Overview of Item-Item Collaborative Filtering Recommendation System
Collaborative Filtering is widely used in building recommendation system. There are 2 main approaches in memory-based model, item-based and user-based. In practice, we usually have data with more users than the number of items and only a small portion of items get frequent rating, and this situation is called the long tail effect. The long tail effect usually implies the high data sparsity, and sparse data will affect the accuracy of our model.
In order to resolve the high sparsity issue, Item-based model often leads to faster online learning and better recommendation. In contrast, user-based model works better to detect users with special taste.
In this example, we will build a recommendation system using the item-based model.
GitHub Link: https://github.com/chiang9/Recommendation_system_pyspark/blob/main/Item_based_cf/movielen_item_based_cf.ipynb
Item-based Collaborative Filtering
Item-based collaborative filtering uses the rating of co-rated item to predict the rating on specific item.
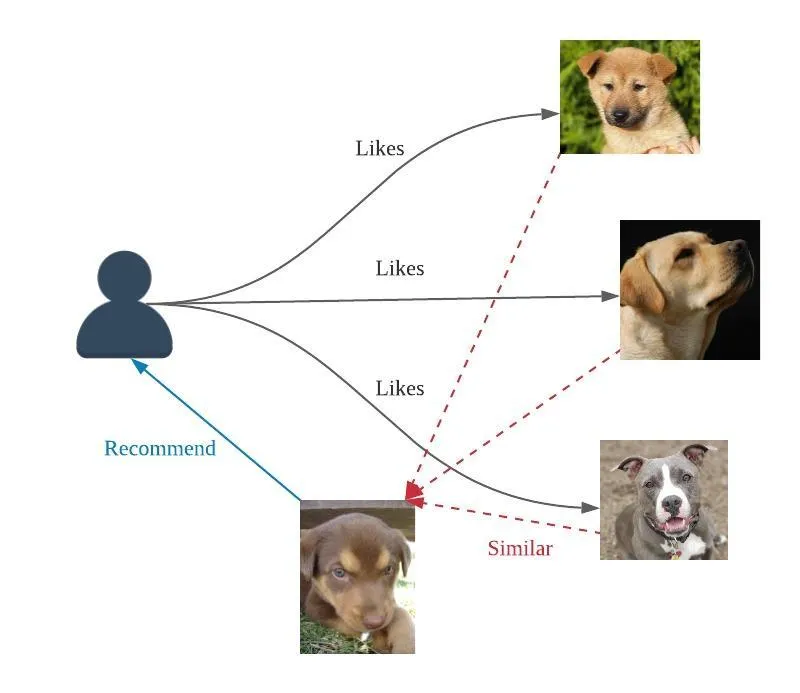
For example, we want to predict rating of user 2 on item 2.

To predict the rating,
- Find the co-rated items of user 2, which is item 1 and item 4
- Calculate the similarity between item 2 and item 1, 4
- Calculate the prediction based on the similarity and co-rated rating, such that

where w is the similarity, and r is the rating value.

Let’s Start

Next, we calculate the similarity. There are a lot of methods to calculate the similarity between the items, such as Jaccard similarity, Pearson correlation…etc.
In this example, we will use the cosine similarity.

As we can see from the heatmap, the data similarity is low due to the data sparsity.
Now, we will make prediction of the rating of user2 on item 3.
3.822284928259705We can test our model by using the RMSE.
RMSE = 1.0452369678411928Building the Recommendation System
In order to make the item-based model into a recommendation system, we calculate all ratings of the specific user. For instance, we want to recommend items to user 2, and we calculate all predicted ratings and select the top n items that user 2 might like.
Therefore, we will recommend the following 10 items to user 2 followed by the predicted rating.
[(1398, 4.704560704514258),
(861, 4.642353328817946),
(1641, 4.641362312762584),
(1439, 4.603460311402641),
(1123, 4.543079741085078),
(1346, 4.4948279147275025),
(1560, 4.4948279147275025),
(1333, 4.45874227212434),
(774, 4.389151878334362),
(1530, 4.379045803272321)]Improvement
As we can see from the RMSE, 1.045 is relatively high in our case since the rating score is from 1 to 5. In practice, our item-based model will not be enough to provide an effective model. There are several ways to improve our item-based model.
Default Voting
Focusing on the co-rated items (rather than global), we can analyze the user’s behaviors to change the weight of the votes. For example,
- Reducing the weight of users that have fewer than 50 rate history
- Use average of a small group of co-rated items as default voting to extend the user’s voting history
Case Amplification
Amplifying the weight of each vote. We amplify the high similarity and punish the low similarity ratings, such that

Imputation Boosted CF
When we are facing an extremely sparse dataset, we can use some imputation technique to fill in the missing data, for example, linear regression, SVM, naive Bayes…etc.
Hybrid Model
We can combine with other recommendation system model to form a hybrid model, for example we can take the prediction from user-based model into account, and give a better result.
Conclusion
In practice, it is not enough to merely implement the item-based model, we need to combine with other strategies depending on the datasets. In the next post, we enhance our item-based model.
Have a nice day.
Learn more: