Machine learning model replacement in complex and agile micro services architectures

This article provides an insider view on managing complex ML model deployments from the lens of operational excellence, challenges and mitigation strategies with specific focus on ML model replacements in complex micro services architecture and its large scale benefits in government and public service industries.
I am going to cover how this can be easily achieved in Cloud Pak for Data (CPD) , an end-to-end Data & AI Platform. Later in the article, I will also cover some of its limitations and how it can be addressed using another feature offered in the tool called Serving name.
Model Replacement
If you already have a model in production, the process doesn’t just end there. Typically you would continue to try to come up with an even better model and is a never-ending iterative process. For the example I am covering here, let’s consider the credit risk model that was trained, which is a model that predicts whether a credit applicant is at risk of defaulting, and in the first iteration, Random forest model came up as the best model/pipeline, which was then productionized using the deployment service called Watson Machine Learning (WML).
Over the course of time, I tried to further improve the model performance, and came up with an even better model in the next iteration, using XGBoost. This can be confirmed with testing on not just the test data, but also by comparing the model performance between Random Forest and XGBoost on new production data coming in for a certain period of time, in order to absolutely ascertain the better performance of this new model. Once it has been confirmed to be better, you would typically delete your original model in production and replace it by deploying the new and improved model.
However, one major issue with this process is that every new deployment creates a new endpoint and if you have any application(s) downstream that utilizes this endpoint, then all those applications are now broken, until you replace it with your new endpoint. This is not only painstaking, but in most enterprise teams, the team that builds and deploys the model and the team that manages the applications would be different, and you would typically have to file for a ticket, get approval and then initiate the model replacement to avoid major disruptions. This whole process could take from few weeks to sometimes months depending on all the red tape.
The solution to this, is to actually replace your model without changing the endpoint, thereby ensuring no disruption can happen, and that’s where WML comes to the rescue, where in a manner of few clicks you can replace your existing model in production with your new model seamlessly.
The first step is to promote your new model from the development stage to a space in the deployment stage. To do that, go to your project in Watson Studio, where your model currently resides. Click on the 3 dots on the right side of your model name and then click promote to space.

In the Target space section, select the space where your initial Random Forest model is already deployed. In this case, it’s named credit_risk_space, the other selections can be left as it is, and then click on Promote.

Once you do that, a pop up appears indicating the successful promotion of your asset. Now click on the deployment space tab highlighted in blue to directly go to the space where you just promoted your asset.

Now you should be able to see your asset in the assets section of the space.

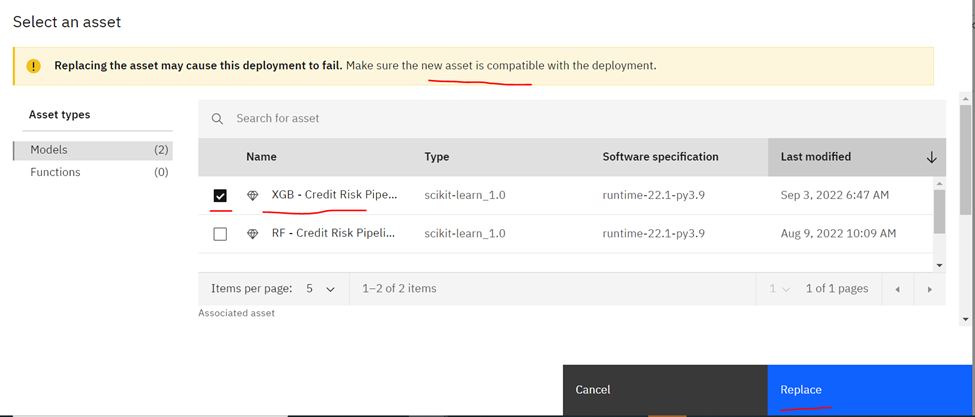
Click on the Deployments tab above, it should show your Random Forest (RF) model already in deployment, in this example it is named credit_risk_deployment. Now click on the deployment, where you can note down the endpoint for later comparison. In order to replace this deployed asset with your new and improved XGBoost (XGB) model, all you need to do is scroll all the way down on the right section and click on the pencil icon for Associated asset. You can also note and confirm that the existing underlying asset with the deployment is a Random Forest (RF) model.

Now a new window should pop up, where you can select the model asset XGBoost (XGB) to replace your existing deployed asset Random Forest (RF) and then click on Replace. And just like that, in a few seconds the new model is in production using the same endpoint which your application(s) can continue to consume without disruption.

The model is now replaced as you can see in the image below. You can also confirm that the Associated asset now shows XGBoost (XGB) model instead of Random Forest (RF), and the asset ID has changed as well, although the endpoint still remains the same. This is exactly what we were expecting to see.

The only caveat though as mentioned in the beginning of the article, and as you can see in the model replacement images above, the replacement model needs to be compatible with the existing deployment, meaning it should have the same model type, same software specification and use the same input feature set as your original deployment. If it is different, you won’t be able to replace the asset in this way. What to do if it is different? Not to worry, there is another capability you can use called Serving name.
Serving Name
If you want to replace the existing deployed model with one that has a different structure or format without needing to change the REST endpoint, then you can still do so, using the model serving name option, by using the same unique serving name. This serving name will act as the unique REST endpoint, which you can now use in your applications, ensuring none of them break. However, one minor drawback is, since a serving name has to be unique, you would need to delete your original deployment first, before you can deploy your new model. This means, that for the time gap where your original deployment is deleted and your new model is deployed, your endpoint won’t be operational. So make sure this operation takes place when model service is not needed or at least is at its minimum use.
Before we start, just like before in the model replacement steps, we already have the Random Forest (RF) model in deployment, note the REST endpoint. Apart from the expected alphanumeric characters, you now also see another endpoint with the name credit_risk. This is the unique serving name given for this deployment, you would use this in your application instead of the alphanumeric endpoint.

If you now want to replace this deployment with your XGBoost model or any model, even if it is of a different format or uses a different set of input features, you can either delete/retire your original model, which is the typical process. If for any reason, you still want to keep your initial model deployed but also want to replace the deployment your application uses with your new model, you can do so by changing the serving name instead, as your application will only look for the credit_risk serving name in the endpoint.

Once it is either deleted or the serving name edited, deploy your new model by clicking on the deploy option.

Now create a new deployment, the name can be anything, but you do need to ensure the serving name should be the same as before in order to ensure the continuity of your application’s operation. Then click Create.

In few seconds, your new deployment is operational. In the endpoint section do note that the alphanumeric generated endpoint is different than the previous one, as expected, however the other endpoint with the serving name “credit_risk” still remains the same. This will ensure the continuity of your application(s).

Conclusion
One of the biggest challenge for an enterprise in handling a ML model life cycle is the long and complicated process of replacing a model in production with a new and improved model, due to various dependencies of the application(s) in a distributed and agile micro services architecture on the endpoint of an existing deployment. The ability to replace the underlying asset without operational disruption is a game changer and will lead to reduced time to production, frequent model improvements, saving money and weeks of engineers time. For some ML models in healthcare and other industries, this advantage could potentially save more lives.
Hope you get to use this amazing capability of Cloud Pak for Data to help speed things in your business. Thank you for reading and please leave your feedback and any questions in the comments!

{kind=link}