Building large-scale AI-powered search in Greenplum using pgvector and OpenAI
The exponential progress of AI models over the past year, such as ChatGPT, inspired many organisations to enhance user experiences and unlock the full potential of their unstructured data, from texts to images to videos, by unleashing Generative AI and Large Language Models (LLMs).
In this blog post, you’ll learn how to harness the power of vector similarity search of pgvector extension within Greenplum data warehouse and combine it with OpenAI models to extract valuable insights from textual data at Petabytes large scale and take advantage of Greenplum’s incredible MPP architecture.

Introduction:
Companies started looking for technologies and ways to augment their data platforms for AI and use large language models for their Chatbots, Recommendation Systems or Search Engines…
But one specific challenge has been managing and deploying these AI models and storing and querying ML-generated embeddings at scale.
What are embeddings?
Embeddings refer to transforming data or complex objects like texts, images or audio into a list of numbers in a high-dimensional space.
This technique is used in every machine learning (ML) or Deep Learning (DL) algorithm that enables capturing / understanding of the meaning and context of data (semantic relationships) and knowledge of complex relationships and patterns within the data (syntactic relationships).
You can use the resulting vector representations for various applications, such as information retrieval, image classification, natural language processing, etc.
The following diagram visually represents what this looks like for word embeddings in 2D space.

You can notice that semantically similar words are close together in the embedding. For example: “apple” word is closer to “orange” than “dog” or “cat”.
After generating embeddings, companies can perform similarity searches within the vector space and build an AI applications such as product recommendation systems ...
Storing embeddings in Greenplum using pgvector
Greenplum 7 is well equipped and ready to store and query Vector Embeddings at large scale thanks to pgvector extension. This brings vector database capabilities to the Greenplum data warehouse, which enables users to perform fast retrieval and efficient similarity searches.
Using pgvector in Greenplum, you can set up, operate, and scale databases for your ML-enabled applications.
For example, a streaming service can use pgvector to provide a list of film recommendations similar to the one you just watched.
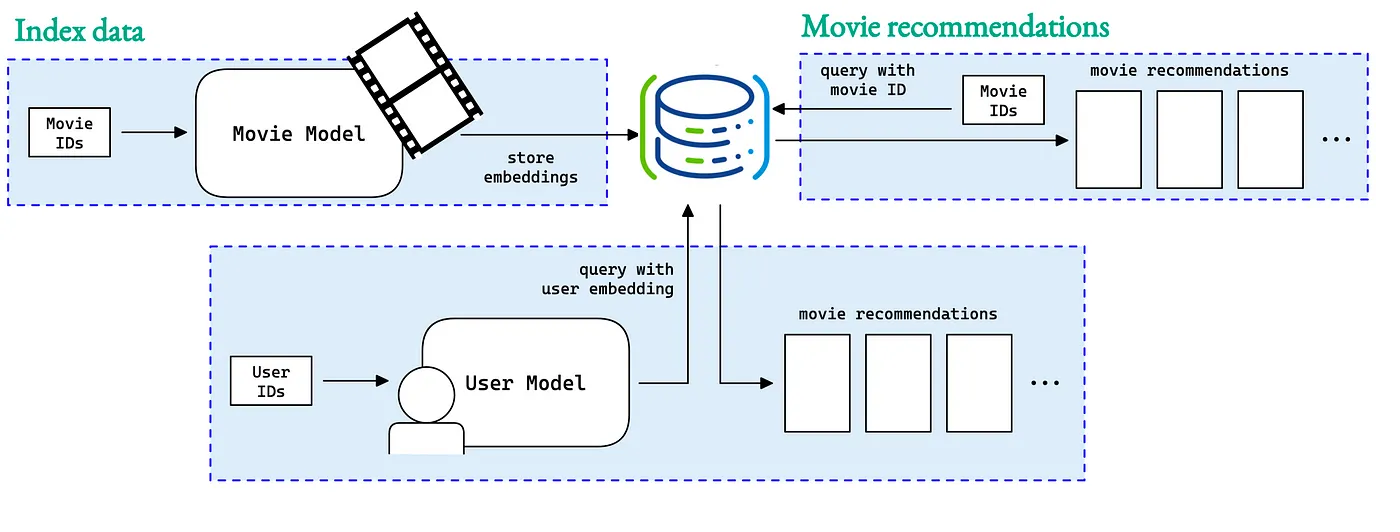
Why Greenplum & pgvector?
Many companies would like to store, query and perform vector semantic searches within their Entreprise Data Warehouse without managing another Vector database.
Fortunately, combining Greenplum and pgvector lets you build fast + scalable applications using embeddings from AI models and get to production sooner.
Build an AI-Assitant for your product documentation in Greenplum using pgvector and OpenAI.
Context:
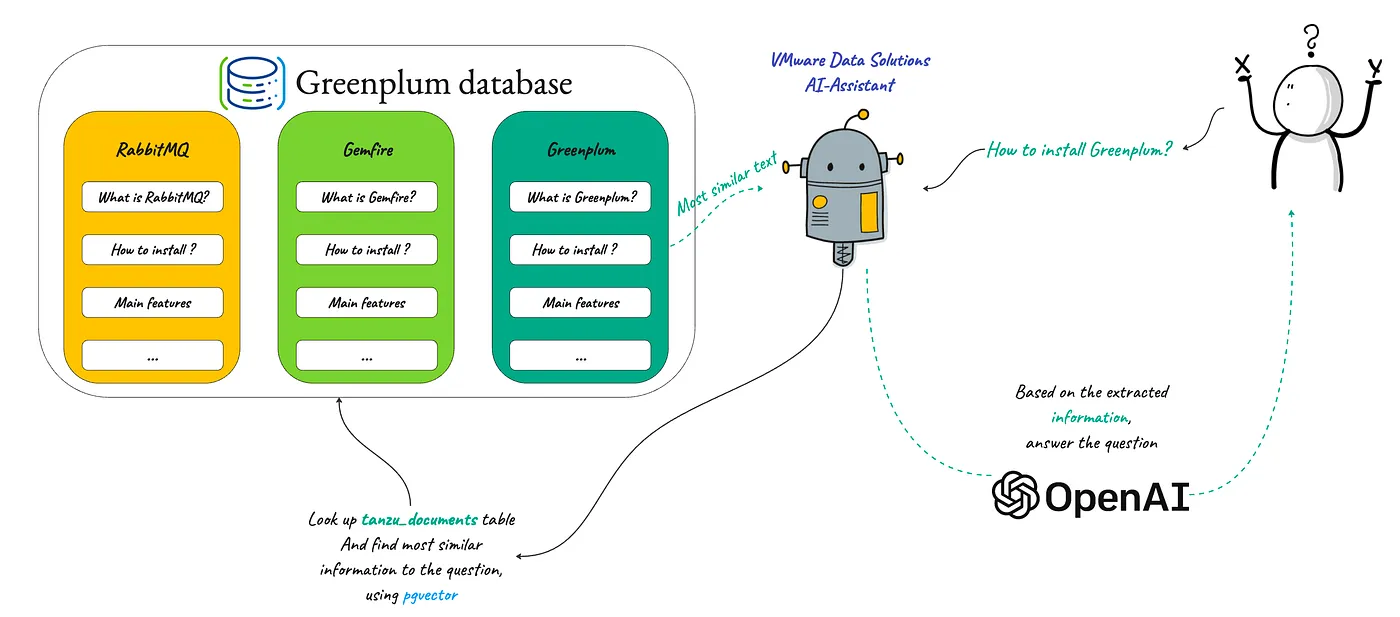
We have all used a Chatbot like ChatGPT before and found it great for casual, general-purpose question-answers, but you may have also noticed that ChatGPT falls short when deep and domain-specific knowledge is needed. Also, it makes up answers to fill its knowledge gaps and never cites its sources.
But how can we improve this? How can we build a ChatGPT that accurately searches suitable data sources and answers questions?
TThe answer is: that making product documentation searchable and supplying a task-specific prompt to OpenAI can result in more reliable results. In other words, we will ask pgvector to search for a suitable dataset from the Greenplum table when a user asks a question. Then, we will provide it to OpenAI as a reference document to answer the users’ queries.
Embeddings in practice:
In this section, we will see embeddings in practice and learn how to use the open-source pgvector extension for Greenplum, which facilitates the storage of embeddings and enables querying for a vector’s nearest neighbours.
We demonstrate this functionality by building an Intelligent Chatbot using OpenAI and empowering it with Semantic Text Search to have more domain-specific knowledge about VMware Data Solutions, capable of answering deep technical questions about Greenplum, RabbitMQ, Gemfire, VMware SQL and VMware Data Service Manager, as in the following figure:
The main steps are:
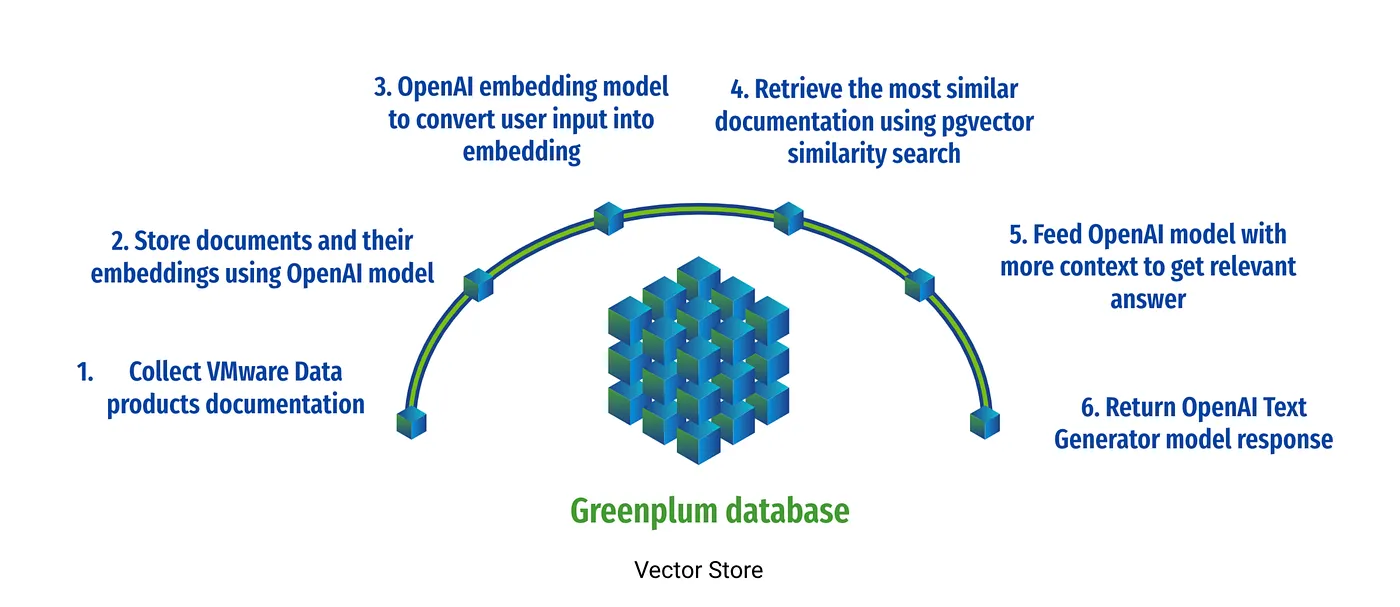
- Install & Enable the pgvector extension.
Following successful installation, you can start the storage of vector embeddings in Greenplum and perform semantic searches by enablingpgvectorrunning:
CREATE EXTENSION vector;2. Create a Product Documentation table with VECTOR data-type
Next, let’s create a table to store our products documentation and their embeddings:
CREATE TABLE tanzu_documents (
id bigserial primary key,
content text,
embedding vector(1536)
)
DISTRIBUTED BY (id)
;pgvector introduces a new data type called a vector. We create an embedding column with the vector data type in the code above. The size of the vector defines how many dimensions the vector holds. OpenAI's text-embedding-ada-002 model outputs 1536 dimensions, so that we will use that for our vector size.
Since we’re using OpenAI API in this post, install the openai package on every Greenplum host running:
gpssh -f gphostsfile -e 'pip3 install -y openai'We also create a text column named content to store the original product documentation text that produced this embedding.
Note: The table above is distributed by the “id” column across Greenplum segments,
pgvectorextension works seamlessly and perfectly with Greenplum features. Hence, adding pgvector’s efficiency in managing and searching through massive amounts of data to Greenplum’s MPP capabilities from distribution to partitioning enable Greenplum users to build scalable AI applications.
3. Greenplum PL/Python Function to get OpenAI embeddings
Now, we should generate embeddings for our documents; here, we’ll use the OpenAI text-embedding-ada-002 model API to generate embeddings from the text.
The best way to do it is by creating a Python function inside Greenplum database leveragingPL/Python3u Procedural Language. The following Greenplum Python function returns a vectorembeddings for each input document.
CREATE OR REPLACE FUNCTION get_embeddings(content text)
RETURNS VECTOR
AS
$$
import openai
import os
text = content
openai.api_key = os.getenv("OPENAI_API_KEY")
response = openai.Embedding.create(
model="text-embedding-ada-002",
input = text.replace("\n"," ")
)
embedding = response['data'][0]['embedding']
return embedding
$$ LANGUAGE PLPYTHON3U;4. Data Loading to Greenplum table
Load original texts into tanzu_documents table, specifically tocontent column, then update embedding column and generate OpenAI embeddings for every content using the previously created get_embeddings Python function :
UPDATE tanzu_documents SET embedding = get_embeddings(content);5. First Semantic Search Query
Let’s build our first semantic search query using pgvector’s cosine distance (using <=> operator) and find the most similar text to our question (i.e., the text with min distance): How to install Greenplum?
WITH cte_question_embedding AS
(
SELECT get_embeddings('How to create an external table in Greenplum using PXF to read from an Oracle database ?')
AS question_embeddings
)
SELECT id, content, embedding <=> cte_question_embedding.question_embeddings AS distance
FROM tanzu_documents, cte_question_embedding
ORDER BY embedding <=> cte_question_embedding.question_embeddings
ASC LIMIT 1 ;
pgvectorintroduces three new operators that can be used to calculate similarity: Euclidean distance (L2 distance)<->, negative inner product<#>and cosine distance<=>
The SELECT statement should return the following output:
id | 640
content | title: Accessing External Data with PXF --- Data managed by your organisation may already reside in external sources such as Hadoop, object stores, and other SQL databases. The Greenplum Platform Extension Framework \(PXF\) provides access to this external data via built-in connectors that map an external data source to a Greenplum Database table definition. PXF is installed with Hadoop and Object Storage connectors. These connectors enable you to read external data stored in text, Avro, JSON, RCFile, Parquet, SequenceFile, and ORC formats. You can use the JDBC connector to access an external SQL database. > **Note** In previous versions of the Greenplum Database, you may have used the `gphdfs` external table protocol to access data stored in Hadoop. Greenplum Database version 6.0.0 removes the `gphdfs` protocol. Use PXF and the `pxf` external table protocol to access Hadoop in Greenplum Database version 6.x. The Greenplum Platform Extension Framework includes a C-language extension and a Java service. After configuring and initialising PXF, you start a single PXF JVM process on each Greenplum Database segment host. This long-running process concurrently serves multiple query requests. For detailed information about the architecture of and using PXF, refer to the [Greenplum Platform Extension Framework \(PXF\)](https://docs.vmware.com/en/VMware-Greenplum-Platform-Extension-Framework/6.6/greenplum-platform-extension-framework/overview_pxf.html) documentation. **Parent topic:** [Working with External Data](../external/g-working-with-file-based-ext-tables.html) **Parent topic:** [Loading and Unloading Data](../load/topics/g-loading-and-unloading-data.html)
distance | 0.120065283545165886. Similarity Search SQL Function:
Since we’re going to perform a similarity search over many embeddings. Let’s create a SQL function for that:
CREATE OR REPLACE FUNCTION match_documents (
query_embedding VECTOR(1536),
match_threshold FLOAT,
match_count INT
)
RETURNS TABLE (
id BIGINT,
content TEXT,
similarity FLOAT
)
AS $$
SELECT
documents.id,
documents.content,
1 - (documents.embedding <=> query_embedding) AS similarity
FROM tanzu_documents documents
WHERE 1 - (documents.embedding <=> query_embedding) > match_threshold
ORDER BY similarity DESC
LIMIT match_count;
$$ LANGUAGE SQL STABLE;We will be using the match_documents function and provide the most similar text to the OpenAI model as the following:
SELECT t.id, t.content, t.similarity
FROM match_documents(
(select get_embeddings('How to create an external table in Greenplum using PXF to read from an Oracle database ?'))
, 0.8
, 1) t
; id | 640
content | title: Accessing External Data with PXF --- Data managed by your organisation may already reside in external sources such as Hadoop, object stores, and other SQL databases. The Greenplum Platform Extension Framework \(PXF\) provides access to this external data via built-in connectors that map an external data source to a Greenplum Database table definition. PXF is installed with Hadoop and Object Storage connectors. These connectors enable you to read external data stored in text, Avro, JSON, RCFile, Parquet, SequenceFile, and ORC formats. You can use the JDBC connector to access an external SQL database. > **Note** In previous versions of the Greenplum Database, you may have used the `gphdfs` external table protocol to access data stored in Hadoop. Greenplum Database version 6.0.0 removes the `gphdfs` protocol. Use PXF and the `pxf` external table protocol to access Hadoop in Greenplum Database version 6.x. The Greenplum Platform Extension Framework includes a C-language extension and a Java service. After configuring and initialising PXF, you start a single PXF JVM process on each Greenplum Database segment host. This long-running process concurrently serves multiple query requests. For detailed information about the architecture of and using PXF, refer to the [Greenplum Platform Extension Framework \(PXF\)](https://docs.vmware.com/en/VMware-Greenplum-Platform-Extension-Framework/6.6/greenplum-platform-extension-framework/overview_pxf.html) documentation. **Parent topic:** [Working with External Data](../external/g-working-with-file-based-ext-tables.html) **Parent topic:** [Loading and Unloading Data](../load/topics/g-loading-and-unloading-data.html)
similarity | 0.87752891733954867. Vectors Indexing:
Our table may grow over time with embeddings, and we will likely want to perform a semantic search across billions of vectors.
What’s excellent about pgvector is its indexing capabilities to speed up queries and enable faster searching.
Vector indexes perform an exact nearest neighbour search (ANN/KNN); they are important to make ordering faster (ORDER BYclause) because vectors are not grouped by similarity, so finding the closest by sequential scan is a slow operation.
Each distance operator requires a different type of index. A good starting number of lists is rows / 1000 for up to 1M rows and sqrt(rows) for over 1M. Since we order by cosine distance, then we will usevector_cosine_ops index.
-- Create a Vector Index
CREATE INDEX ON tanzu_documents
USING ivfflat (embedding vector_cosine_ops)
WITH
(lists = 300);
-- Analyze table
ANALYZE tanzu_documents;Read more about pgvector indexing here: https://github.com/pgvector/pgvector#indexing
8. Provide an OpenAI model with the right dataset for a relevant answer
Build a PL/Python function that takes as input both: the user’s input and the most similar text to it then asks the OpenAI model to answer:
CREATE FUNCTION ask_openai(user_input text, document text)
RETURNS TEXT
AS
$$
import openai
import os
openai.api_key = os.getenv("OPENAI_API_KEY")
search_string = user_input
docs_text = document
messages = [{"role": "system",
"content": "You concisely answer questions based on text provided to you."}]
prompt = """Answer the user's prompt or question:
{search_string}
by summarising the following text:
{docs_text}
Keep your answer direct and concise. Provide code snippets where applicable.
The question is about a Greenplum / PostgreSQL database. You can enrich the answer with other
Greenplum or PostgreSQL-relevant details if applicable.""".format(search_string=search_string, docs_text=docs_text)
messages.append({"role": "user", "content": prompt})
response = openai.ChatCompletion.create(model="gpt-3.5-turbo", messages=messages)
return response.choices[0]["message"]["content"]
$$ LANGUAGE PLPYTHON3U;9. Building a smarter search function
As we mentioned before, ChatGPT doesn’t just return existing documents. It’s able to assimilate various information into a single, cohesive answer. To do this, we need to provide GPT with some relevant documents and a prompt that it can use to formulate this answer.
As a final step, we should combine previous functions into a single process to serve our Intelligent AI-Assitant application.
Our previous functions and Embeddings can help solve this by splitting prompts into a two-phased process:
- Query our embedding database for the most relevant documents related to the question.
- Inject these documents as context for the OpenAI model to reference in its answer.
CREATE OR REPLACE FUNCTION intelligent_ai_assistant(
user_input TEXT
)
RETURNS TABLE (
content TEXT
)
LANGUAGE SQL STABLE
AS $$
SELECT
ask_openai(user_input,
(SELECT t.content
FROM match_documents(
(SELECT get_embeddings(user_input)) ,
0.8,
1) t
)
);
$$;The SQL function above takes user input, converts it to embeddings, performs a semantic text search using pgvectoron tanzu_documents table to find the most relevant documentation, and lastly feeds it as a reference text to OpenAI API call, which returns the final answer.
10. Build our own Chatbot 🤖 empowered with Semantic Text Search capability using OpenAI and Streamlit 🎈
Finally, we’ve developed a Streamlit 🎈 Chatbot 🤖 that understands our documents and uses the Greenplum data warehouse with pgvector semantic text search.
This Chatbot Streamlit application is available here: https://greenplum-pgvector-chatbot.streamlit.app/
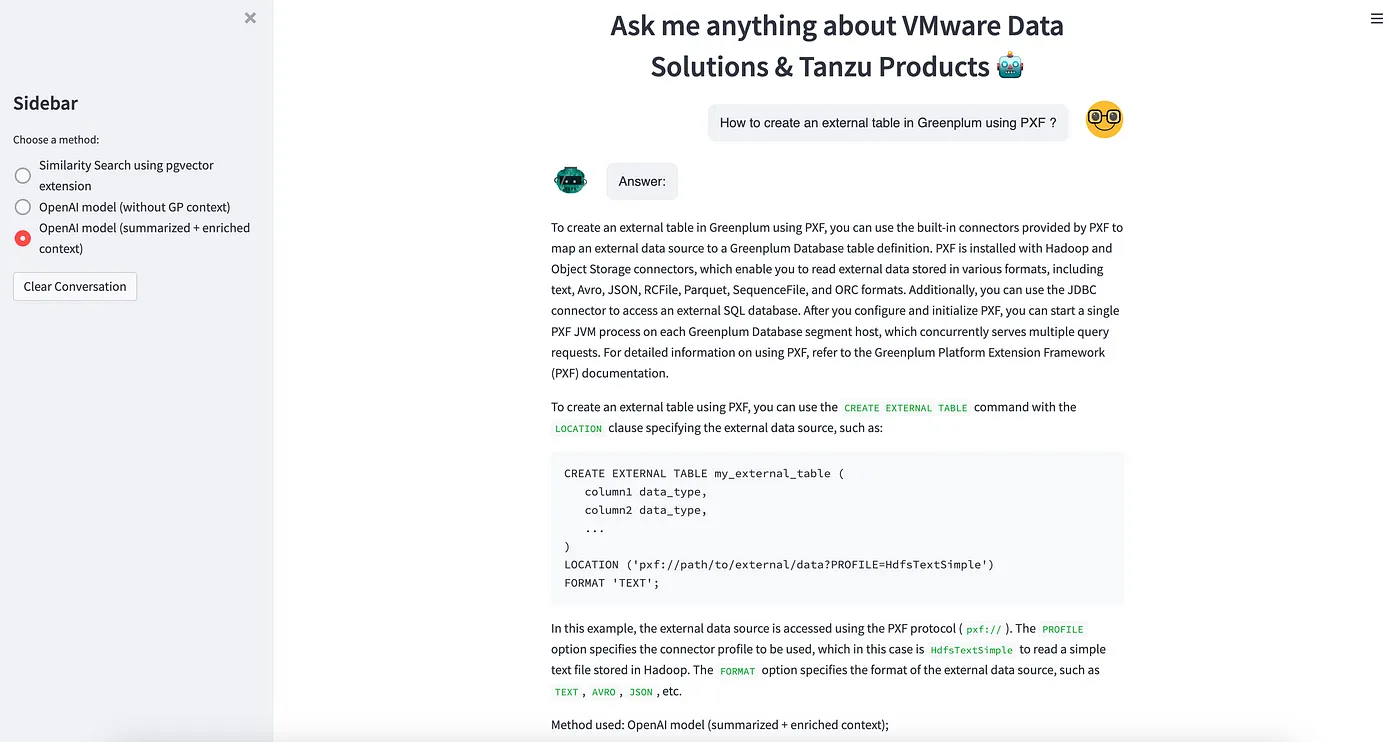
You can find the source code here: https://github.com/ahmedrachid/streamlit-chatbot-greenplum
🚀 Conclusion
To conclude, companies wishing to build scalable AI applications can unleash Greenplum performance and massively parallel processing capabilities, combine it with the pgvectorto process, and perform fast retrieval, similarity and semantic search over massive amounts of vector embeddings and unstructured data.
📝 References :
- Open-source Greenplum data warehouse: https://greenplum.org/
- VMware Greenplum data warehouse: https://docs.vmware.com/en/VMware-Tanzu-Greenplum/index.html
- pgvector extension - Open-source vector similarity search for Postgres: https://github.com/pgvector/pgvector
Thanks for reading! Any comments or suggestions are welcome! Check out other Greenplum articles here.
