10 Methods of Inclusive Machine Learning

Let’s start with a hypothetical:
Recruiters at a company examine thousands of resumes for a single job. The company implements a machine learning algorithm that ranks candidates’ resumes based on current employee’s resumes.
What’s wrong with this situation? Flashing forward 1 year…
The company saved money and time by implementing this ‘stellar’ recruiting algorithm. However, one day, a data scientist reviews the model in complete shock. The model penalized candidates for being in the Women’s Chess Club, Mount Holyoke College, and Smith College. It was unapologetically sexist.
This is not actually a hypothetical. This happens and continues to happen, every day in the workforce.
What went wrong?

The sad fact is, it may be difficult to detect a discriminatory model. Machine learning is one of the most useful tools of the 21st century. However, it can also be one of the most dangerous.
What is Inclusive Machine Learning?
Inclusive machine learning involves the concept of fairness. Defined by Google, fairness in machine learning aims to:
“prevent unjust or prejudicial treatment of people related to race, income, sexual orientation, religion, gender, and other characteristics historically associated with discrimination and marginalization, when and where they manifest in algorithmic systems or algorithmically aided decision-making.”
Machine learning is more popular than ever. It is our job to make machine learning work for good, not for evil. Ready to join the fairness bandwagon?
1. Know the limitations of your data
Yay data! Without it, there would be no data science. Yet, data may not always be as great as it seems. Imagine you’re given a labeled dataset from upper-level management. Your task is to make sense of the data and create a model that predicts a target variable.
Before you begin with machine learning, answer these questions:
How were the data collected?
Inequalities and biases may already be present in your data merely by how it was collected. What population was the data sampled from? How was the data labeled? If the data collection method isn’t clear, big red flag.
Who/what are excluded in your data?
In the resume example above, the classifier was trained on resume data. What is the harm in that? If a company historically hired white, affluent, young, straight men, the resume dataset will reflect that population. Models are limited to the fairness of their data. In this case, machine learning will tell the company to hire more white, affluent, young, straight men, and exclude the rest.
Are there proxy variables?
Proxies are variables in your feature set that may represent other (often, problematic) variables. One example of a common proxy variable is Zip Code. In many predictive policing efforts, Zip Codes are features in a machine learning model used to determine where law enforcement officers should focus their time. However, Zip Codes can be a proxy for race in the United States (see below), as well as income, health, religion, and many more factors. The best way to combat proxy variables is to identify proxies and leave them out of your feature set.


Bottom line: GIGO. Garbage in Garbage out.

2. Understand your Target Variable
Many datasets initially lack labels or target variables. Oftentimes, the data scientist must either choose which label to predict, create a new label, or perform unsupervised machine learning.
Here are some questions to start evaluating your model’s target variable:
What does your target variable really mean?
Let’s say your target variable is a predictive measure for how successful a job applicant will be. What does it mean to be successful? Will success be measured by income, job performance, or role? What is a characteristic of success that cannot be measured numerically? Is your label objective? Bottom line: Know your target variable’s assumptions and limitations. Keep track of those decisions throughout the machine learning process.
Are there implicit biases within your target variable?
Continuing the predictive measure above, let’s say income is selected as a measure of employee success. While at first, this may seem reasonable, problems will arise because there are confounding variables that impact income (such as race and gender). These biases will now be built into your model. GIGO applies here more than ever.

Always, always, always check your target variables and features for inherent biases and proxies
Are your labels imbalanced?
I once created a machine learning model that performed at 95% accuracy. Amazing! Or so I thought… Digging deeper I found out that one of the labels was being misclassified 100% of the time. How is that possible? One of the labels made up only 5% of the data. Good news is there are some methods for dealing with imbalanced labels. There are methods of evaluating your model to detect this problem, but, more on that later.
3. Ditch the “black box” Approach
Are neural networks the holy grail of data science?

Although neural networks tend to perform very well, many don’t realize…
When to use neural networks:
- Highly dimensional data
- Individual features are not as significant (pixels in an image)
- Explainability of the model not as important
When not to use neural networks:
- There is a simpler model with the same outcome
KISS & Modeling
Always consider the concept of Occam’s razor when modeling. For many models, there is a simpler approach than a black box model that achieves acceptable results. Occam’s razor is a concept that states that when comparing two solutions, the simpler solution is usually superior.

Thus, by selecting a simple yet effective model, data scientists can combat common modeling problems such as the curse of dimensionality and overfitting.
4. Interpret and Explain your model
Another major focus in modern data science is model explainability and interpretability. Kaggle describes explainability as: “ Extract[ing] human understandable insights from any Machine learning model.” This may seem like common sense, yet many data scientists struggle to describe, understand, and validate how and why models achieve results.
In the resume example above, implementing an explainable resume model would have saved the company from deploying the unfair model.

Model explainability and interpretability is a very exciting and vast topic in machine learning. Here are some resources to explore!
- A free 4-hour course on Kaggle
- An overview on KDnuggets
- An online book with examples
- An SDK on Microsoft Azure
- An overview of Shapely Values
5. Perform cross-validation
This tip is more for general good practice and less specific to inclusive machine learning. However, cross-validation is crucial to improve the generalizability of your model. For your model to be fair, it should also be good. Always try to reduce the negative effects of overfitting by performing cross validation.
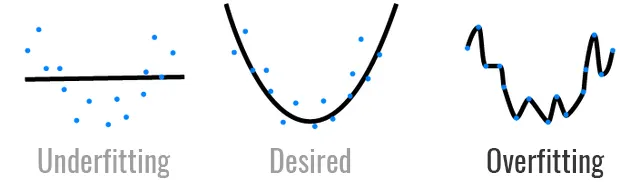
6. Realize accuracy isn’t everything
A classification model can achieve 95% accuracy and misclassify one label 100% of the time (see ‘Are your labels imbalanced?’ above).
Many evaluation metrics produce a more robust understanding of model performance than accuracy. These metrics can also be used as the optimization method of your model.
The main downside of accuracy is that it does differentiate between True Positives (TP), False Positives (FP), True Negatives (TN), and False Negatives (FN). However, metrics like precision (sensitivity), recall, f1 score, AUC, and specificity all provide additional insight into your model performance. Ideally, all metrics would be calculated and evaluated to understand model performance.

Furthermore, this article does a great job at summarizing which metrics to optimize on in your machine learning project.
Not doing classification? Here is a great article on selecting the right evaluation metric for a regression model.
7. Acknowledge your biases
Everyone has biases. There is no way around it. Many of the machine learning decisions made are impacted by implicit biases that may be difficult to detect.
Below is my favorite summary of 20 common biases one might have:

What are some methods of mitigating biases?
- Have a diverse data science team
- Reference the above list
- Discuss potential biases with your team
In many cases, self-awareness is the first step.
8. Include a human in the loop
I hope by now it’s clear what can go wrong with a machine learning model.

The reality is, machine learning still cannot simulate human thought. Therefore, it is crucial that any process regarding an important decision, especially about people or any decision that may produce ethical concerns, should include a human in the loop.
9. Monitor your model
When a model is deployed, it can become unstable and shift. Machine learning model uses training data to predict new data. However, if the underlying characteristics of these data change (e.g. a recession impacts all financial features in a model), the machine learning model must be re-evaluated.
One popular method of monitoring model performance is A/B testing.

10. Accept sometimes, ML is not the answer (as amazing as it is!)
It breaks my heart to say this. Machine learning one of the most ground-breaking tools of the 20th and 21st century. However, one may realize in machine learning process, either the dataset, or the use case suggests that machine learning is not the best tool to use.
In this case, there are many other approaches to investigate, such as data visualization, traditional statistical methods, simulation, and operations research.
Remember how dangerous unfair models can be. It is our responsibility as data scientists to detect unfairness and act on it, before it’s too late.

