Unveiling the Power, Challenges, and Impact of Large Language Models
In this blog post, we explore the progress and potential impact of Large Language Models (LLMs). These technologies have come a long way, expanding from basic models to offer a wide range of benefits and possibilities. However, it’s essential to consider their limitations and the challenges they must overcome. Additionally, we should reflect on whether they may pave the way for the development of LLM in the future:
Key Takeaways:
- LLM and Foundation Models: Large-scale pre-trained AI models, or Foundation Models (FMs), serve as a foundational base for a wide variety of applications and tasks. They have shown immense potential, but it is essential to remain aware of the equity, fairness, and ethical issues they may present.
- The development of Artificial General Intelligence (AGI), which mirrors human intelligence, is seen as the goal of AI research. LLMs such as GPT-4 are a significant step towards this, but there are still limitations to be addressed.
- The widespread adoption of LLMs needs to be balanced with addressing potential risks to society and humanity. In this section, we’ll highlight the important points.
- Decoder-only LLMs architectures are increasingly taking over the field due to their flexibility and versatility. However, this may create barriers for institutions lacking the necessary computational infrastructure.
- The closed-source nature of some LLMs has caused varying reactions and concerns in terms of social impact, with some calling for a pause in AI development and others advocating for responsible, secure AI.
- Data is becoming a significant constraint for optimal LLM performance, necessitating innovative approaches to balance model size and training tokens. By exploring self-generation, automation, and integration with external APIs, we can overcome data constraints to improve LLM effectiveness and versatility.
Large Language Models & Foundation Models: pioneering Artificial General Intelligence
LLMs, and other models, have been categorized as Foundation Models (FMs) FMs are defined as large-scale pre-trained AI models based on transfer learning and deep learning advances, which are trained on broad data for adaptation to various downstream tasks. The term was coined because these models serve as a foundational base for a wide variety of applications and tasks. FMs, such as ChatGPT and Bard, are powerful and versatile tools that are increasingly being used in the business world, with surprising improvements in Microsoft 365 Copilot or Google Workspace. Trained on vast amounts of data, they can adapt to a wide range of different tasks. While the technology behind them is not new, their scale and scope have challenged our imagination about what is possible.
However, it is vital to remain aware of the inequity and fairness issues in these models, as well as the ethical, political, and social concerns regarding the scaling characteristics of FMs for various applications and the concentration of power in organizations with better resources to produce competitive FMs.
The history of AI has been one of constant emergence and homogenization in the construction of machine learning systems for different applications, and FMs are the latest manifestation of this trend. As we continue to push the limits of what these models can do, it’s crucial to ensure that they remain reliable and trustworthy.

Figure 1. AI Evolution: Always increasing emergence and homogenization. (Source: https://arxiv.org/pdf/2108.07258.pdf)
These FMs possess a highly significant attribute — their generative nature, which is rooted in state-of-the-art Generative Artificial Intelligence (GAI) models. GAI encompasses AI models that specialize in converting basic input data into realistic representations that closely resemble real-world information. GAI enables the creation of highly realistic synthetic data using straightforward inputs like random vectors or textual information. Hence, FMs have the capability to generate unique content using a provided prompt as input. Moreover, these FMs are primarily multimodal, enabling them to generate various types of content such as textual content works (such as ChatGPT), images (as with DALL-E 2), and audio (e.g., MusicLM).
Towards Artificial General Intelligence (GAI)
Artificial General Intelligence (AGI) is the term used for an AI that mirrors human intelligence, with the ability to understand, learn, and apply knowledge in a vast array of fields. AGIs are for many the holy grail of AI development that solves the limitations of contemporary foundational models. An AGI’s adaptability to novel situations and problem-solving prowess across multiple domains would negate the need for specialised training that current models require, and which can come at a significant cost to companies developing such models, with the training of GPT-3 being estimated at $4.6m. The expansive capabilities of OpenAI’s latest offering, GPT-4, are very impressive and arguably a large step towards the development of an AGI.
However, it’s not there yet and there are several limitations that need to be overcome, such as the model’s reasoning capabilities. For instance, ChatGPT may produce incorrect or nonsensical responses that seem plausible, like speaking nonsense in a serious manner. The model can be illogical as it does not possess a comprehensive “world model” and may have difficulty with spatial, temporal, or physical inferences, as well as predicting and explaining human behaviour and mental processes.
ChatGPT also exhibits limitations in math and arithmetic, struggling with complex problems and occasionally providing inaccurate results for straightforward calculations. Additionally, its high sensitivity to input prompts can lead to inconsistencies, generating varying responses even when presented with identical input. These limitations are mentioned in some recent research.
New challenges of Large Language Models on the horizon
The emerging trends of Large Language Models
The Landscape of LLM architectures has undergone a significant change since the release of the first transformer model. There are three important branches of LLM architectures: encoder-only, encoder-decoder (the original structure), and decoder-only. The decoder-only models are progressively taking over the field. Initially, encoder-only and encoder-decoder models outperformed decoder-only models, but the introduction of GPT-3 changed things.
It marked a turning point for decoder-only models, while encoder-only models like BERT started losing traction. Although encoder-decoder models remain promising due to active exploration and open-sourcing efforts by companies like Google and have given rise to Masked Language Models such as BERT, RoBERTa, and T5, which excel in various NLP tasks. However, these models often require fine-tuning for specific downstream tasks. In contrast, the flexibility and versatility of decoder-only models make them increasingly attractive.
Scaled-up Autoregressive Language Models like GPT-3, OPT, PaLM, and BLOOM have demonstrated remarkable few-shot and zero-shot performance, establishing the superiority of this approach and pointing to a promising future for LLM architectures. A recent study presents the evolutionary trajectory of contemporary LLMs, delineating the progression of language model development in recent times and emphasizing some of the most renowned models in the field.
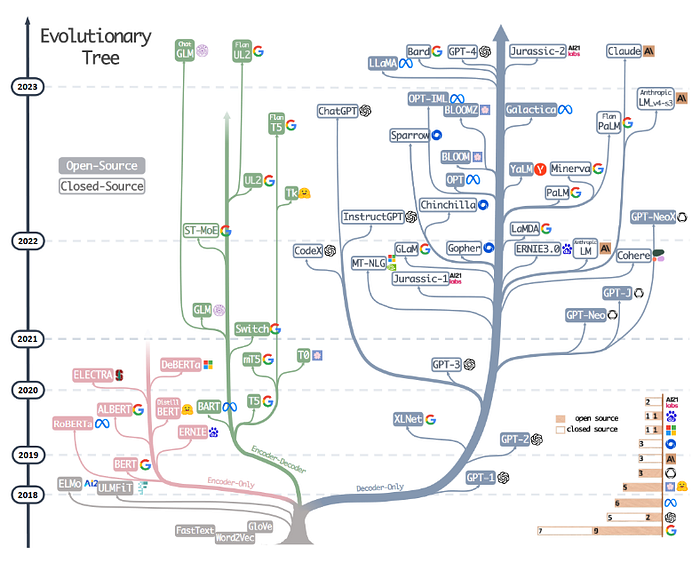
Figure 2. Evolutionary trajectory of contemporary LLMs (source: https://arxiv.org/pdf/2304.13712.pdf)
Figure 2 displays the close relationships among the different architectures, with the vertical placement on the timeline corresponding to their release dates. Solid and hollow squares represent open-source and closed-source models, respectively.
The social impact on the growth of Large Language Models
The widespread adoption of these ground-breaking models presents immense possibilities and significant potential risks, and society has already had varying reactions to their use. For instance, the open/closed-source approaches taken in the development and distribution of the source code for these models.
Overall, open-source refers to freely available source code for anyone to use, modify, and distribute, while closed-source pertains to proprietary code not available for modification or distribution outside the organization that created it. Before GPT-3, most large language models were open-sourced, but currently, companies have increasingly made their models closed-sourced, e.g. PaLM, LaMDA, and GPT-4. For instance, OpenAI imposes limitations on technical details due to the competitive landscape and security implications of these models, making it harder for academic researchers to conduct LLM training experiments.
Some prominent figures in AI are calling for a global pause in the development of more powerful AI systems than GPT-4 to address significant risks to society and humanity, with Italy even temporarily banning the use of ChatGPT due to privacy concerns, a move that could spread to other countries. Other experts emphasize the need to not hinder technological progress, and instead, invest in responsible and secure AI as the technology advances.
Tackling challenges and data efficiency
The scientific community has been striving to continually push the boundaries of these models, creating increasingly larger LLMs such as PaLM (540-billion parameters) and Megatron-Turing (530-billion parameters), models with an extraordinary number of parameters. However, this has created a barrier for many institutions that lack the necessary computational infrastructure to study these models.
Fortunately, initiatives like BLOOM, LLAMA, and ALPACA are working towards democratizing these technologies by sharing code and models. While the trend towards larger LLMs continues, it’s important to note that bigger doesn’t always mean better. Deepmind has explored the uncertainty in guidelines for efficiently scaling LLMs in terms of parameters and resources, and their findings suggest that current LLMs are considerably oversized. To achieve compute-optimal training, the model size and the number of training tokens should be increased in approximately equal proportions.

Table 1. Estimated configuration for compute-optimal training (source: https://arxiv.org/pdf/2203.15556.pdf)
Data, the new constraint
While current computational resources can meet the demands, data is becoming a significant constraint for optimal language model performance in machine learning. A study about limits of scaling datasets in ML indicates that the stocks of language data available on the Internet will be exhausted in the coming years. As data exhaustion looms and the trend towards scaling model size continues without increasing the amount of training data, it’s clear that innovative approaches are needed to rethink the balance between model size and training tokens. These approaches are crucial for ensuring sustainable progress in the field of natural language processing.
Breaking limitations
Innovative approaches are currently addressing the limitations of current language models, providing alternative solutions to data constraints. These investigations explore self-generation of problems and solutions, automation of rational chains in the Chain-of-Thought (CoT) approach, and integration with external APIs. This allows language models to improve their performance and adapt to various tasks without relying solely on large sets of labelled data. Together, these strategies offer a promising path to overcome data constraints and improve the effectiveness and versatility of language models.
With these new approaches, the horizons of AI learning are expanded beyond the boundaries of human-stored knowledge, giving rise to a new and promising era of limitless opportunities.
Written by Cristian Muñoz, Machine Learning Researcher at Holistic AI.
Originally published at https://www.holisticai.com.
