PUT (updating/replacing a resource), PATCH (partially updating a resource), or DELETE (deleting a resource), that defines what action the client is requesting to perform. The path of the request defines where the request should be directed to reach the desired resource. The version is simply the version of HTTP protocol being used. Headers provide optional additional information to the servers. The body is optional and is typically included with POST requests to include the client resource being sent to the server.

The HTTP response includes the version of HTTP protocol, a status code, a status message, HTTP headers, and an optional body. The status code indicates whether the request was successful or unsuccessful and why. The status message provides a short description of the status code. HTTP headers are similar to those in requests. If present, the body contains the fetched resource.
Now that we have some concepts and terminology of the HTTP request-response cycle defined, let’s go over what happens when you enter a URL into the browser. An HTTP request can be made either manually (by entering a URL into the address bar) or programmatically (by apps, websites (JavaScript), or other programs). The request is complete when a response from the server is received.
A good place to start in understanding the HTTP request cycle is to look at and break down a URL:
http://denalibalser.medium.com/hello
- http:// — this is the protocol used for communication between browser (aka user-agent) and server. It’s presence in the URL indicates that the client wants to connect to a web server that speaks HTTP.
- medium.com — this is the domain of the server that stores the resources for the web-application
- denalibalser — this is the subdomain of the server, or the part of the URL that comes before the main domain name and aids in logically dividing a website. In this example my name is the subdomain which indicates that this is my blog on the medium domain.
- /hello — the path, which refers to the exact location of the page, file, post or other asset. So in this example, hello could be the name of one of my posts.
This structuring is part of the HTTP universal rule-set that helps to retain consistency and maintain meaningful communication, similar to the rules of spoken language.
After this URL is input into the address bar and the user hits enter, the request is sent through the global network of cables that make up the internet. The routing involved in the process utilizes IP addresses, which are found with the help of the Domain Name System (DNS). The DNS is comparable to an address book for the Internet. The Internet has two principle namespaces, the domain name hierarchy and the IP address system — the DNS maintains the domain namespace and facilitates translation services between the two namespaces. Once connected to the DNS server, the IP address for denalibalser.medium.com is requested and returned. All web servers are identified by IP address and it is essential for a device to know the IP address of another in order to communicate.
Locating the IP Address
In order for a DNS server to resolve a domain to an IP address what first happens is the DNS Resolver (housed on your local device) searches through the browser’s cache. A cache is a block of memory used for temporary data storage that is likely to be used again. If the website was accessed recently by the device the IP address will have been cached — if this is the case the browser will immediately call the IP address to retrieve the web page.
If the IP address is not found in the local cache, the DNS Recursor (which is often the DNS Server of your Internet Service Provider) is accessed and queried. The DNS Recursor has a cache from websites that their clients have recently visited. If the IP address is still not located, the request will be passed to the Domain Server.
The Root Level Domain Server (RLDS) is the first level that requests go through, where they are read and directed towards the appropriate domain server. The Top Level Domain Server (TLDS) determines where the request should be directed to next based upon the domain suffix (.com, .org, etc). The next and final layer is the Second-Level Domain Server, where all of the information about the domain is stored and accessible. From here a request for the record of the domain is sent to the DNS Server and the IP address is returned. These layers are present as a ‘gatekeepers’ or a security measures to stop malicious attacks on the WWW. The returned IP address is then used to connect with the host server using the TCP/IP connection and retrieve the webpage via HTTP.
