金融科技系列3:金融情緒也可窺探財務風險

====================================
研究原創團隊:王釧茹研究員 (中央研究院資訊科技創新研究中心)
科普作者團隊:黃福銘教授、謝馨頤、蔡政宏、馮正毅、詹欣儒、吳岱恩、吳翊瑄、彭鈺湄(東 吳大學巨量資料管理學院)
指導計畫單位:科技部科教發展及國際合作司–前沿科技成果轉化暨應用推廣計畫
====================================
登 — — 登 — — 登 — — ,上課的鐘聲響起。
老師:「各位同學,今天要給大家一個特別的回家作業喔!最近選舉要到了對吧?請大家上網找任何一個候選人的政見,然後觀察網路上輿情的展現,看看誰最有可能當選。」
底下哀號一片。 「蛤~老師不要啦~」
老師:「那大家就開始分組討論,看可以用什麼方法分析吧!」
大家就在教室開始討論了起來。
小美:「你們有什麼想法嗎?」
小銘:「再給我一點時間思考一下啦!」
小宏:「我知道了!只要隨便搜尋一下應該會找到許多鄉民對候選人看法的文章吧! 我們只要用別人寫好的文章去預測就可以交作業啦!」
小宏一臉驕傲,覺得自己真是太聰明了
小美:「可是~會不會那個人預測的不準阿!」
小銘心裡想著「如果小精靈可以來救救我就太好了」
這時候,時間忽然停止,小精靈出現了。
小精靈:「小美說的有道理!」
小銘:「太好了,我就知道你會出現,畢竟這件事情與『預測』有關係」
小精靈:「不錯嘛!小銘你終於知道什麼事情可能會和人工智慧有關係了。」
小銘:「那當然!你每次跟我說我都很認真在聽呢!不過你說小美說的有道理?是什麼意思呢?」
小精靈:「因為文章的內容會因為寫的人而有所不同呀!如此,表達的觀點也會不一樣,你想想看這樣會有什麼問題呢?」
小銘:「會有他自己個人偏好的問題!!」
小精靈:「沒錯!所以,其實文章是有自己的『情緒』唷!你知道嗎?」
小銘:「『有情緒』?!不是只有有生命的人才會有情緒嗎?文章怎麼可能也有情緒,難道他也會像小宏一樣愛發脾氣嗎?」
小銘一臉嘻笑地將眼神往動作暫停的小宏身上。
小精靈:「這樣子說好了,從文章的內容中,我們應該可以很清楚地感受到內容是正向、負向還是不確定正負向的。舉例來說,『A候選人對於捍衛基本人權有果決的態度,贏得選民的信心。』,我們會認為是正向的;而『B候選人真的很糟糕,一點基本法律素養都沒有。』,很明顯就是負向的;不過,『C候選人做事的方法真的很獨特』,這句話我們無法直接判斷它是正向或者是負向,因為有可能在稱讚,又或者是在暗諷。」
小銘:「原來還可以從文章的情緒來分析哪個候選人可能會當選喔!」
小精靈:「這個這個方式叫做『情緒分析』(Sentiment Analysis),怎麼樣很有趣吧?」
不知不覺,小精靈如往常般,解答完小銘的疑惑就消失了,而時間又繼續的前進。
小銘:「同學們,我知道我們可以怎麼做這項作業了。我們可以從網路上的評論、文章看出民眾對候選人的情緒,大家對哪個候選人的情緒正向的越多,那個候選人就有可能越受選民們歡迎而當選了!」
小宏:「什麼意思?情緒?你在解釋清楚一點!」
於是,在小銘將小精靈和他解說的內容和組員們說明之後,大家又再一次投射崇拜的眼光在小銘的身上。
情緒分析(Sentiment Analysis),在維基百科上的定義是:
「文本情感分析(也稱為意見挖掘)是指用自然語言處理、文本挖掘、計算機語言學以及生物識別技術,系統化地識別、萃取及量化情感狀態及主觀訊息等方法來識別和提取原素材中的主觀信息。」
想必你心裡肯定說「什麼啦!看不懂!」,簡單來說,通常情緒分析主要處理的方式為自然語言處理(Natural Language Processing, NLP),以及文字探勘,或者也會搭配機器學習、深度學習的方式來建立模型,這些方法都是為了知道資料中所隱含的「情緒」是什麼。
首先,你還記得我們之前有提過的自然語言處理(Natural Language Processing, NLP)是什麼嗎?忘記的話,就趕緊翻翻之前的文章(〈人工智慧前言〉)囉。不過沒關係,我們再來複習一次。簡單來說,由於在電腦(機器)的世界中,它們彼此溝通的語言就是一堆「0」和「1」,人類為了和它們溝通發明了程式語言,例如:Python、Java、R等等。然而,我們將自己的語言溝通模式通稱為「自然語言」,當然啦!生活上我們不會稱呼我們的語言為自然語言。「自然語言」是相對於電腦這樣人工製造出的語言而有的名詞,所以,當我們需要利用電腦「處理」和人類彼此溝通有關的工作時(例如:文本理解),要先將內容轉換成電腦能夠理解、計算的形式電腦才能夠判讀語言的特性,這項工作我們就會稱它為自然語言處理。
自然語言處理包含了許多面向,生活上實際應用的也很廣泛,除了剛剛提到的情緒分析,另外像是文字或語音的辨識、解析及生成、文字校正和文本朗讀,以及我們熟知的「聊天機器人」都有應用到自然語言處理的技術。
接下來,你一定會想問「文字探勘又是什麼呢?和資料探勘是一樣的嗎?」其實,文字探勘(Text Mining)和資料探勘(Data Mining)主要的目的都是要在大量的資料中找出我們需要的資訊,但兩者的差別就在於資料探勘是著重在結構化的資料,而文字探勘則是非結構的資料。等一下,你該不會不知道什麼是結構與非結構的資料吧?在分析資料之前,除了收集資料外,最重要的就是整理資料了,那你就要知道資料大致上分成「結構化資料」和「非結構化資料」。「結構化資料」就是已經整理好的表格,隨時都可以拿來做數據分析,例如:炸雞店想要統計一天各種不同商品賣出了幾份賺了多少錢,資料的欄位可能就有商品項目、商品價錢、賣出份數、總金額等等,建立好欄位之後,再把資料丟進去,形成了表格形式,就是所謂的「結構化資料」;而「非結構化資料」就是指未經整理過的資料,資料沒有固定的欄位、格式,常見的圖片、文字、音樂、影片、PDF檔、網頁等等都是屬於「非結構化資料」。
那麼當「文字探勘」遇上「情緒分析」又是怎麼一回事呢?這就好像是每一位廚師對於同一種料理的處理方式都不盡相同,只要顧客覺得這道料理很美味,就達到做這道菜的目的了。所以,你可以把「情緒分析」當作是一道料理,它可以有好幾種處理的方式,例如:運用自然語言處理、文字探勘等等,目的都是要去判別文章、圖片或是報表中的「情緒」。
如果我們能找出文章、圖片或是報表中在特定主題或領域中,把這些看似不起眼的訊息分類出它們的情緒,那是不是可以在不同領域上發揮很大的功用呢?就像剛剛文章一開始,小銘的老師出的作業,在政治領域,我們可以從資料裡的政治情緒來觀測政策發佈後選民的接受度,以及輿論的改變。例如:德國的學者Andranik Tumasjan就利用超過100,000條的Twitter進行分析,通過觀察人們如何使用Twitter交換有關政治問題的訊息。這項研究主要是觀測在德國的聯邦選舉中,檢視Twitter是否是網路政治審議的工具、評估Twitter消息是否有意義的方式反應實際上選民的政治情緒,以及分析Twitter上的活動是否可用於預測現實世界中政黨或聯邦的受歡迎程度[1]。
另外,在財務資訊與財務風險領域中,國內中央研究院資訊科技創新中心的王釧茹助研究員與他的團隊則是運用情緒分析的方式來觀察財務報告上的潛藏情緒資訊,從資料中推敲出一些金融字詞的情緒,進而找出情緒文字與風險預測的關係。接下來,我們就來介紹這項在金融科技中運用到的人工智慧技術吧!
多數在財務資料分析的研究或實務處理上,傾向分析「硬資訊」,不過王釧茹老師與她的研究團隊在On the risk prediction and analysis of soft information in finance reports [2] 這篇研究中,讓金融界了解「軟資訊」也有其重要的用途。不過,到底什麼是「軟資訊」和「硬資訊」呢?
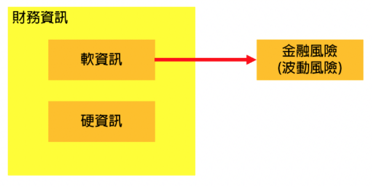
(圖二)
所謂的「軟」、「硬」資訊的觀念,根據Petersen在2004年提出的論文中的說明[3],「硬資訊」其實就是數量的資訊,「軟資訊」則是指文字資訊。以生活情境來理解,我們平常閱讀的文章、報章雜誌,都能夠歸類於「軟資訊」;天氣預報中的氣溫、降雨機率,或是股市資料中的股價、買賣量,就歸類於「硬資訊」。
在金融相關領域中,我們通常是藉由財務報表上或是市場資訊的「數字」來觀察局勢的發展,這些數字多為結構化的資料,也就是「硬資訊」;但現在不只運用數字來分析,還可以從文字資料中找出一些重要「軟資訊」進行搭配分析,例如:例如:財務報表中使用了哪些詞彙來描述公司經營的方向。
在王釧茹老師的研究中,軟資訊的分類主要是以Tim Loughran 和 Bill McDonald所歸納的財務情緒字典為基礎[4],這個字典將詞語分為六種不同的類別,正面、負面、不確定正負的商業用語,也有表達強烈信心或者微弱信心的詞語,另外也將法律用語歸類出來。

(圖三)
接著,分類好財務上的情緒詞語之後,就需要進行文字資訊的處理,就如同剛才所說一道料理有許多不同的作法,在文字處理上也有許多方式,王釧茹與他的團隊著在文字情緒分析的方式則是使用的TFIDF,此方法的全名為Term Frequency Inverse Document Frequency,這個方法是在計算一個字詞在一個文件中的重要程度。舉例來說,現在有許多文章一篇一篇的放在桌上,讀了其中一篇之後,你發現某個字詞(例如:開心、難過)不停地出現,你大概就知道這個字詞在這篇文章中有一定的重要性,但是如果文章一直出現你、我、他,或是許多連接詞(例如:然後、另外),你會覺得他們重要嗎?所以,強調一篇一篇是因為需要參考總體的模樣,如果某個字詞在所有文章中都普遍出現,就表示這個字詞的重要性不高。此方法的全名中,Term Frequency(TF)就是指字詞在單一篇文章出現的頻率,Document Frequency(DF)就是指字詞在所有文章中出現的頻率。當TF越高重要性越高,DF越高重要性越低,所以,才會這個方法才會出現Inverse這個文字,因為DF要加入倒數的概念,把反比的關係轉成正比的關係。

(圖四)
在觀察財務軟資訊的過程中,運用了上述的方法,找出了文字資訊中重要性較高的字詞後,在對照文字資訊發布之後的財務風險,王釧茹老師運用「公司股價的漲跌的比率」做為風險指標,若上漲或下跌的值,佔原始股價的比例越高,就代表公司股價的風險越高。此篇研究不只是直接計算財務資訊當中全部的文字,還更進一步運用財務資訊專用的辭庫,探討過濾掉與財務無關的資詞後,是否使分析結果更精確。實驗的結果顯示,在分析的過程中僅考慮財務相關的詞語,去除掉無關的連接詞、代名詞等,並不會比起整篇財報分析的結果還差,也就是說我們僅需要考慮與財務相關的字詞做分析,也能達到良好或是更佳的效果。
你一定會想問「那到底怎麼利用情緒詞語去『預測』企業財務風險呢?」,想想看,在前幾篇文章中,當我們需要「預測」的時候通常會派誰出場?對啦!就是利用建置機器學習的模型,研究團隊運用的有Regression(迴歸)與Ranking(排名)兩種機器學習的方法,讓電腦對照「前一年的文字資訊」與「後一年的風險指標」,分析出哪些字詞的出現,能夠準確預測公司的風險趨勢。演算法其中深奧的理論,我們在此不多著墨,簡單來說,若是一個金融市場的觀測員,每年都看年報和風險變化,他也能夠學習到哪些字詞的出現代表一間公司的趨勢走向,此篇研究運用的方法(Regression和Ranking)就是在讓電腦達成這件事情唷!
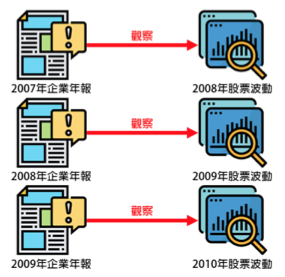
(圖五)
文字探勘的應用在學術研究上相當廣泛, Mcauliffe和Blei在2007年提出一篇研究[5],運用電影評論來預測電影的歡迎程度;Lin在2008年運用了財務相關的「軟資訊」、「硬資訊」,融合起來預測短時間股價的波動[6];文化大學的陳世榮教授,為了解決傳統社會科學研究均以人工標記來判讀文章的效率問題,用文字探勘的技術,還有「支持向量機」和「簡易貝氏分類器」,針對新聞文本解析文章潛在的文意,其中運用到的「貝氏定理」,是現在人工智慧領域中,運用相當頻繁的數學理論[7];還有還有,台灣大學的林守德教授,與台大法學院合作,除了運用剛才文章介紹的TFIDF方法,還加上了「條件機率模型」分析法條中的要素標籤,針對過去判決案件中,「強盜罪」、「恐嚇取財罪」的量刑依據,計算出判決對應量刑的機率,達到量刑預測的目的[8]。
讀完此篇文章,不知道你是不是很訝異有這樣的資訊處理方式呢?在人工智慧的時代,電腦、機器人是需要具備閱讀文字的能力的,透過此篇文章,讀者也可以再深入思考,生活中有哪些事物,其實也應用了文字探勘?或是,就由你來打造更有趣的文字處理方式吧!
[1] Andranik Tumasjan, Timm O. Sprenger, Philipp G. Sandner, Isabell M. Welpe (2010). Predicting elections with twitter: What 140 characters reveal about political sentiment.
[2] Tsai, M. F., & Wang, C. J. (2017). On the risk prediction and analysis of soft information in finance reports. European Journal of Operational Research, 257(1), 243–250.
[3] Petersen, M. A. (2004). Information: Hard and soft. Technical report.
[4] Tim Loughran and Bill McDonald, 2011, When is a Liability not a Liability? Textual Analysis, Dictionaries, and 10-Ks, Journal of Finance, 66:1, 35–65.
[5] Mcauliffe, J. D., & Blei, D. M. (2008). Supervised topic models. In Advances in neural information processing systems (pp. 121–128).
[6] Lin, M. C., Lee, A. J., Kao, R. T., & Chen, K. T. (2011). Stock price movement prediction using representative prototypes of financial reports. ACM Transactions on Management Information Systems (TMIS), 2(3), 19.
[7] 陳世榮. (2015). 社會科學研究中的文字探勘應用: 以文意為基礎的文件分類及其問題. 人文及社會科學集刊, 27(4), 683–718.
[8] Lin, W. C., Kuo, T. T., Chang, T. J., Yen, C. A., Chen, C. J., & Lin, S. D. (2012). Exploiting machine learning models for chinese legal documents labeling, case classification, and sentencing prediction. Processdings of ROCLING, 140
====================================
本系列科轉整合型計畫團隊簡介
◉總顧問:許永真教授。國立臺灣大學/資訊工程學系
◉顧問群:中華民國人工智慧學會理監事群
◉顧問:張羽祈(科普顧問/資料科學家)
◉總計畫:前沿人工智慧科研成果轉化:轉譯、呈現、與評估
(黃福銘教授。東吳大學/巨量資料管理學院)
◉子計畫一:人工智慧成果影響評估與轉譯及人工智慧知識圖譜之生成
(黃福銘教授。東吳大學/巨量資料管理學院)
◉子計畫二:視覺敘事:以資訊圖像與動態圖像敘述人工智慧
(林廷宜教授。國立臺灣科技大學/設計系)
◉子計畫三:前沿人工智慧科研成果轉化之成效評估與教育推廣
(吳穎沺教授。國立中央大學/網路學習科技研究所)
◉子計畫四:人工智慧科技轉化之教材/教案資源開發
(田曉萍教授。國立臺灣科技大學/應用外語系)
====================================









