STEP-BY-STEP GUIDE
NLP: Text Pre-processing and Feature Engineering. Python.
Pre-process text data, create new features (including target variable for binary classification) with Python: Numpy, Pandas, Regex, Spacy, and Tensorflow.

Intro.
Data pre-processing is a fundamental part of data scientist work. Apart from data collecting, it is one of the principal stages. On it depends our future model’s quality and accuracy. The better we clean/prepare the data:
- the less we need to tune the model on the next stage,
- the simpler model we can apply,
- the more insights/patterns we may see,
- the more accurate our model can be.
So what is pre-processing in our current case?
In simple words: it is the process of text transformations. You have to make text useful for the analysis and prediction of your business goal.
This article will cover (in code examples) several important text data processing methods. Also, you’ll see a data preparation for the binary classification task with feature engineering technic. The chapters will tell about:
- Data description, business goal exploration;
- Data manipulation (we will create a base data set from just scraped non-structured data);
- Feature engineering with NLP methods(basically on POS Tagging with Spacy library, on grammatical + semantical context, on data analysis/insight/intuition);
- “Text to sequence” transformation with Tensorflow — the last step before creating a predictive model.
Data Description.
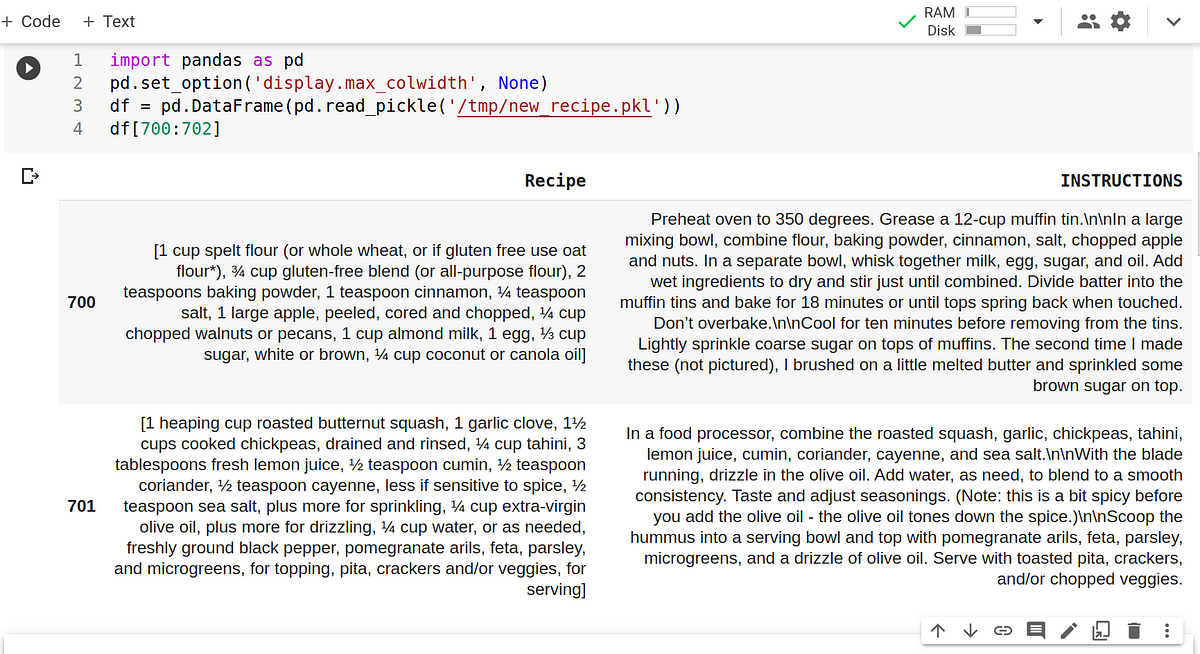
The data set for this tutorial is from my previous data scraping task: I collected it from a recipe website. The business goal is to determine for each paragraph its label is “ingredients” or “recipe”.
First, we should do — import the Pandas library and set display options to `max_colwithd` for better text readability:
import pandas as pd
pd.set_option('display.max_colwidth', None)When you open a file with not cleaned text data(using Pandas), you see a set with two columns: “Recipe” and “INSTRUCTIONS”. Each row from 1009 rows in DataFrame is data from 1009 unique pages with recipes. Each item in every cell is a list of paragraphs:

The “paragraph” in the Instructions column in each cell we define with “\n\n”. The “paragraph” in the Recipe column holds every cell itself.
Data manipulation. Create a base data set.
At first, it seems not much data. But let’s make a table with an actual paragraph in each cell. Lambda function and list comprehensions are suitable for the Recipe column transformation. For Instructions column will be enough embedded Series.str() function:
#ingredients
recipe_col = df["Recipe"].apply( \
lambda series: ' '.join([words for words in series])).to_numpy()#instructions
instr_col = df["INSTRUCTIONS"].str.split('\n\n').to_numpy()
In next step, we add a column with labels: 1 — ingredients, 0 — instructions. Take notice: in such a way, we create the target variable. We will use NumPy for data manipulation since now. Numpy has a significantly higher speed than pandas (as usual, it is more visible with large data sets):
import numpy as np#ingredients
recipe=recipe_col.reshape(-1, 1)
recipe=np.hstack((recipe, np.ones(len(recipe), int).reshape(-1, 1)))#instructions
instr=np.concatenate(instr_col).reshape(-1, 1)
instr=np.hstack((instr, np.zeros(len(instr), int).reshape(-1, 1)))
The next action is to concatenate these two ndArrays into one:
# forming a full data array with labels
data = np.concatenate((instr, recipe), axis=0)Insight from my own experience: sometimes, it is more convenient to label your data and feed it to a neural network instead of applying unsupervised techniques (Keras/Tensorflow).
After we created an attributive data set, we can reduce empty and duplicating rows. Then, again, come back to pandas DataFrame format for further feature engineering:
# remove duplicates
unique = np.unique(data.astype(str), axis=0)
# #remove empty string rows
unique=np.delete(unique.astype(str),np.where(unique == ''),axis=0)
data = pd.DataFrame(unique, columns=['paragraph', 'label'])As you can see in the picture below (Pic.2), the shape of a new set is 5144 rows now! As well, it has two columns: string “paragraph” and integer “label”. After removing duplicates and empty rows, the shape became less. Presently, we got 4871 rows for classification — more in four times than it was in the uploaded pickle file. Great — finally, we have data to work!

Every cell contains a string paragraph representation. Now we can eventually start the feature engineering part.
Feature engineering with NLP methods.
For the next text editions, we need to split the set on train and test ( to try prevent overfitting). In our case, we use a Sklearn library. After the split, all manipulations would be the same for train and test data.
If you check the proportion of labels, you see a disbalance: about 80% zeroes and 20% ones. The splitting fraction for the test set also takes 0.2 (we can’t take more because we have not much data).
#splin on train and test data sets
from sklearn.model_selection import train_test_splitX = data['paragraph'].copy()
y = data['label'].astype(int).copy()X_train, X_test, y_train, y_test = train_test_split(X,y,
stratify=y,
test_size=0.2,
random_state=42)
It is better to do a stratified split on the target variable.
Accounting for the small amount of data and imbalanced label,
we want to keep the distribution proportion in both sets the same. A simple check (see Pic.3) confers the split went well, as expected.

Let’s involve some linguistic insights and analysis of our data. When you look at Pic.1, you may notice:
- Paragraphs with “Ingredients” contain a lot of numbers;
- “Ingredients” may be absolutely free from verbs in opposite to “Instructions”;
- Commonly, “Ingredients” hold only numbers, nouns and adjectives.
- “Ingredients” paragraph is not full sentences (may not contain dots);
Thus, the first method we use here is POS Tagging. Inplace numbers, dots, and colons with specific tags. Change other punctuation for one space. For this purpose reasonable to use regex and lambda function. Before that, determine the set as pandas DataFrame for more convenient use:
import reDIGIT_RX = "($\d+([\.|,]\d+)?[\w]?[\s|-]){1,8}|[^A-Za-z\,()\.'\-:\!\? ]{1,8}"
SYMBOL_RX = "[/(/)\-/*/,\!\?]|[^ -~]"
DOT_RX = "\.{1,4}|\:"train = pd.DataFrame(X_train, columns=['paragraph'])train ['replaced_num']= train ['paragraph'].apply(lambda
series: re.sub(DIGIT_RX, " zNUM ", series))train ['replaced_symb'] = train ['replaced_num'].apply(lambda series: re.sub(SYMBOL_RX, " ", series))train ['replaced_dot'] = train ['replaced_symb'].apply(lambda series: re.sub(DOT_RX, " zDOT ", series))
The result is in the picture below (Pic.4). These four columns we need to track changes. You may leave only the “paragraph” as an original text, and “replaced_dot” (as we need it to apply next NLP method):

On Pic.4, several numbers are underlined with green color to show you what exactly we changed to tag zNUM. In red color — deleted additional punctuation. In blue color — tag zDOT instead of dots. It doesn’t matter if the capital or lower case tag is at the moment. Later on, all text will be lowercase. At this point, we only want to see what we have done and be sure the transformation went well. Finally, we can go to the lemmatization step.
Lemmatization, feature engineering and Stop Words removal with SpaCy. This brilliant library is useful for any NLP task . SpaCy Lemmatizer supports simple part-of-speech-sensitive suffix rules and lookup tables. In application to a string, it returns the available lemmas or string as it is.
Now look how this library works with our text: we want to count prons, verbs and remove stopwords. The first — install/import spacy, load English vocabulary and define a tokenaizer (we call it here “nlp”), prepare stop words set:
# !pip install spacy
# !python -m spacy download en_core_web_smimport spacy
nlp = spacy.load('en_core_web_sm')from spacy.lang.en.stop_words import STOP_WORDS
stop_words = set([w.lower() for w in list(STOP_WORDS)])
nlp.Defaults.stop_words |= {" f ", " s ", " etc"}
Now do the same as we done before in base set creation: pandas + lambda function, but this time apply a spacy lemmatization:
train['lemmatiz'] = train.replaced_dot.apply(lambda series: \ ' '.join([word.lemma_ for word in nlp(series)]))It will take some time to get the result. Lemmatization is not such a fast process. By the way, we get transformed words to their base form, as well we get another tag -PRON-. Instantly we begin new feature creation:
- use tag -PRON- for a binary column contains_pron (does the paragraph contain this tag: 1 — yes, 0 — no);
- verb_count for every paragraph.
train['contains_pron'] = train.lemmatiz.apply(lambda series: \
1 if series.__contains__('-PRON-') else 0 )train['verb_count'] = train.lemmatiz.apply(lambda series: \
len([token for token in nlp(series) if token.pos_ == 'VERB'])]))
Next step: remove extra spaces/punctuation that still might occur, and delete stop words:
#remove punctuation via String.tranlate(table)
def remove_punct(series):
table = str.maketrans('', '', string.punctuation)
tokens_punct = series.translate(table).lower()
tokens_spaces = ' '.join(
[token.strip() for token in tokens_punct.split() if token != ' ']
)
return tokens_spacestrain['tokens_punct'] = train.lemmatiz.apply(remove_punct)
#delete stopwords
train['remove_stop_words'] = train.tokens_punct.apply(lambda series: ' '.join([word for word in series.split()
if word not in stop_words]))
Basic linguistic statistics is also valuable for feature engineering on this set. We may create additional representative characteristics such as:
- count_sent (how many sentences in every cleaned paragraph);
- num_count (how many numbers occur in every cleaned paragraph);
- count_words (how many words contains every cleaned paragraph).
train['count_sent'] = train.remove_stop_words.apply(lambda series:
1 if series.count('zdot') == 0 else series.count('zdot'))train['num_count'] = train.remove_stop_words.apply(lambda series: series.count('znum'))train['count_words'] = train.remove_stop_words.apply(lambda series: len(nlp(series)))
For now, I think, we created enough extra features for the base model run. Look at the picture below(Pic.5). It shows five numerical columns (marked in the red square) and two columns with text:

The “paragraph” column we leave as a source text for a model explanation for the end of the entire research task (won’t be in this article). The numerical features we will leave aside for now as they are ready as model input. Right now, we will set a focus on the prepared text column.
“Text to sequence” transformation with Tensorflow.
The “remove_stop_words” we will transform with Tensorflow using Tokenizer and text_to_sequence method.
Tokenizer in Tensorflow allows vectorizing a text corpus, by turning each text into either a sequence of integers (each integer being the index of a token in a dictionary) or into a vector where the coefficient for each token could be binary, based on word count, based on tf-idf, etc. In our case, we apply the base of the TF-IDF coefficient (short for term frequency-inverse document frequency, is a numerical statistic that is intended to reflect how important a word is to a document in a collection or corpus).
When we define a Tokenizer point as “OOV” words unknown to its vocabulary, this way will keep our data from the loss:
from tensorflow.keras.preprocessing.text import Tokenizer
tokenizer = Tokenizer(oov_token="<OOV>")
tokens = tokenizer.fit_on_texts(train['remove_stop_words'])
# Turn text into sequences (word --> num )
text_sequences = tokenizer.texts_to_sequences(train['remove_stop_words'])# Turn text sequences into tf-idf sequences
tfidf_train =
tokenizer.sequences_to_matrix(text_sequences , mode='tfidf')
Tensorflow Tokenizer class has an embedded function sequence_to_matrix() with parameter mode — just chose mode=“tfidf” and wrap with it your text sequences. Now you gave weights/importance to each word in each text paragraph (when your set is small, the mode=“tfidf” may sufficiently improve your future results). Perfect! Let’s check the shape of the tfidf matrix; it should be of size (num_rows_in_set, vocabulary_size):

Well, that is all we need to do with the text to make it ready as input for a model. Don’t forget to repeat all transformation and feature engineering steps for the test set!!! In the end, you should get six arrays: three for the train and three for the test (sequences with tfidf, non-text features, and labels).
Finally, we can say: “we’ve done with text pre-processing and feature engineering”. The next step should be — create a classification model. It might be a large subject for the following article.
In this tutorial, you learned how to manipulate text data with Pandas and Numpy. Get familiar with the text preparation pipeline for being a model input. Saw a real data example of how to use Spacy and Tensorflow libraries for text. Now you understand what text pre-processing is.
The GoogleCollab, the Github.

{kind=link}