Introducing Hashmap Data Migrator
Open Source Tooling to Move Your Data Warehouse to the Cloud
by John Aven and Jhimli Bora

Choosing the right tools can be difficult when planning to move data to the cloud or any migration of a large data asset or assets. Additionally, the tools chosen to transport data in your new system may not support your current data systems — especially in the capacity of a migration. The Hashmap team has built an open-source tool aimed to fill that temporary gap.
About
Hashmap Data Migrator, or hdm (yes — lowercase), is an open-source software from Hashmap. It is Apache 2.0 licensed. hdm’s goal is to assist in moving data from your on-premises data warehouse (Netezza, Exadata, SAP HANA, Teradata, Hadoop, Oracle, etc.) into your cloud data warehouse of choice (Snowflake, BigQuery, Synapse, RedShift, etc.) — some functionality is still in development.
This library has been built and re-built a few times with the intent of getting the feel just right. Early versions of the library went by the name of knerrir — and the internal parts of the library had nautical themes (knerrir is a fleet of Viking cargo ships). Ultimately, the mix of library components having odd names and an evolving design didn’t mesh too well. After many internal simplifications and rewrites, the library’s name was rebranded — the name didn’t feel right anymore.
hdm is designed to work out of the box for most data transport use cases. It can be extended to your needs for a personalized fit when you have specific compliance requirements (e.g., a new link in the pipeline to do particular tests/checks against the data.). Such customization isn’t generally feasible in a migration setting with off-the-shelf tooling. Furthermore, the software’s design is such that the migrator’s runtime can be distributively deployed across different machines, partially on-premises, partially in the cloud, and various other combinations as long as there is a shared database to maintain the state and lineage.
Architecture
The design of hdm focuses on the following qualities:
- Composability — Different environments have different needs, so combine what is needed to move data from A to B.
- Configurability —Connections, watermarks, stage names, and so on are all environment and business decision based and may be determined to some extent by target infrastructure and runtime environment.
- Stateful — The state of the data and a running pipeline is known at all times and can be restarted/continued from where it last left off.
- Deployable — The solution can be decomposed and deployed.
- Auditable — The state of the system maintains an audit trail of all data movement.
- Distributable — While some steps will need common access to storage layers, it can be deployed in disparate locations.
- Resilience — The system does not fail when errors are observed (a few exceptions are being worked on still).
In terms of the software is built on SOLID design principles and various design patterns:
- Inversion of Control — A Dynamic Service Locator with Dependency Injection is used in the form of the library providah.
- Template — The interfaces are not really interfaces, but templated base classes that define an API and implement baseline functionality. This functionality is overridden as necessary.
- Scheduler — Code is executed on threads in the batch orchestration. For each thread, the state can update and cause a recursive call until done.
- Mediator — This is used to get and set the state of the processing pipelines at various stages.
The software is made up of 5 main components:
- State Management — software & database.
- Configurations — data transport pipeline & data system access.
- Catalog — responsible for identifying all data assets to migrate and creating the necessary entities in the target system.
- Orchestration — engine which supports various modes of pipeline execution.
- DataLinks — pairs of source/sink specifications. A chain of DataLinks makes up a data transport pipeline.
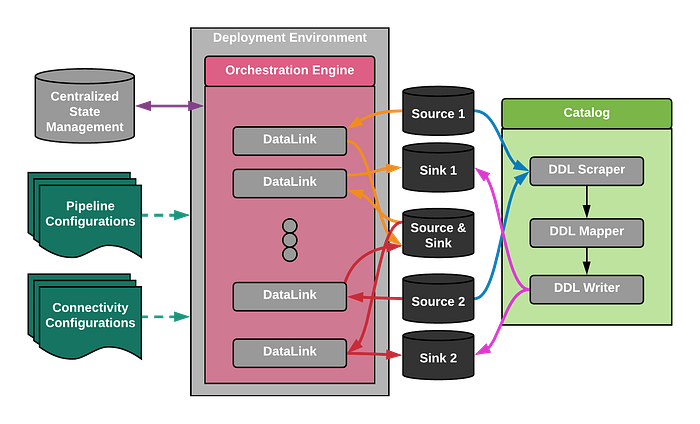
In this diagram:
- Blue arrows represent the scraping of DDL from source data systems.
- Black arrows are the process flow for catalog generation.
- Magenta arrows are the DDL-based asset generation in the sink systems based upon source systems.
- The yellow and red arrows represent two separate data movement pipelines.
- Green arrows are the input configurations.
- The bi-directional purple arrow represents the synchronization of state and lineage of data transfer.

In addition to these classes, there are a few driver classes that are not represented. The bulk of any extension to this library will happen with the above-named interfaces. For clarity, all diamond arrows indicate that the parent's lifecycle constrains the child's life-cycle.
Source & Sinks
Sources and sinks are abstractions of data assets & actions. Data assets are Netezza databases, file systems, object stores (S3, Azure Data Lake Services, etc.), cloud data warehouses — like Snowflake, and so on. The actions are abstractions describing how connections are established (JDBC/ODBC, SFTP, etc.) with the source or sink, how data is moved in or out, and how data is partitioned (e.g., splitting of large files into smaller ones). To keep things simple, the object model is designed so that each such combination is given a specialization (in the object-oriented sense) — thus minimizing the complexity around the composition. While this produces many more classes that would need to be managed through a ‘factory.’ We use providah to remove the need to build and maintain various factory classes.
Orchestration
Managing multiple pipelines can be complex. While we have plans to implement additional orchestration options soon, we have two main orchestration options:
- DeclaredOrchestrator — Each data pipeline is fully specified and executes as a stand-alone pipeline. There is no reuse of individual components.
- BatchOrchestrator — In this orchestration, a specific portion of a ‘root’ source configuration is specified (e.g., a Table & Watermark column for a database source) as a list of targets. The remainder of the pipeline is reusable and will be shared for all originating sources in the template.
We are currently working on an additional orchestration option, AutoBatchOrchestrator. In the option, orchestration will integrate the cataloging capabilities to enhance batch extraction to adapt to data asset changes.
Configuring a Pipeline
Pipelines are configured through a YAML-based configuration.
Pipelines are defined declaratively in YAML files. These YAML files identify:
- orchestrator: (internal hdm concept) used to orchestrate your pipeline's execution.
It is formatted in the YAML as depicted below:
orchestrator:
name: Manual Orchestration
type: declared_orchestrator
conf: null- state_manager: Next the State Manager is specified. This should be consistent across all of the pipelines. The State Manager is the glue the couples the otherwise independent portions of the pipeline together.
It is formatted in the YAML as depicted below:
state_manager:
name: state_manager
type: SQLiteStateManager
conf:
connection: state_managerNext is the portion of the YAML that specifies the different steps in the data movement. These will be specified in two separate sections.
- declared_data_links — These are fully specified portions of a pipeline. In this, each pair of source & sink is called a stage. See the example below that is targeted at offloading data from Netezza and storing it on a filesystem.
declared_data_links:
stages:
- source:
name: Netezza Source Connection
type: NetezzaSource
conf:
...
sink:
name: File System Sink Connection
type: FSSink
conf:
...- template_data_links — These are partially defined source/sink pairs. Instead of being called stages, they are called templates. A template has an additional field called a batch_definition. A batch definition will define how the template source is used — the source is ALWAYS the template. See an example below for creating a pipeline that is pulling multiple tables at once. A similar example would be found for auto batch orchestration.
template_data_links:
templates:
- batch_definition:
- source_name: netezza_source
field: table_name
values:
- database.schema.table_1
- database.schema.table_1
threads: 5
source:
name: netezza_source
type: NetezzaSource
conf:
...
table_name: <<template>>
sink:
name: fs_chunk_stg
type: FSSink
conf:
...Using hdm
While hdm appears to have many moving parts, it is quite simple to use. This will be covered in the next blog post of the series.
For out-of-the-box functionality, you must:
- Create a .hashmap_data_migrator directory in your user ‘root’.
- Create a hdm_profiles.yml to store local secrets for connections (integrations with key management systems like Hashicorp Vault and Azure KeyVault don’t come out of the box at this time).
- A manifest.yml (name it what you want) with a pipeline configuration.
If you wish to extend the library's functionality, you must either extend/implement an interface (see UML above) or a child class thereof. How and where (folder-wise) you organize these extensions is up to you. Thanks to the providah library, you will only need to make sure that your class definitions are scraped.
python -m hashmap_data_migrator {manifest} -l {log settings} -e {env}Where {manifest} is the manifest.yml file, {log settings} is a log configuration file, and {env} is an indicator of the environment in the hdm_profiles.yml that will be used to execute the pipeline.
Watch a demo of hdm in this Hashmap Megabyte video:
What’s to Come
- Source Support for Hadoop, Exadata, etc. (Netezza is supported now)
- Sink Support for Synapse, Redshift, BigQuery (Snowflake is supported now)
- Data Quality Integration to automate data validation at all ends
- Cloud-Native & Dockerized Deployments
- Fit-for-purpose packaging. We will be providing packaging designed around your specific migration needs. Specialized libraries that don’t have all the unnecessary dependencies — only what you need.
Resources
Gitlab Mirror: https://gitlab.com/hashmapinc/oss/hashmap-data-migrator
Github Mirror: https://github.com/hashmapinc/hdm
PyPI: https://pypi.org/project/hashmap-data-migrator
Ready to Accelerate Your Digital Transformation?
If you are considering moving data and analytics products and applications to the cloud or if you would like help and guidance and a few best practices in delivering higher value outcomes in your existing cloud program, then please contact us.
Hashmap offers a range of enablement workshops and assessment services, cloud modernization and migration services, and consulting service packages as part of our Cloud service offerings. We would be glad to work through your specific requirements.
Hashmap’s Data & Cloud Migration and Modernization Workshop is an interactive, two-hour experience for you and your team to help understand how to accelerate desired outcomes, reduce risk, and enable modern data readiness. We’ll talk through options and make sure that everyone has a good understanding of what should be prioritized, typical project phases, and how to mitigate risk. Sign up today for our complimentary workshop.
Other Tools and Content You Might Like
Behind the Scenes of Snowflake Healthcheck
Understanding Hashmap’s Latest Snowflake Utility
medium.com
Feel free to share on other channels and be sure and keep up with all new content from Hashmap here. To listen in on a casual conversation about all things data engineering and the cloud, check out Hashmap’s podcast Hashmap on Tap as well on Spotify, Apple, Google, and other popular streaming apps.
John Aven, Ph.D., is the Director of Engineering at Hashmap, an NTT DATA Company, providing Data, Cloud, IoT, and AI/ML solutions and consulting expertise across industries with a group of innovative technologists and domain experts accelerating high-value business outcomes for our customers. Be sure and connect with John on LinkedIn and reach out for more perspectives and insight into accelerating your data-driven business outcomes.
Jhimli Bora is a Cloud and Data Engineer with Hashmap, an NTT DATA Company, providing Data, Cloud, IoT, and AI/ML solutions and consulting expertise across industries with a group of innovative technologists and domain experts accelerating high-value business outcomes for our customers. Connect with her on LinkedIn.

