Improving Data Quality with Data Contracts
Data is critical to the success of GoCardless, whether it’s driving the decisions we make, detecting fraud, or powering intelligent products such as Success+.
However, we can only fully unlock the value of our data if it is of good quality. Users need to be able to discover the data, understand what it contains, and have the confidence to build on it.
At GoCardless, we guarantee that with a Data Contract.
The current state of GoCardless’ data
Today, our most critical data is streamed directly from the databases of our services, using an in-house change data capture (CDC) service. While this is an effective way to bring all our data in to one place, it means that all data consumers ultimately rely on the internal data model of our services. This has not been designed for consumption. It lacks documentation, requires knowledge of the service itself to use, and takes a lot of transformation and joining before you have something useful. Furthermore, it will change as the service evolves, causing unexpected breaking changes for the data consumers and giving them little confidence in the data.
Ultimately, we believe this data is of poor quality.
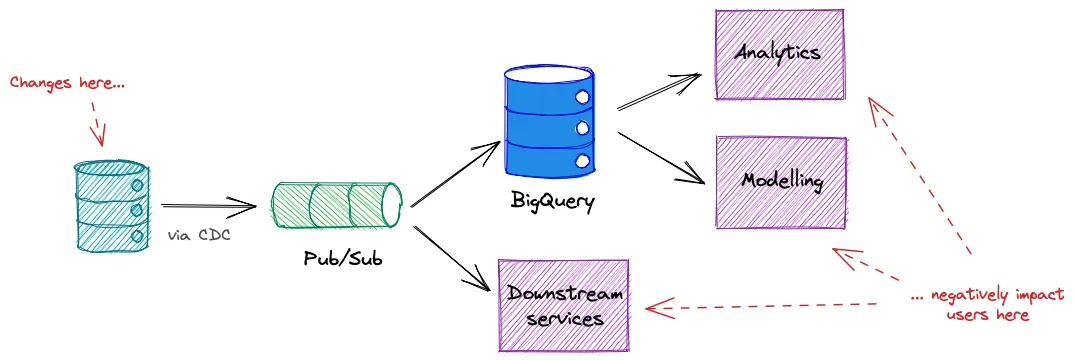
Many organisations turn to tools like data catalogs and anomaly detection to try and alleviate some of these issues, and build Data Engineering teams to manage the ingestion of data in to a centralised Data Warehouse. But these do nothing to improve the quality of your data. To do that, you need to go to the source of the data and how it is generated. You need to stop using the internal data models and build explicit interfaces between the data generators and the data consumers — much like an API.
We call that the Data Contract.
Introducing Data Contracts
So, what is a Data Contract?
Well, it’s an interface, a schema, and it’s a way to describe and document the data. But it’s more than that. It’s how we decide what data we’re going to expose from our service, and how we consider who will consume our data. It’s also how we manage our data and apply the right controls around our data. Essentially, it’s how we will do data at GoCardless.
All of this will be supported by best-in-class tooling, built by our Data Infrastructure team.
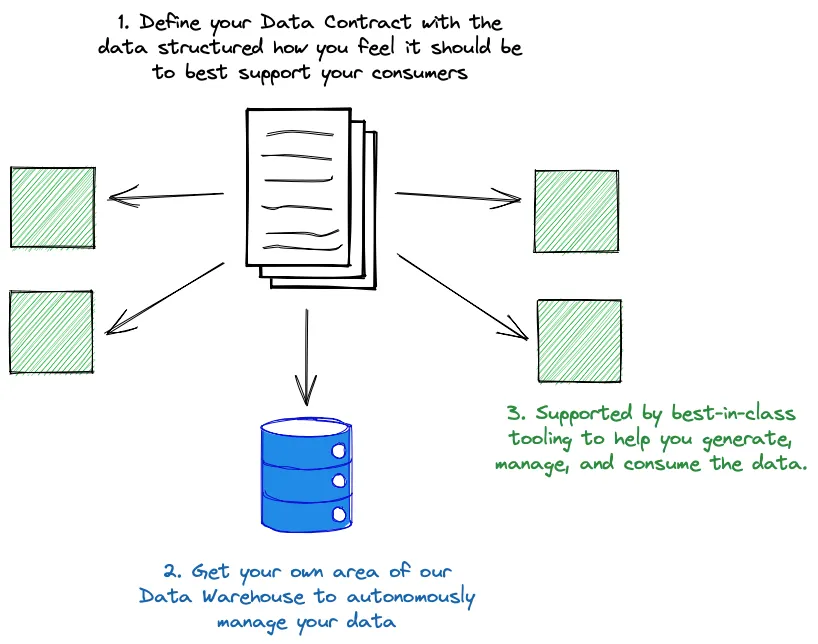
We’re making it easy for our data generators to make their data available to their consumers. We’re giving them the autonomy to decide what data to expose, and how to structure and manage that data, supported by our tooling.
We’re also supporting our data consumers to ensure they are getting the data they need in a format that works for them. One thing we’ve found is that our data consumers don’t necessarily know how to ask for the data they want, so we provide templates to help them describe their requirements.
The future of Data Contracts at GoCardless
It’s still early days for Data Contracts at GoCardless. We’ve just released the first version of the tooling, which at this stage simply allows users to define a contract and makes it easy for them to make the data available to consumers via Pub/Sub and BigQuery, by either writing directly to Pub/Sub or using the outbox pattern.

So far the reception has been great and we have a number of teams trying it out, with some already deployed to production.
Looking to the future, we have big plans for Data Contracts. All the data tooling we will provide in future will be built around Data Contracts, and users will have the autonomy to decide what they need for their use cases. We’ll be deprecating our CDC service and the centralised Data Platform and moving to decentralised datasets owned and managed by the data generators, whilst also making it easier to discover and use the data across the organisation.
In a future post we’ll describe how we’ve implemented Data Contracts and the tooling we have built for our data generators, which is our current focus as we aim to drive adoption. We’re confident in the benefits that Data Contracts will have for our data consumers once we have data generators on board.
