Apple Intelligence: Approfondimento Tecnico sui Foundation Models di Cupertino
On-device laddove possibile, sui server Apple quando le performances lo richiedono
Per gli smanettoni affezionati di casa Apple, la Worldwide Developer Conference (WWDC) è un appuntamento immancabile ogni anno. Quest anno Apple ha deciso — come praticamente ogni altra azienda sul mercato — di non farsi trovare impreparata nel campo AI, annunciando una serie di features. Ovunque su internet è presente un recap del WWDC 2024, quindi non ci dilungheremo molto a riguardo.
Analizzeremo invece nel dettaglio un altro annuncio pubblico dell’azienda di Cupertino: i dettagli tecnici sui modelli di AI, o foundation models, che verranno utilizzati in tutta la gamma Apple Intelligence — integrato in iOS 18, iPadOS 18, e macOS Sequoia. Questi modelli rappresentano una pietra miliare tecnologica, con potenziali implicazioni che vanno oltre l’ecosistema Apple. In questo blog, esploreremo i dettagli tecnici e le innovazioni presentate da Apple. Nel caso voleste approfondire, consigliamo caldamente la lettura del blog ufficiale “Introducing Apple’s On-Device and Server Foundation Models”, linkato qui sotto.
I modelli di Apple

In primo luogo, è importante notare come Apple faccia attenzione a parlare di Foundation Models, e non di Large Language Models. Questo è un segnale importante per il futuro multi-modale dell’AI Generativa che va (finalmente!) ben oltre i chatbot e le applicazioni di linguaggio naturale.
Apple implementa una distinzione chiara tra i modelli che girano on-device e quelli che operano nel cloud:
- Modelli “On-Device”: Questi modelli sono ottimizzati per eseguire direttamente sui dispositivi degli utenti, come iPhone e iPad. Esempi includono modelli di riconoscimento facciale, riconoscimento vocale per Siri, e algoritmi di fotografia computazionale. L’esecuzione on-device garantisce tempi di risposta rapidi e migliora la privacy, poiché i dati sensibili non lasciano il dispositivo.
- Modelli “Server”: I modelli che richiedono una maggiore potenza computazionale o che beneficiano dell’accesso a grandi quantità di dati centralizzati vengono eseguiti nel cloud. Esempi includono modelli di analisi dei dati medici su larga scala e modelli avanzati di previsione del comportamento utente. L’approccio cloud permette di sfruttare infrastrutture di calcolo scalabili e di aggiornare i modelli in tempo reale.
Il nuovo sistema Apple Intelligence utilizzerà Private Cloud Compute per garantire che qualsiasi dato processato sui suoi server cloud sia protetto in modo trasparente e verificabile. Molti dei modelli di AI generativa di Apple possono funzionare interamente su dispositivi con chip A17+ o M-series. Quando è richiesto un modello più grande per soddisfare una richiesta, Apple Intelligence invia solo i dati rilevanti ai server con Apple silicon. I dati dei clienti non saranno salvati né utilizzati per addestrare ulteriori modelli. Il codice server per Private Cloud Compute sarà accessibile pubblicamente, permettendo agli esperti indipendenti di verificare la promessa di privacy. Il sistema è crittograficamente configurato in modo che i dispositivi Apple “rifiutino di comunicare” con un server a meno che il suo software non sia stato pubblicamente registrato per l’ispezione.

Dal punto di vista tecnico, è interessante vedere come Apple abbia deciso di adottare lo standard degli Adapters, in particolare LoRA (Low-Rank Adaptation), per migliorare la flessibilità e l’efficienza dei suoi modelli di machine learning.
Per mantenere alta la qualità dei modelli, Apple ha sviluppato un nuovo framework che utilizza gli adattatori LoRA, incorporando una strategia di quantization (quantizzazione) mista a 2 bit e 4 bit.
Apple inoltre descrive l’uso della tecnica grouped-query attention per migliorare l’efficienza dei loro modelli. Questa tecnica suddivide le query in gruppi, riducendo la complessità computazionale dell’attenzione e permettendo una gestione più efficiente delle risorse, soprattutto nei modelli on-device.
Prestazioni e Benchmark
Con questo set di ottimizzazioni, su iPhone 15 Pro è possibile raggiungere una latenza time-to-first-token di circa 0,6 millisecondi per token di prompt, e una velocità di generazione di 30 tokens al secondo. Non sono molti se paragonati a performance stellari come quelle di Groq, ma è pur sempre tecnologia avanzata che gira nel dispositivo che abbiamo in tasca.
Nel technical report di Apple vengono messe a confronto le prestazioni dei modelli di Apple attraverso diverse metriche di valutazione umana e benchmark rispetto ai modelli stato dell’arte (Gemma-2B, Mistral-7B, Phi-3-mini, Gemma-7B rispetto al modello On-Device; GPT-4T, Mixtral-8x22B e DRBX-Instruct per il modello Server).

Un primo esempio di confronto sono le preferenze umane — a degli utenti viene chiesto quale output preferiscano fra due (o più) opzioni. In questi test, gli utenti hanno preferito il modello Apple On-Device:
- il 62% delle volte rispetto a Gemma-2B
- il 46% rispetto a Mistral-7B
- il 43% rispetto a Phi-3-mini
- il 41,6% rispetto a Gemma-7B
Anche il Modello Apple Server si è dimostrato molto performante, a livello di modelli come DBRX-Instruct (54%), GPT-3.5T (50%) e Mixtral-8x22B (44,7%), ma performando peggio di GPT-4T (28,5%).
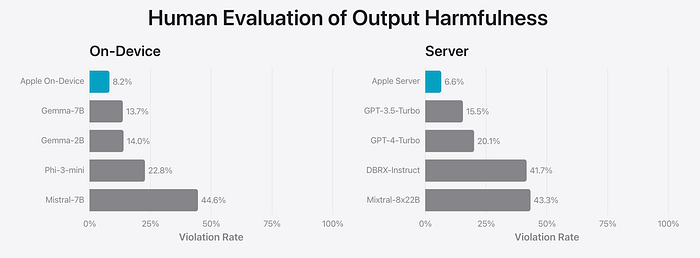
Particolare attenzione durante il processo di fine-tuning e allineamento sembra essere stato dato alla “pericolosità” dell’output. La metrica utilizzata è il tasso di violazione, che rappresenta la percentuale di output considerati dannosi o inappropriati. In questo grafico, sia il modello Apple On-Device che il modello Server risultano avere il punteggio più basso fra i modelli valutati.
Conclusione
La presentazione dei modelli di fondazione di Apple rappresenta un importante passo avanti nell’integrazione di tecnologie AI nell’ecosistema Apple. La combinazione di modelli on-device e server-based permette di ottimizzare sia le prestazioni che la privacy degli utenti. Le tecniche avanzate di quantizzazione e l’uso degli adattatori LoRA garantiscono un fine-tuning efficiente e personalizzato. I benchmark mostrano che i modelli Apple competono efficacemente con gli attuali standard del settore, dimostrando la loro capacità di fornire risposte rapide e di alta qualità. Questo posiziona Apple in modo strategico nel panorama dell’AI, promuovendo innovazioni che migliorano l’esperienza utente quotidiana.

