SPEC CPU® 2017 + GCP: Mid-2024 Performance Refresh
Benchmarking has always been an integral part of my analytical toolkit, ingrained in the way I approach problem-solving. The process of comparative analysis is not just a methodological necessity but a source of enjoyment, illuminating the nuances of virtually any activity — from cupping two distinct yet equally exquisite cups of Pink Bourbon to evaluating the CPU performance of cloud providers. In the realm of public cloud, such comparisons are crucial for making well-informed decisions.
Last year, I delved into this topic extensively through a four-part series titled Google Cloud Platform CPU Performance in the Eyes of SPEC CPU 2017, where I examined a broad spectrum of GCP machine types. Additionally, I provided an early look at the C3 instances and their Titanium architecture. However, the latter part of the year demanded a shift in focus towards pressing business priorities, temporarily pausing these benchmarking effort.
Now, approximately 16 months after my last SPEC article, I’m excited to return with new insights and updates in the ever-evolving landscape of cloud performance.

· SPEC CPU 2017
∘ SPEC CPU 2017 Benchmarks
· The Mid-2024 SPEC CPU System Refresh
∘ Platform Details
∘ Test Configurations
∘ Operating Environment
∘ Building Flags
∘ Setup Consistency
· Changes in the Mid-2024 Refresh
∘ Operating System Update
∘ Software and Toolchain
∘ New Hardware Platforms
∘ Enhanced Comparison Metrics
· Why Does Threading Matter?
∘ Single-Thread Performance: Responsiveness
∘ Multi-Thread Performance: Power of Parallelism
· The Tune Mode: A Playground for Optimization
∘ Base Performance: The Realistic Baseline
∘ Peak Performance: Pushing the Limits
∘ Why Test Both?
· Mid-2024 Results
∘ Estimated SPEC CPU® 2017 Scores
∘ C4 Pre-GA Testing
∘ SPEC CPU2017–1T — Base
∘ SPEC CPU2017–1T — Peak
∘ SPEC CPU2017 — nT — Base
∘ SPEC CPU2017 — nT — Peak
∘ N2/N2D/T2D/T2A/N4 — 16T vs 16C
∘ A Matter Of Compromises
∘ C2* vs. C3* vs. C4
· Runtime and Cost
· SPEC CPU 2017 General Rank
· Normalize Performance
· One picture worth a thousand words — Price to Performance
· Full Results
· Conclusions
· Changelog
SPEC CPU 2017
The Standard Performance Evaluation Corporation has long been the industry leader in CPU benchmarking, and their latest suite, SPEC CPU 2017, continues this legacy. Designed to emulate real-world user applications, it offers a rigorous assessment of a system’s CPU performance, including its cache and memory subsystems.
- Versatility in Benchmarking: The suite allows for building various benchmarks using different compilers and flags. This flexibility ensures that users can tailor the benchmarks to their specific needs and configurations.
- Real-World Relevance: Unlike synthetic benchmarks, most programs in the SPEC CPU 2017 suite are drawn from actual end-user applications. This approach provides more accurate and relevant performance metrics.
- Strict Validation Process: Any result submitted to the official SPEC repository undergoes stringent validation. Disqualification can happen and with industry-wide impact. This ensures the reliability and credibility of the benchmark results.
- Industry Standard: With its unique mix of features and rigorous testing processes, SPEC CPU 2017 is widely regarded as the gold standard in CPU performance evaluation.
By focusing on real-world applications and maintaining a high level of validation, SPEC CPU 2017 provides a robust, repeatable, and reliable measure of CPU performance.

SPEC CPU primarily focuses on traditional CPU workloads, which are designed to evaluate the performance of general-purpose processors. However, modern CPU architectures have evolved to include hardware offloads and specialized accelerators that significantly enhance workload execution beyond the capabilities of traditional superscalar out-of-order multi-core CPUs. One example among all, machine learning can make extensive use of Intel’s bfloat16, VNNI, AVX-512, and AMX technologies by improving computational efficiency, reducing memory usage, and accelerating key mathematic operations such as Matrix Multiplications and Batch Normalization and Processing. The SPEC consortium is well aware of this evolving landscape.
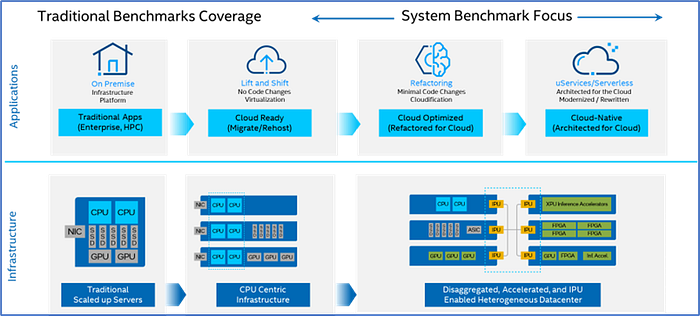
Despite these advancements, quantifying the overall performance and quality of a general-purpose CPU remains a complex challenge. SPEC CPU benchmarks aim to solving this by providing a standardized set of tests that measure various aspects of CPU performance, thereby offering a comprehensive evaluation of a processor’s capabilities.
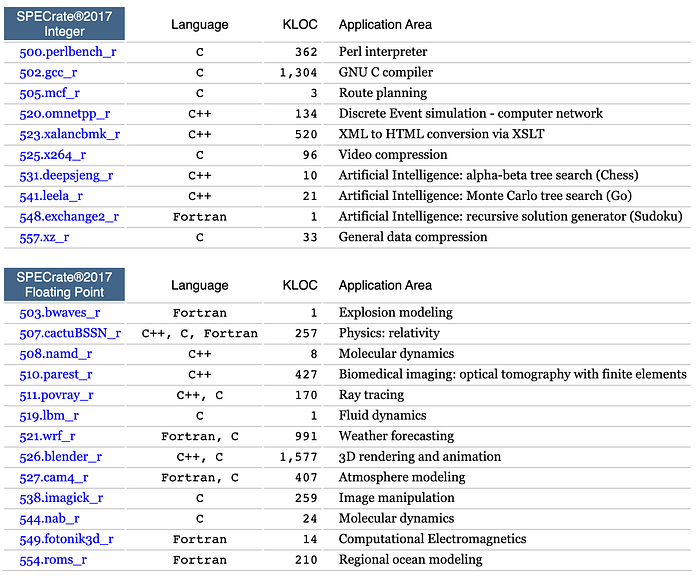
SPEC CPU 2017 Benchmarks
These benchmarks are crafted to simulate real-world applications that depend heavily on integer operations and floating-point computations. The SPEC CPU 2017 suite comes in two main variants: Speed, intended for single-thread analysis, and Rate, designed for multi-thread evaluation. According to Anandtech, both variants exhibit similar performance characteristics, suggesting that their scaling should be almost identical. Moreover, the Rate benchmarks are up to 5 times faster to execute, making them more effective for testing. Consequently, the Rate suite is generally utilized. Below is the list of tests.
The Mid-2024 SPEC CPU System Refresh
Follows the characteristic of the Mid-2024 refresh.
Platform Details
- SPEC CPU 2017, covering all Integer and Floating Point Rate tests.
- Tuning Modes: Both Base and Peak tuning modes, with specific compiler flags listed below.
- Machine Types:
– N1: Intel Sandy Bridge, Ivy Bridge, Haswell, Broadwell, and Skylake.
– N2/C2: Intel Cascade Lake.
– N2: Intel Ice Lake.
– N2D: AMD Rome, AMD Milan.
– T2D/C2D: AMD Milan.
– C3: Intel Sapphire Rapids.
– C3D: AMD Genoa.
– N4/C4: Intel Emerald Rapids.
– T2A: Ampere Altra.

Test Configurations
- Single-Thread Tests: CPU pinning on CPU1.
- Multi-Thread Tests: Utilization of all visible vCPUs in the system.
- CPU Topology:
– Consistent configuration across all tests: 1 NUMA node, 8 physical CPUs (e.g.c4-standard-16), and 16 vCPUs exposed when SMT is supported, otherwise 8 vCPUs.
– Exception:c3-highcpu-22which consists of 11 physical cores through GCE visible core feature only 8 cores are enabled.
Operating Environment
- Operating System: Ubuntu 24.04.
- Kernel Version:
6.8.0–1008-gcp. - GNU C Library: Version
2.39–0ubuntu8.2. - GNU Binutils: Version
2.42–4ubuntu2. - Compiler: GCC 13.3.0, used uniformly across all benchmarks.
- GCE base image:
– x86–64:ubuntu-2404-noble-amd64-v20240607
– AArch64:ubuntu-2404-noble-arm64-v20240607 - SPEC CPU 2017: version 1.1.9.
Building Flags
All benchmarks were recompiled before execution using consistent flags across different platforms, with some exceptions:
- Base x86–64 Benchmarks:
-O3 -march=x86–64-v3 -mtune=core-avx2
– Exceptions (Intel Sandy Bridge and Ivy Bridge, due to lack of AVX2):-O3 -march=x86–64-v2 -mtune=corei7-avx - Peak x86–64 Benchmarks:
-Ofast -march=native -flto - Base AArch64 Benchmarks:
-O3 -march=armv8.2-a - Peak AArch64 Benchmarks:
-Ofast -mcpu=native -flto
In a future update, I might consider using the -O2 optimization level for the Base benchmarks. However, both Chips and Cheese, as well as Intel, argue that -O3 should be the standard optimization level at this point in time, and their perspective is valid.
Setup Consistency
The testing environment has been meticulously set up to ensure consistency:
- Minimum Variables: Reducing variability across tests to the bare minimum: same OS, software stack, libraries, versions, building flags, and even GCP region and zone.
- Close Test Dates: All tests were conducted within a narrow window (June 14th to June 16th).
- Several Iterations: Each benchmark has been executed three times.
By focusing on consistency across hardware, software, and timing, the results aim to provide a reliable comparison across different platforms and configurations.
Changes in the Mid-2024 Refresh
The mid-2024 refresh introduces several notable changes to the SPEC CPU benchmarking environment:
Operating System Update
- New target OS: The testing environment now uses Ubuntu 24.04.
- An attempt was made to use RHEL 9.4, but its outdated Binutils prevented building code with AVX512 optimizations required for Peak tuning mode.
- Future Plans: compile latest C Library and Binutils. Until then, unless Red Hat updates Binutils, RHEL will not be part of the testing environment.
Software and Toolchain
- Good news, the upstream PerfKit Benchmarker version has been utilized, all previously developed patches are now mainlined 🎉.
- For this test, tag f465ece3 is used throughout all tests.
– PKB versionv1.12.0–4625-gf465ece3. - The latest SPEC CPU 2017 version 1.1.9 is used.
New Hardware Platforms
- 3rd GCE Generation C3D based on AMD Genoa: Latest AMD architecture using the Zen4 μArch with (I should add finally) bfloat16, VNNI, and AVX–512 support.
- 4th GCE Generation N4 and C4, based on Intel Emerald Rapids: Latest Intel architecture using the Raptor Cove μArch with advance features support like AMX.
- Future Plans: Google Axion — ongoing effort to include Axion in the testing suite, so stay tuned for updates 😬.
Enhanced Comparison Metrics
- Normalized Performance Section: A new section has been added to evaluate Instruction Per Cycle throughput of raw CPU cores, factoring in core frequency and count counts.
– Baseline Frequency: The ISO frequency used for normalization is set at 2.7 GHz, matching the lowest frequency among Intel Skylake and AMD Rome CPUs.
– Baseline Core Count: The ISO Core Count used for normalization is the respective physical core count of each CPU.
These updates aim to enhance the comprehensiveness and accuracy of the this report, making the results more relevant.
Why Does Threading Matter?
In the world of modern computing, the concept of “threads” is fundamental. A thread is like a tiny worker within your CPU, capable of executing instructions independently. Your computer’s ability to juggle multiple threads simultaneously is key to its overall performance, especially when running demanding workloads. Why single-thread and multi-thread performance testing?
Single-Thread Performance: Responsiveness
- What it measures: A CPU’s ability to execute instructions quickly on a single thread. This is crucial for tasks that can’t be easily divided, such as many user interface interactions, gaming logic, or certain scientific calculations.
- Why it matters:
– User experience: A snappy, responsive system often comes down to strong single-thread performance.
– Bottlenecks: Even in multi-threaded scenarios, the slowest single-threaded component can hold back the entire system.
Multi-Thread Performance: Power of Parallelism
- What it measures: How well a CPU can handle multiple threads simultaneously. This is critical for workloads that can be split into smaller tasks, such as video rendering, simulation, or database operations.
- Why it matters:
– Maximum throughput: Multi-thread performance is the key to maximizing a system’s potential for handling heavy workloads.
– Real-world scenarios: Many modern applications are designed to leverage multiple threads, making this a crucial performance metric.
The Tune Mode: A Playground for Optimization
Tune mode allows for compiler and system-level optimizations to extract the maximum potential from the hardware.
Base Performance: The Realistic Baseline
- What it represents:
– A reasonable level of optimization that most application could expect to achieve on their systems.
– Prioritizes stability and portability across different x86–64 processors. - Why it matters:
– Provides a fair comparison point for different systems, as it minimizes the impact of highly specialized optimizations.
– Establishes a performance baseline that reflects real-world usage scenarios for many users.
Peak Performance: Pushing the Limits
- What it represents: An aggressive optimization strategy aimed at extracting the absolute maximum performance from the system.
- Why it matters: Reveals the theoretical peak performance achievable on a particular system, providing insights into its limits.
Why Test Both?
By testing both Base and Peak performance in SPEC CPU 2017’s Tune mode, you gain valuable insights into the full spectrum of a system’s capabilities. This knowledge empowers you to make informed decisions about optimization strategies, hardware choices, and software development approaches.
Mid-2024 Results
Estimated SPEC CPU® 2017 Scores
Before delving into the performance numbers, it’s important to note that all SPEC CPU® 2017 scores mentioned here are estimated results. These estimates have not been officially submitted or reviewed by the SPEC organization.
C4 Pre-GA Testing
Initial performance tests were conducted during the pre-GA availability phase of the GCP C4 Machine Family. Subsequent tests after general availability confirmed no significant performance changes.
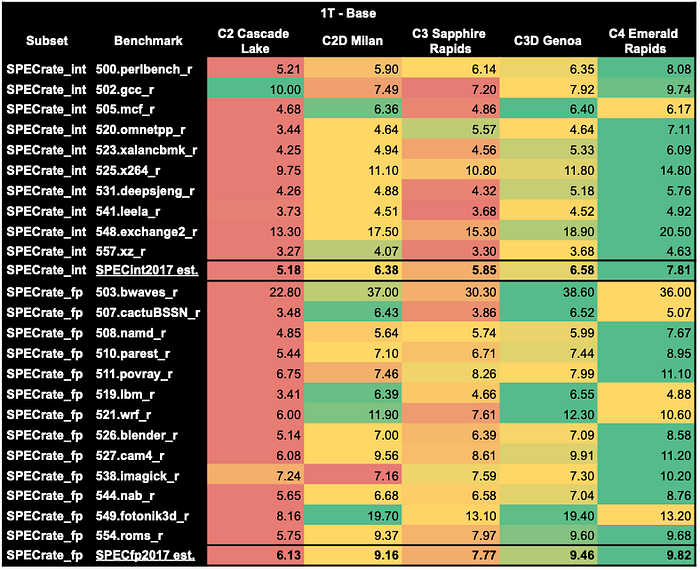
SPEC CPU2017–1T — Base

Let’s open the dance with a classic, the single-thread results for Tune mode Base. In the heat map, darker red indicates poorer performance, while brighter green signals better results.
Last year’s champion, the C2D AMD Milan, dominated not only in single-threaded benchmarks but across the entire suite. Let’s see how it stack up this time around.
AMD vs. Intel: Benchmark Breakdown
AMD Genoa and other AMD CPUs excelled in the following single-thread benchmarks:
- 503.bwaves_r — wave propagation in large-scale oceanic systems.
- 519.lbm_r — modeling complex fluid systems.
- 521.wrf_r — weather forecasting model.
- 549.fotonik3d_r — simulation of light propagation through a photonic device.
AMD’s historical strong FPU throughput is evident here.
On the other hand, Intel Emerald Rapids, particularly the C4 shape, is the top performer in most other benchmarks, especially throughout the Integer results, claiming the overall best performance title this year.
Low Performers
- N1 Series: Showing its age, the entire N1 series lagged behind.
- Ampere Altra (T2A): Particularly underwhelming, earning the title of the worst performer among the previous generation chips.
- C2 Generation: Surprisingly, even the compute-optimized C2 variants didn’t showcase great performance.
SPEC CPU2017–1T — Peak

Let’s dive into the results for Tune mode Peak. The overall performance landscape remains largely unchanged from the Base mode, but a couple of noteworthy points emerge:
- In single-thread FP benchmarks, C3D shows nearly identical performance to C4.
- C4 lags behind in the 507.cactuBSSN_r benchmark, which deals with solving Einstein’s equations in a vacuum.
- The underperformance is likely because the code doesn’t leverage AVX512 or AMX optimizations. Simply enabling AVX512/AMX isn’t enough; the code must also be designed to take advantage of these advanced vector extensions to see any meaningful speedup.
SPEC CPU2017 — nT — Base
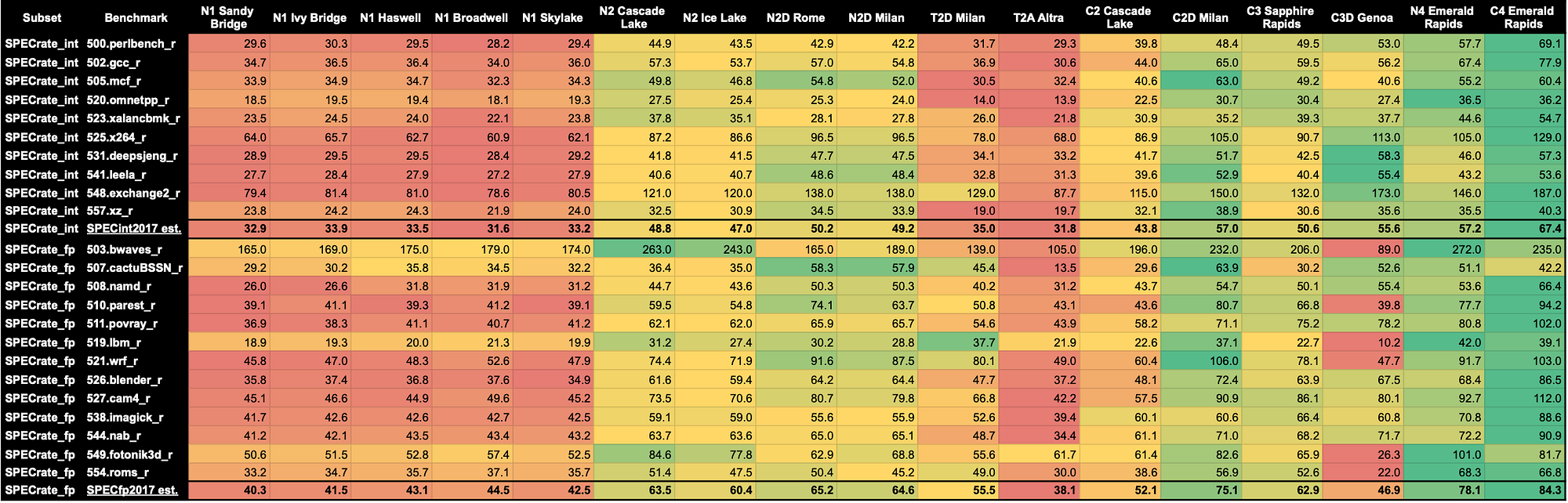
(Dramatic?) turning point for C3D. These are the multi-thread tests for the Tune mode Base. First things first, C4 leads the charts once again. As expected, older Intel N1 architectures show their age, with newer cores outperforming them by up to two times. T2A Ampere Altra also disappoints with weak performance.
C3D (AMD Genoa) Performance
Surprisingly, C3D doesn’t scale performance consistently across benchmarks.
- Integer Performance: Comparable to C2D (AMD Milan)
- Floating Point Performance: Wildly inconsistent, sometimes performing as poorly as the decade-old N1 architectures.
The weird C3D results were triple-checked:
- Testing different zones and different regions.
- Running RHEL9 Base Tune tests.
- Using GCC 12.2, 12.4, 13.3, and even latest GCC 14.1.
- Using AMD-specific Zen4 flags with
-march=znver4.
Despite extensive checks, the poor results persisted. Interestingly, single-thread performance is strong, suggesting the issue may not lie with the build itself. Instead, it could stem from underlying GCP optimization issues or the method AMD uses to facilitate communication between cores, possibly related to the NPS setup.
C4 and N4 Intel Emerald Rapids Numbers
- C4: Maintains a strong lead but shows weaker results in 507.cactuBSSN_r and 549.fotonik3d_r benchmarks. Overall, remains the top performer by a significant margin.
- N4: Offers impressive gains, outperforming the former N2 generation by about 21%. Remarkably, N4 even surpasses C2D. Of course the Compute Optimized machine types don’t just deliver high performance but most importantly consistent ones — see my white-paper Forwarding over 100 Mpps with FD.io VPP on x86 about it.
SPEC CPU2017 — nT — Peak

Tune mode Peak in multi-threading scenario doesn’t significantly change the previous picture. But it’s unbelievable that C3D continues to lose performance — another 5% degradation in FP 😭.
N2/N2D/T2D/T2A/N4 — 16T vs 16C

In this round, I’m expanding the scope beyond the consistent CPU topology focus (8 physical cores / 16 vCPUs with SMT enabled) to include configurations with 16 threads and 16 cores. Specifically, I am evaluating the t2d-standard-16 and t2a-standard-16 machine types for multi-thread performance. This topic has generated intense debate in previous testing series, typically highlighting a trade-off between machine throughput and its limitations.
A Matter Of Compromises
T2D AMD Milan
- Multi-thread Performance: While the 16 cores of T2D AMD Milan deliver impressive multi-threaded results and strong single-thread scores, significant limitations exist.
- T2D Limitations: As a second-generation GCE machine type, T2D lacks the new features of the third generation. Its impact varies by workload. Additionally, the AMD Milan core does not support AVX512 or VNNI, both essential for ML inference.
T2A Ampere Altra
- Multi-thread Performance: Despite its single-thread performance issues, T2A shows only moderate improvements in multi-thread scenarios.
- T2A Limitations: Unlike T2D, which delivers excellent single and multi-thread results, T2A fails across the board. It has poor single-thread performance and additional constraints, including limited ARM support and a lack of SUD and CUD discounts.
C2* vs. C3* vs. C4
Let’s now glance over a more equitable comparison examining the improvements in the latest Intel and AMD CPUs, especially when paired with the Google third-generation machines that incorporate the IPU architecture. From a single-thread performance standpoint, besides Cascade Lake’s die-shrink of the ancient Skylake architecture, there have been significant improvements across the board. Both Intel and AMD have managed to deliver impressive results, I’d be pretty happy with any of them. As usual, while aggregate scores provide a useful quick comparison, the real insights lie within the individual results.
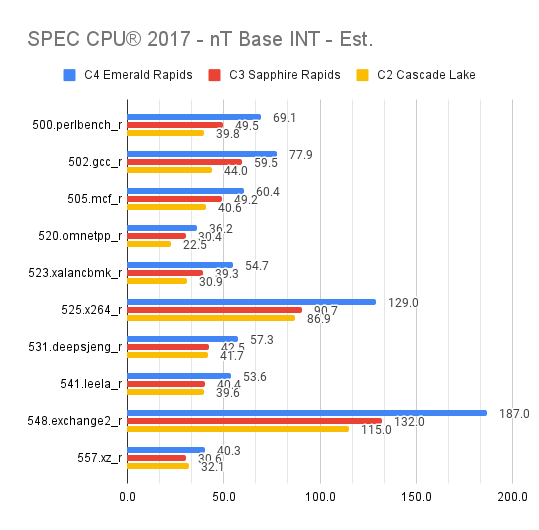
INT multi-thread results reinforce Emerald Rapids’ dominance, with C4 consistently outperforming C3 Sapphire Rapids by a minimum of 19% and an average of 33%.
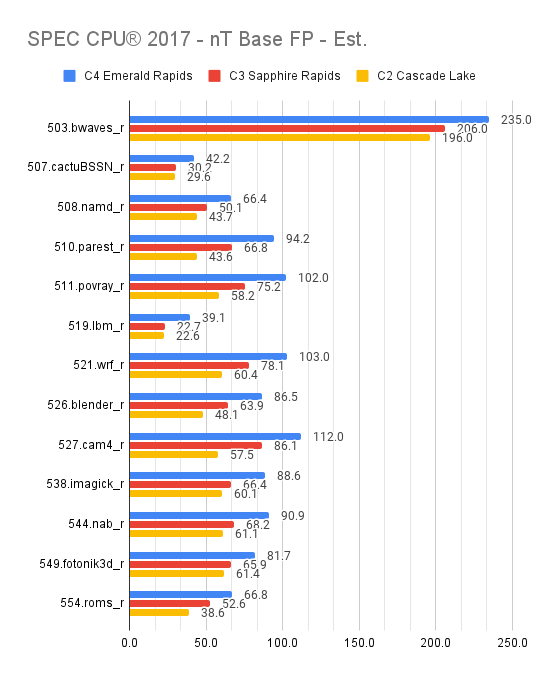
In the FP multi-thread results, 503.bwaves_r is the only instance where C4’s throughput is just 14% higher than C3 😂; excluding it, C4’s minimum lead over C3 jumps to 23% and averages over 36%, with an overall lead of 34%, making a c3-highcpu-22 roughly comparable to a c4-standard-16.
From a GCP infrastructural cost and software licensing standpoint, C4 represents a significant win for FinOps and platform optimization.
Runtime and Cost

As in previous instances, I aimed to incorporate the total runtime and associated costs of these experiments. It is important to note that the runtime costs for the PKB machine are not included in this calculation, nor are the additional expenses for numerous C3D tests and storage costs, including both persistent and hyperdisk storage. Nevertheless, the cumulative cost for over 10 days of testing amounts to just under $500. Considering the current emphasis on cost reduction, this spending is quite reasonable. For those seeking to make an informed decision, this level of testing demonstrates that it is financially feasible.
SPEC CPU 2017 General Rank

This graph presents a more visually accessible version of the tabular data available in the previous chapters. It combines both Integer and Floating Point scores, revealing four distinct performance clusters:
- 1st Generation GCE: As expected, N1 is the lowest performer among the group.
- Mid-Tier Performers: This cluster includes N2, N2D, T2D, and C2. Interestingly, C2 performs below its counterpart, N2, which is somewhat surprising.
- T2A: This generation barely holds its own, comparable mainly to N1 in terms of performance.
- High Performers: This cluster includes C3, C3D, N4, C4, and surprisingly, C2D. These configurations show excellent single-thread performance, with C4 representing a significant generational leap.
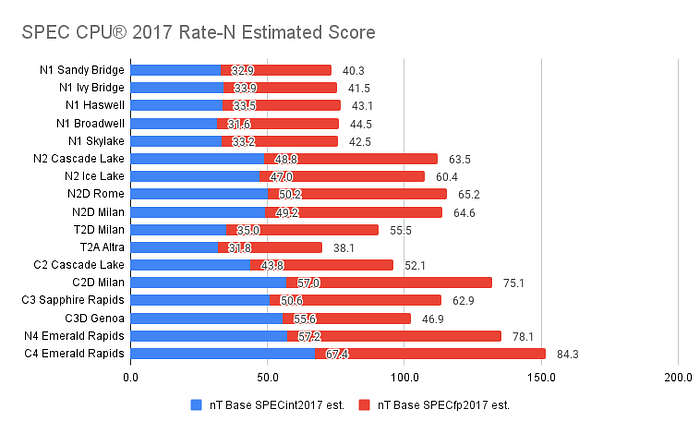
Continuing with the multi-threaded results:
- 1st Generation GCE: Slightly outperforms T2A, but remains at the lower end of the performance spectrum.
- 2nd Generation GCE
– Excluding T2A and C2D, the second-generation machines (N2, N2D, T2D, etc.) exhibit relatively similar performance levels.
– Particularly strong in FP results for all AMD platforms.
– Only Intel Emerald Rapids is able to outperform AMD’s FP results. - 3rd and 4th GCE Generation
– These generations show significantly more variation in performance compared to the first and second-generations.
– C4 Emerges as the absolute best, marking a substantial generational improvement. - C2D Strikes Back: Despite being part of the second-generation, C2D delivers impressive performance, even surpassing C3, C3D, and N4.
- C3D Multi-Thread Performance: poor 😓 — topic extensively covered in previous chapters.
Normalize Performance

This section is a new addition to the SPEC CPU series. While I aimed to minimize variables by running all tests together to reduce variations in the underlying platform, the hardware characteristics unique to each machine type, such as CPU frequency and SMT enablement, are out of scope by definition when making a comparison.
However, results at ISO frequency and ISO core count provide a useful way to standardize results even with such differences in the mix. In CPU benchmarking, ISO frequency refers to testing different processors at a consistent clock frequency to ensure a fair comparison. ‘ISO’ signifies ‘equal’ conditions, meaning CPUs are evaluated under the same operating circumstances.
This comparison uses the Multi-Thread Base tune mode results: each individual score is divided by the number of physical cores, then divided again by the CPU’s all-core turbo frequency, and finally multiplied by the lowest frequency of the set (2.7GHz from Intel Skylake and AMD Rome).
- The results reveal lower CPU throughput for N1s, T2D, T2A, C2, C3D, and somewhat low-ish even for N2s.
- AMD is the leader across several generations for N2D and C2D. C2D performs exceptionally well, closely rivaling N4.
- Intel Emerald Rapids, in the forms of N4 and especially C4, gain the absolute performer crown.

Following results in comparison to C4:
- Close Performers (<2% FP, <10% INT from C4)
– C2D and N4: Nearly identical to C4 in both FP and INT scores. - Moderate Performers (<20% away from C4)
– N2D Rome and Milan: Relatively close to C4. - Moderately Distant Performers (>20% but <40% away from C4)
– Various platforms including C3, C3D (INT only), T2Ds, and N2s. - Distant Performers (>40% away in both FP and INT from C4)
– C2, T2As, all N1s, and C3D (FP only): Significantly inferior to C4.
One picture worth a thousand words — Price to Performance
The price/performance chart provides valuable insights into the cost-effectiveness of various machine types when considering their computational power as measured by SPEC CPU2017. The blue bars represent the raw price/performance ratio, calculated by dividing the list price by the cumulative Integer and Floating-Point scores. The introduction of the SUD cost saving schema is represented by the red line.
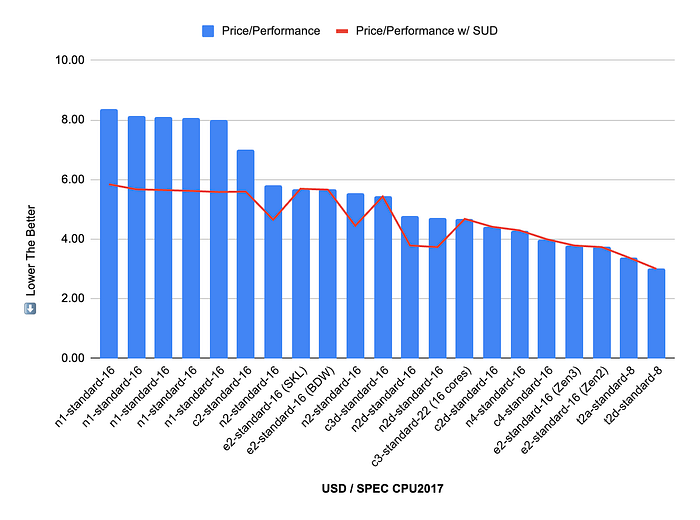
- Several considerations made in last year’s SPEC CPU work remain pertinent.
- First-generation GCE displays a higher cost per unit of performance, rendering them difficult to recommend.
- The C2 instances, though costly for the performance they provide, offer predictable performance typical of the Compute Optimized machine family on Intel Cascade Lake processors, which are essential for many Telco DPDK applications, such as Cisco vMX.
- E2 instances can achieve a good price/performance ratio; however, it is worth noting that you do not get to control the underlying CPU, resulting in variable throughput ranging from barely good to decent.
- The C3D instances are outliers in terms of performance from a negative standpoint, yet their aggressive pricing situates them marginally better on the price/performance chart.
- N2D, C3, and C2D deliver comparable price/performance metrics. It should be noted that the C3 instances are estimated with 16 vCPUs, a configuration not available on GCP. However, with an equivalent vCPU count, C3 offers competitive price/performance along with advanced features from the newer generation.
- Although C3 and C4 instances share the same price point, the superior performance of C4 significantly diminishes the value proposition of C3.
- The latest generation, N4 and C4, are packed with advanced features, exhibiting outstanding performance and a favorable pricing model, making them highly recommended.
- Lastly, if the inherent compromises associated with T2D and T2A are acceptable, these machine types offer the best price/performance ratio of any GCP machine type.
Remember, there are no bad products, only bad prices.
Full Results
As per tradition, follows the complete access to the full test report, comprehensive of SPEC CPU logs, full tests breakdown, and PKB wrappers.
Conclusions
In wrapping up this mid-2024 refresh of SPEC CPU 2017 benchmarks on GCP, we’ve navigated a myriad of metrics, performance comparisons, and new technological advancements. This comprehensive analysis underscores both the evolving landscape of cloud computing and the enduring necessity of rigorous benchmarking in making informed architectural decisions.
The introduction of new hardware platforms such as the Intel Emerald Rapids and AMD Genoa CPUs, coupled with an updated software environment, highlights GCP’s commitment to staying at the forefront of technological advancement. Through detailed comparisons and rigorous testing, we’ve seen that while older machine types continue to fulfill basic needs, the new generation instances like C4, N4, and even some surprises like C2D, set a new bar for performance and cost-efficiency.
Single-thread and multi-thread performance assessments reveal the real-world applicability of these platforms, emphasizing their strengths and weaknesses across diverse workloads. Particularly noteworthy is the continued dominance of Intel’s Emerald Rapids in the multi-thread checks and AMD’s effectiveness in floating-point operations.
However, it’s important to acknowledge the limitations and compromises inherent in any benchmarking exercise.
- While C4 emerges as the top performer, the reality of deployment scenarios means choices need to be tailored to specific use cases and budgets. The normalization techniques applied here provide a valuable tool for leveling the playing field in these comparisons, but there’s no substitute for context-specific testing.
- The cost-performance analysis serves as a practical guide for enterprises aiming to balance their financial constraints against their need for high computational power.
In conclusion, the insights gathered from this benchmarking exercise not only illuminate the capabilities of GCP’s machine types but also provide a framework for future evaluations. The precise and methodical approach elaborated here aims to empower businesses to make data-driven decisions, fostering a more informed, strategic adoption of cloud resources.
Changelog
- July 9th, 2024 — public release.
- July 17th, 2024 — correct
c4-standard-16total memory count (64GB to 60GB) and consequentially reduced its pricing. - July 22nd, 2024 — correct reported memory amount for
t2d-standard-16(32 -> 64GB),t2a-standard-8(16 -> 32GB) andt2d-standard-16(16 -> 64GB). Also, fixed C3 instance name used in testing fromc3-standard-22toc3-highcpu-22. - August 20th, 2024 — removed the pre-GA designation from the C4 instance family and adjusted C3 pricing to match C4.

