Rapid scaling and deployment of machine learning models in mission critical systems

One of the main issues in MLOps(machine learning operations) is how to manage and maintain various KPIs of productionized ML model (API). Most commonly used metric to track and monitor the performance is the RPS (requests per second) of the API which is directly managed through scaling of the underlying model copies. Businesses have lost millions of dollars and their operations affected if scaled ineffectively leading to unacceptable performance levels, especially for businesses in public service — eg, Air Traffic Control, Defense sector, fraud detection, and other mission critical systems.
In this article, I am going to cover the concept of model copies and how a complicated process such as this can be done with few clicks using Watson Machine Learning (WML).
Importance of Model Copies
Model copies are a major requirement when it comes to model(s) deployed for online servicing. Online deployment is meant for real time scoring of the model and depending on your use case, you may have a requirement to service each API request sent to your productionized model within a certain time, called response time. For example, if you have a deployed credit risk model, an ML model meant to predict whether a credit applicant is at a risk of defaulting, you have very limited time before your model needs to decide whether the applicant is at risk or not, else, your customer will start to get frustrated. If, say, the desired average response time for such a use case should be within 200ms, with at least 95% requests serviced within 300ms, then your model can service at max 3–4 requests every second. However, if the average number of requests (RPS — Requests per second) your model gets is about 25 RPS and a peak of 45 RPS, your model will never be able to service more than the said 3–4 RPS, while maintaining the same desired response time. The remaining requests will be waiting in queue, leading to growing wait time and customer frustration.
The solution to this, is to create replicas/copies of your model in deployment, while maintaining the same REST endpoint, so that all requests can be sent to that endpoint. If you try to do this manually, you will need to be aware of how to write a yaml configuration file and redeploy every time you want to scale your copies up or down depending on the load requirement and RPS demand. This makes scaling really difficult to manage. However, using WML, you can do it in just a few clicks.

Concurrent load testing
If you do concurrent load testing on a deployed model, with a single copy with 3 concurrent users, with a maximum RPS of 4, you can meet the desired response time as mentioned above. These were run for 100 seconds to maintain the same standard across the tests, and they were conducted using Locust, which is a scriptable and scalable performance testing tool. To learn more about how to do in-depth concurrent load testing using Locust on a model deployed in WML, refer to this medium article.

If you redo the same test with 10 concurrent users, leading to a maximum RPS of around 11, you see the average response time going above the expected response time, and only about 70% of all responses being served within the expected time, which is unacceptable for us. This is due to a single copy not being able to deal with all the increased requests, leading to the delayed response. If the demand increases even further, the response time will start to increase drastically due to an even more increase in requests waiting in queue.

Scale Model Copies
In order to meet this increased demand, you now need to increase the number of copies, so more requests can be serviced concurrently.
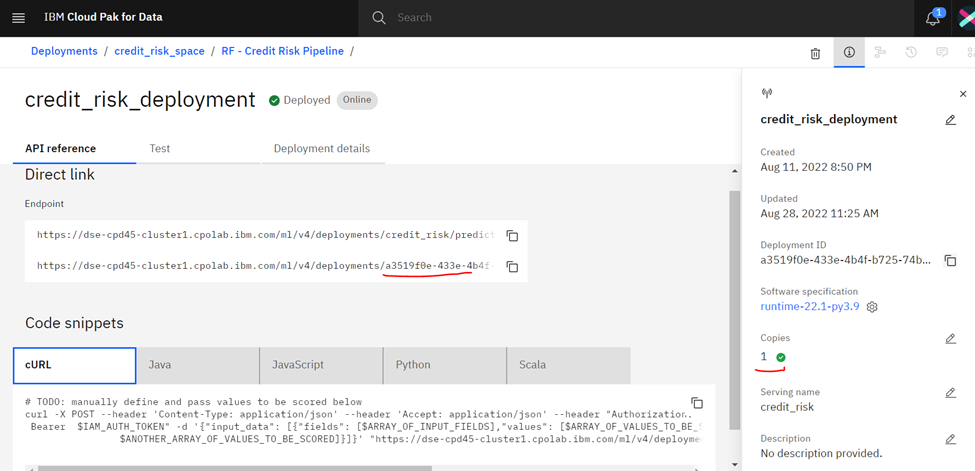
Now, I’ll walk you through the exact steps to achieve this. In IBM Cloud Pak for Data, go to the Deployments section in the deployment space of WML, where your model is deployed, then click on the desired deployed model, whose copies you want to scale. In this example, the model is a Random Forest model, deployed in the space called credit_risk_space, with the deployment name of credit_risk_deployment. It currently has 1 copy.
Click on the pencil icon on the Copies section and enter how many copies you want to scale it to. Considering the average response time requirement of less than 200ms and 95% requests serviced within 300ms, you will create 4 copies, and this will be done in just few seconds. WML will create the 3 additional copies of the nodes, readying it for servicing. All 4 copies will share the exact same endpoint, ensuring simplicity for the user, while the engine in WML will take care of the load rerouting to maintain efficient operation.

Now performing concurrent load testing on the deployment with 4 copies, for 40 concurrent users with a RPS range of 45–50, you can see that you are still able to meet the desired response times.

If you want to also consider redundancies for a failure of a copy, you can just as easily increase the number of copies to 5. In the future if you want to further scale up or down depending on demand, you can easily do so, following the same steps as defined above.
Conclusion
Constantly scaling model copies based on demand to meet performance requirements is a key necessity in MLOps process, and having the ability to easily do so is becoming vital in mission critical systems.
Hope this article, helps you in better understanding how to achieve this using the capability of IBM Cloud Pak for Data. Thank you for reading and feel free to leave your feedback in the comments!

{kind=link}