Classification of Histopathology Images with Deep Learning: A Practical Guide
Everything you need to know to train your own classifier on histopathology images.

Automated classification of high-resolution histopathology slides is one of the most popular yet challenging problems in medical image analysis. The development of deep learning has allowed for accurate classification of lung cancer, breast cancer, brain tumors, colorectal polyps, esophageal cancer, celiac disease, and so much more. How exactly do these algorithms work, and how do you build one?
For a quick implementation, see the DeepSlide Github repository, which has been optimized for histopathology image analysis:
Deep Learning & Convolutional Neural Nets
Recently, deep learning has produced a set of image analysis techniques that automatically extract relevant features, transforming the field of computer vision. Convolutional neural networks (CNNs) use a data-driven approach to automatically learn feature representations for images, achieving super-human performance on benchmark image classification datasets such as ImageNet. CNNs are the current state-of-the-art architecture for medical image analysis. More info on deep learning and CNNs: [deep learning book] [coursera].
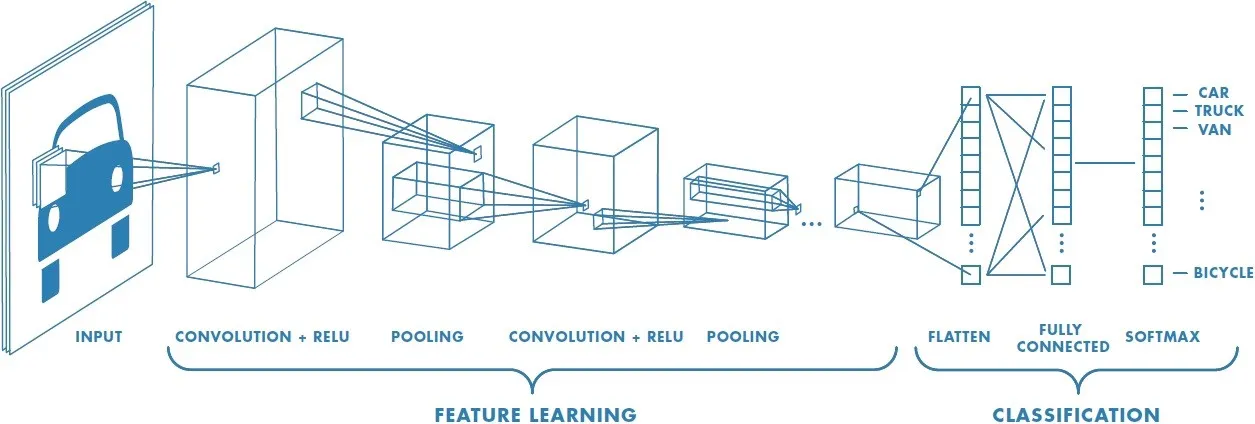
Challenges
Because of the nature of histopathology images, there are two main challenges:
- The images in benchmark datasets that CNNs do well on are low resolution (something like 224x224 pixels). Histopathology images, on the other hand, are for pathologists to examine under the microscope, so they tend to be extremely high resolution (sometimes 100,000x100,000 pixels and 10GB+). We can’t train directly on whole-slide images since their resolution is too high.
- Benchmark datasets have hundreds of thousands of images for training. In histopathology slide analysis we don’t have that many images, and we can’t just collect more data by downloading images from the internet. So we have to figure out a way to train a generalizable network without overfitting on the training set.
Sliding Window Approach
The sliding window approach is the simplest (and currently standard) way of dealing with both of these issues. The idea is the following:
At training time, we slide a 224x224 window across the entire whole-slide image to generate small patches. We label these patches with the original label of the whole-slide image (or bounding box labels if you have them), and train a CNN to classify patches.
By generating patches, you now have manageable-sized inputs for training a CNN. At the same time, this helps prevent overfitting because you’ve generated many unique patches from each whole-slide image.
You’ve now solved both main challenges!
Whole-Slide Inference
You can predict the labels of small patches, but ultimately you will need a way of aggregating these patch predictions to predict a label at the whole-slide level.

There are multiple ways of aggregating patch predictions. Here they are, in order from complexity:
- Majority voting. Take the most frequently predicted class.
- Patch averages. Average the probabilities of all patch predictions, and take the class with the highest probability.
- Thresholding. Throw away predictions of low confidence. Then, only predict certain whole-slide labels if the number of patch predictions hit some other threshold. Otherwise, predict normal. This is ideal for when you have normal slides mixed in, and if you have multi-label slides.
- Machine learning. Feed your patch predictions into some machine learning model like support vector machines, random forest, or logistic regression. Only try this approach if you have >1,000 whole-slide images for training, otherwise you may have problems with overfitting.
- Attention-Based Classification. Train an end-to-end model to take in a whole-slide image and slide some feature extractor with an attention module to identify the most important patches. This approach is the most complex but also the most scalable, plus it works without bounding box annotations in some cases where you would have otherwise need them. Read more in [this paper].
Evaluation
Congratulations! You’ve now trained a model for classification of whole-slide histopathology images. Time for evaluation on the testing set. Calculate metrics such as accuracy, precision, recall, and F1 score per class. You can also plot receiver operating characteristic (ROC) curves and calculate area under the curve (AUC). Do you have pathologist’s annotations in addition to ground truth labels? Compare your model’s performance to that of pathologists.
Visualization of your model’s predictions can be a good way to confirm your model’s predictions and also help debug your model to improve performance. You can try both a whole-slide level visualization of patches as well as CAM or LIME for patch-level visualizations.

My code, which has been optimized for histopathology image classification, is easy to use and can be found here:
Frequently Asked Questions
- I have data but I’ve never coded a neural network from scratch. How do I start? Great question! You can pull my PyTorch code from Github, which is optimized for histopathology image classification, and use it as a baseline. Then, work on patch aggregation methods or your own custom implementation.
- How deep should my neural network be? I encourage you to try something deeper than AlexNet and VGG like ResNet or InceptionNet. Deeper networks have achieved higher accuracies on the 1000 classes for ImageNet, but since histopathology images are mostly purple and look pretty similar, you probably don’t need that many learnable parameters. ResNet-18 has worked pretty well for most of the tasks that I’ve worked on.
- How many whole-slide images do I need? Obviously more is better, but I think if you have something like 10–20 whole-slide images per class with a decent area of classifiable tissue, you can get decent accuracy after extracting patches and doing data augmentation.
- What resolution should my images be? I would recommend something in the range of (the lowest resolution that is still readable) to (twice that resolution). ~5MB per whole-slide image has worked pretty well for me. If your resolution is too high, you’ll be dealing with hefty computation times and memory issues, and patches may not be classifiable if they are too zoomed in. On the converse, if your resolution is too low, then the images aren’t readable.
- How do I deal with class imbalances? If you’re using my code, patches from less frequent classes are extracted with a lower stride and then automatically duplicated to create perfectly balanced classes. Another solution would be to write a custom loss function that has a higher penalty for less frequent classes.
- Do I need bounding box annotations from pathologists? It depends on the homogeneity of your classification problem. For example, in celiac disease detection, any given patch of a whole-slide image can be classified as having celiac disease, so you would not need bounding annotations. In this case you would not need bounding box annotations. On the other hand, in lung cancer classification, each image has multiple classes as well as normal tissue, so any given patch is not that likely to have the same label as its whole-slide image. You would need bounding boxes in this case. I would suggest trying it without bounding boxes first, and if the results are poor then go back and find a way to get bounding boxes.
- What should I do with all the white space on the whole-slide image? Please do not train on white space. You can write a simple image processing function to filter out these images, or just take the one I have written [here] for H&E stained slides (purple images).
Want more?
- If you haven’t yet, try out the DeepSlide Github repository. Feel free to post in the “issues” section and someone will get back to you.
- Read my paper on pathologist-level lung cancer classification.
- Dr. Saeed Hassanpour from Dartmouth College does incredible work in image classification for both histopathology and radiology images.
- My personal website is below. Feel free to reach out by email :)
Thank you to my supervisor, Saeed Hassanpour, for advising me on the content and methodology in this guide.