Entendendo Redes Convolucionais (CNNs)
A versão em inglês deste artigo está disponível em Understanding ConvNets (CNN)
O reconhecimento de imagem é um clássico problema de classificação, e as Redes Neurais Convolucionais possuem um histórico de alta acurácia para esse problema. A primeira aplicação com sucesso de uma CNN foi desenvolvida por Yann LeCun em 1998, com sete camadas entre convoluções e fully connected. Desde então as CNNs ficaram cada vez mais profundas e complexas, como AlexNet em 2012, que, apesar de ter apenas oito camadas (cinco convoluções e três fully connected), apresenta sessenta milhões de parâmetros, e a GoogleNet com vinte e duas camadas e quatro milhões de parâmetros.

Antes de entender como funciona uma Rede Convolucional, é interessante conhecer qual foi a inspiração biológica para essa arquitetura. Em 1962, Hubel e Wiesel fizeram um experimento mostrando que alguns neurônios são ativados juntos quando expostos a algumas linhas ou curvas, conseguindo assim produzir o reconhecimento visual.
Essa é a basicamente a ideia principal de uma Rede Convolucional: filtrar linhas, curvas e bordas e em cada camada acrescida transformar essa filtragem em uma imagem mais complexa. Vamos entender mais detalhadamente nos próximos tópicos.
Entradas
Quando falamos em reconhecimento/classificação de imagens, as entradas são usualmente matrizes tridimensionais com altura e largura (de acordo com as dimensões da imagem) e profundidade, determinada pela quantidade de canais de cores. Em geral as imagens utilizam três canais, RGB, com os valores de cada pixel.

Convoluções
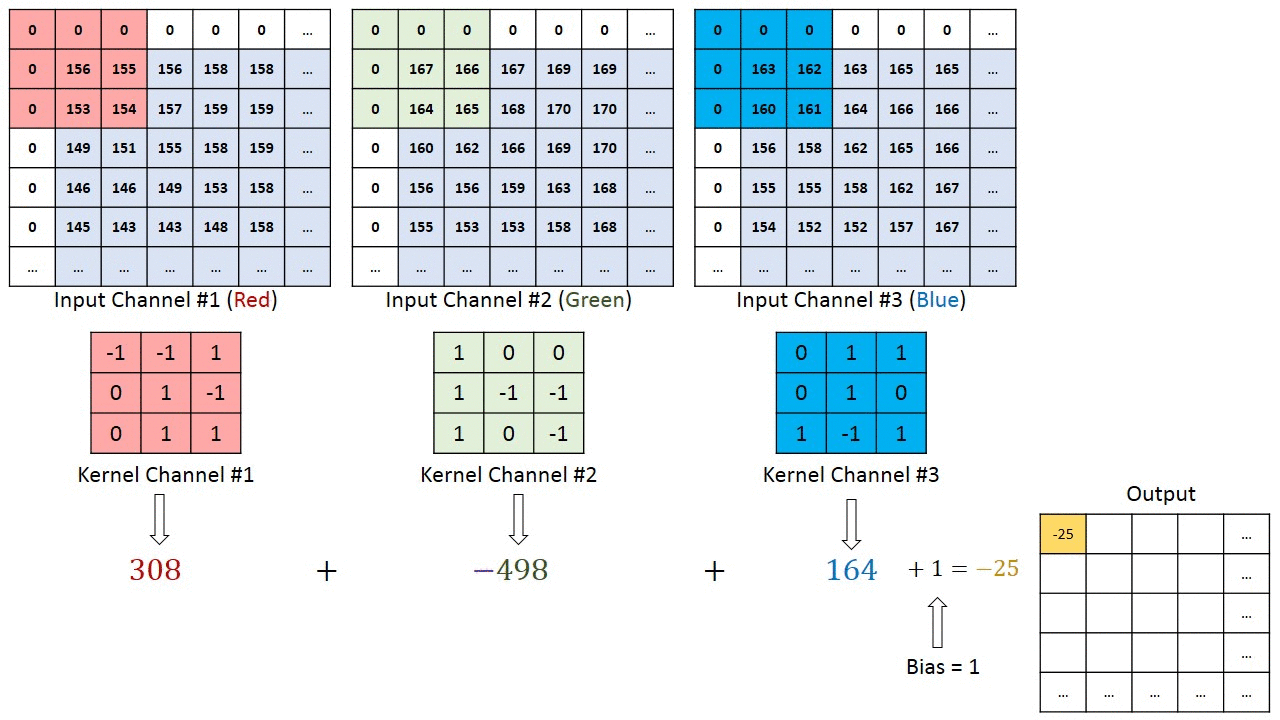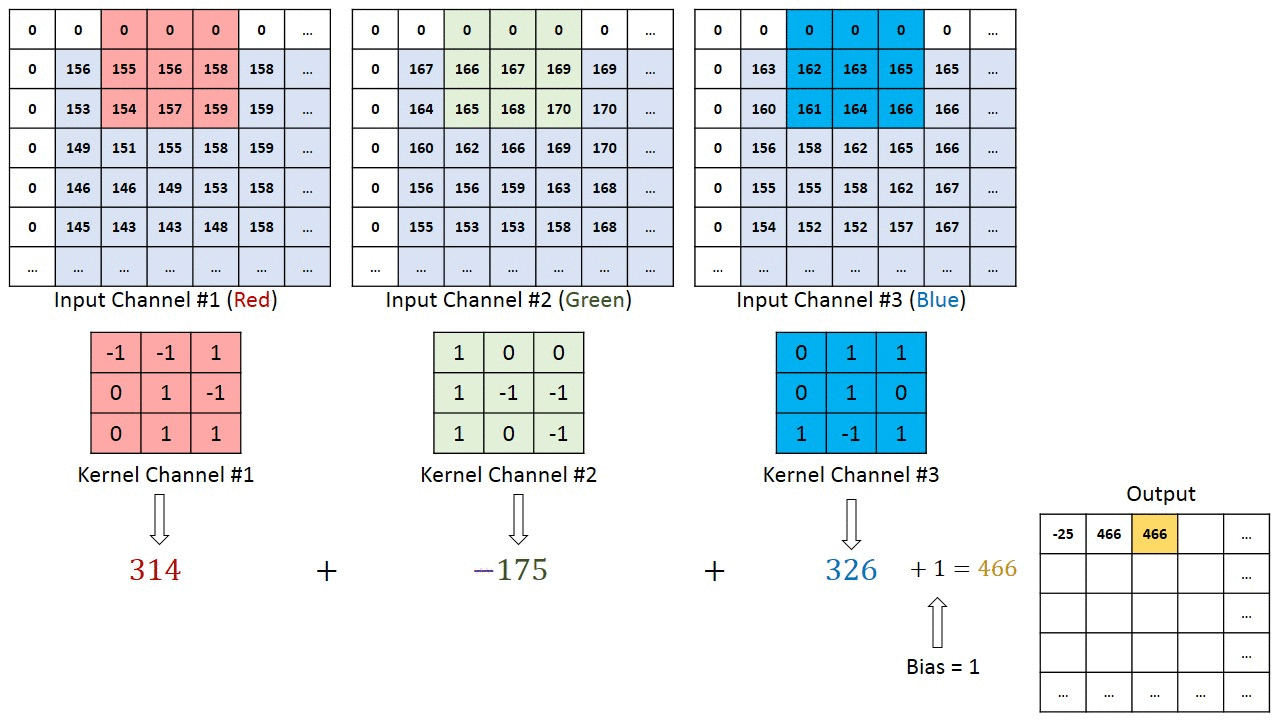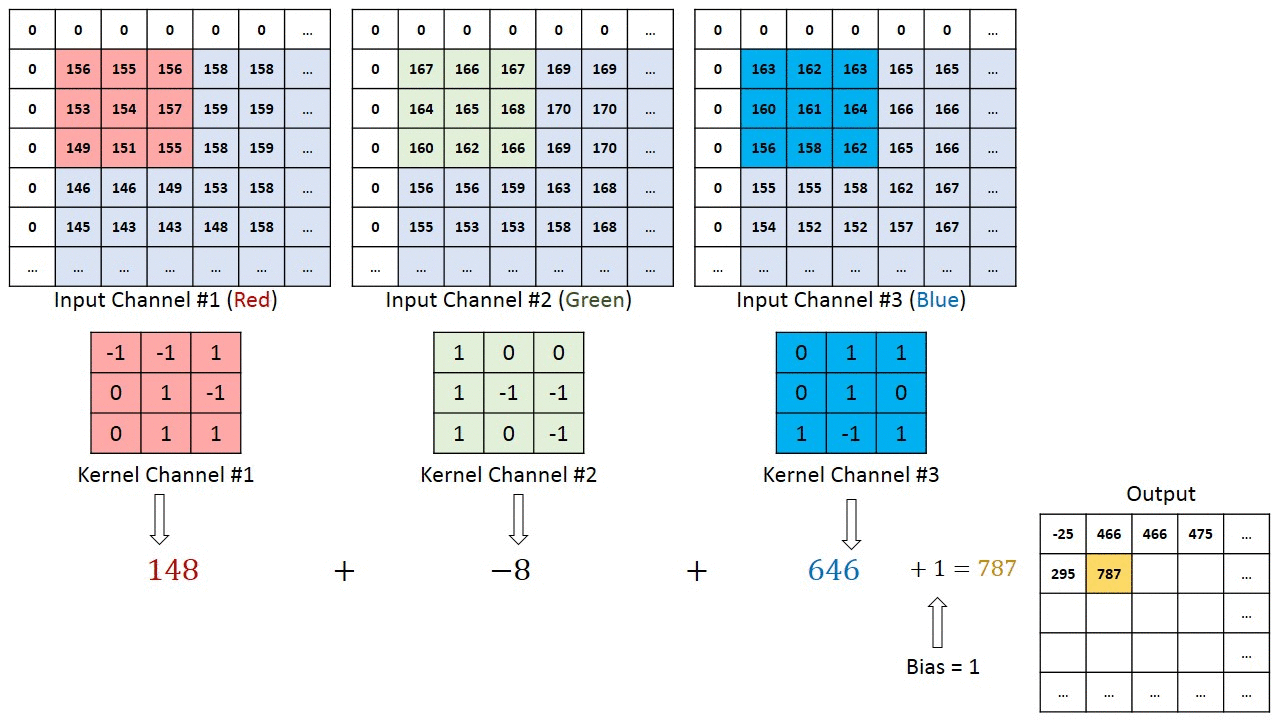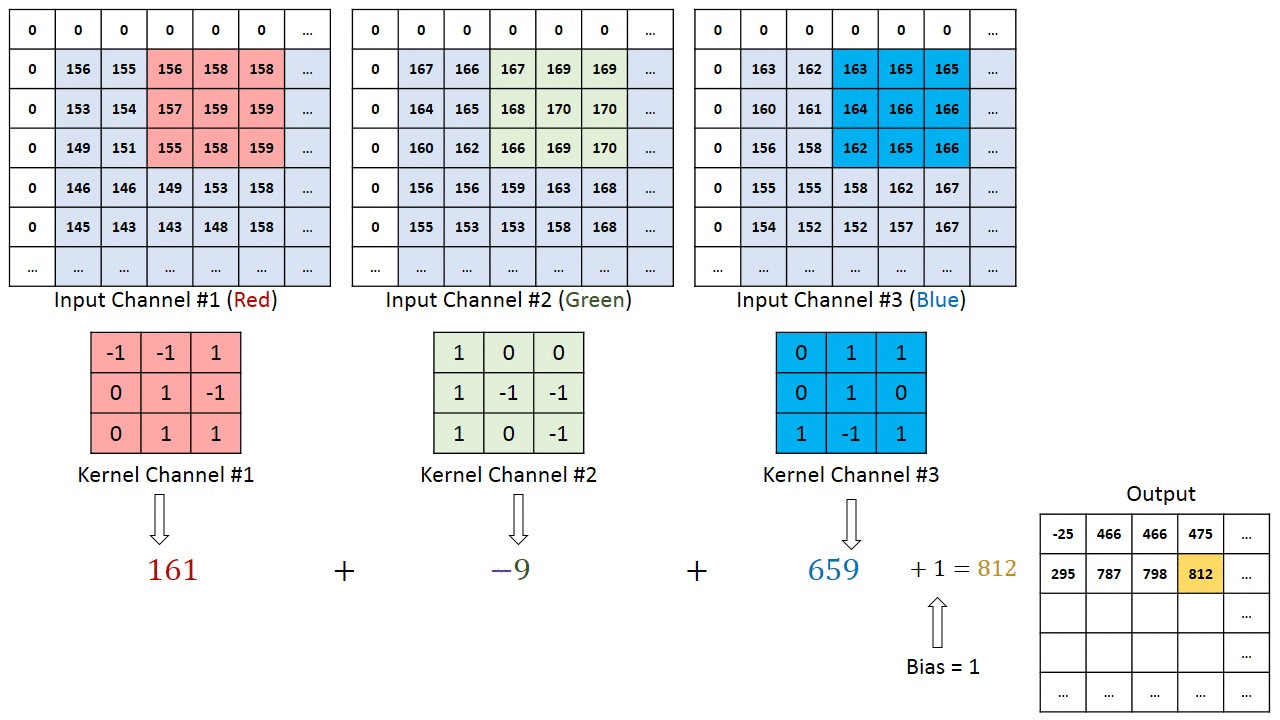
As convoluções funcionam como filtros que enxergam pequenos quadrados e vão “escorregando” por toda a imagem captando os traços mais marcantes. Explicando melhor, com uma imagem 32x32x3 e um filtro que cobre uma área de 5x5 da imagem com movimento de 2 saltos (chamado de stride), o filtro passará pela imagem inteira, por cada um dos canais, formando no final um feature map ou activation map de 28x28x1.

A profundidade da saída de uma convolução é igual a quantidade de filtros aplicados. Quanto mais profundas são as camadas das convoluções, mais detalhados são os traços identificados com o activation map.
O filtro, que também é conhecido por kernel, é formado por pesos inicializados aleatoriamente, atualizando-os a cada nova entrada durante o processo de backpropagation. A pequena região da entrada onde o filtro é aplicado é chamada de receptive field.
Para exemplificar, aqui temos um filtro que representa a curva ao seu lado.

Na imagem a abaixo está destacado o receptive field no qual será multiplicado pelo filtro acima.

Com essa combinação temos como resultado um número alto, indicando uma compatibilidade entre as curvas. Quando a imagem não possui nenhuma compatibilidade esse resultado chega mais próximo a zero.

Além do tamanho do filtro e o stride da convolução como hiperparâmetro, quem está modelando uma CNN também tem que escolher como será o padding. O padding pode ser nenhum, no qual o output da convolução ficará no seu tamanho original, ou zero pad, onde uma borda é adicionada e preenchida com 0's. O padding serve para que as camadas não diminuam muito mais rápido do que é necessário para o aprendizado.
Função de ativação
As funções de ativação servem para trazer a não-linearidades ao sistema, para que a rede consiga aprender qualquer tipo de funcionalidade. Há muitas funções, como sigmoid, tanh e softmax, mas a mais indicada para redes convolucionais é a Relu por ser mais eficiente computacionalmente sem grandes diferenças de acurácia quando comparada a outras funções. Essa função zera todos os valores negativos da saída da camada anterior.
Pooling
Uma camada de pooling serve para simplificar a informação da camada anterior. Assim como na convolução, é escolhida uma unidade de área, por exemplo 2x2, para transitar por toda a saída da camada anterior. A unidade é responsável por resumir a informação daquela área em um único valor. Se a saída da camada anterior for 24x24, a saída do pooling será 12x12. Além disso, é preciso escolher como será feita a sumarização. O método mais utilizado é o maxpooling, no qual apenas o maior número da unidade é passado para a saída. Essa sumarização de dados serve para diminuir a quantidade de pesos a serem aprendidos e também para evitar overfitting.
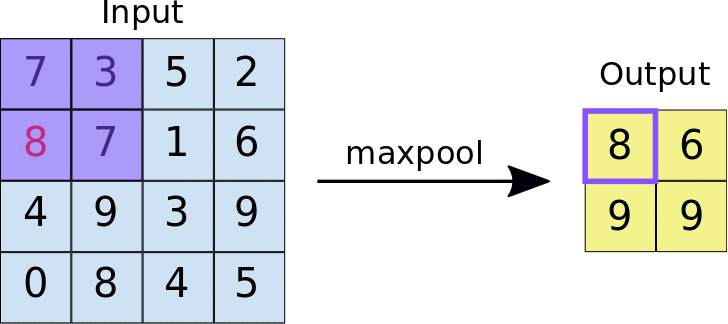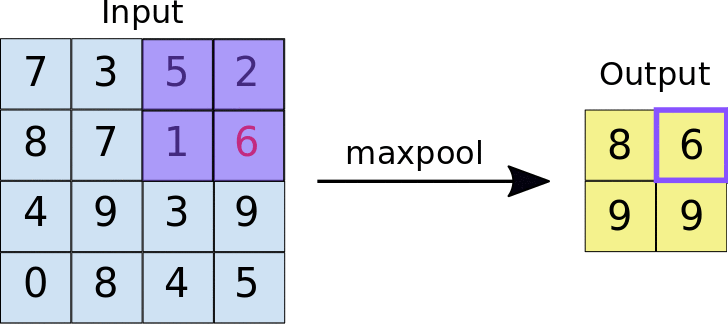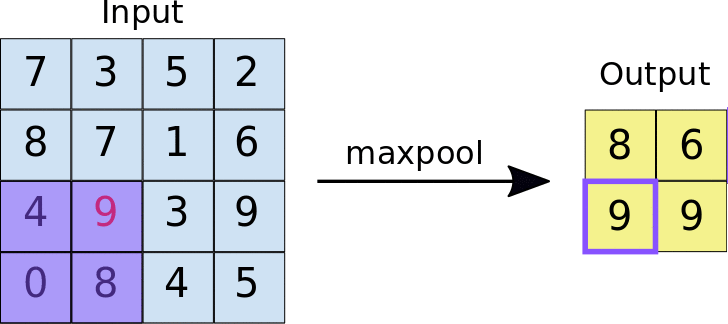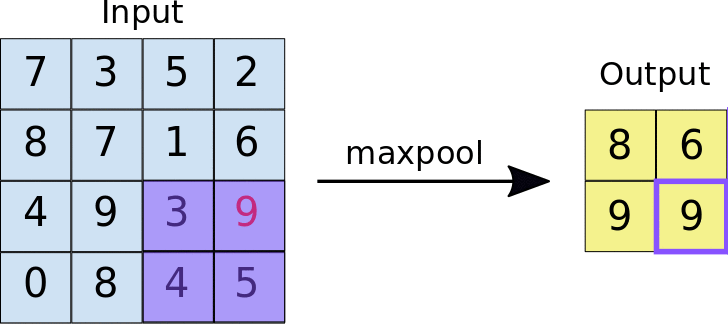
Fully connected
Ao final da rede é colocada uma camada Fully connected, onde sua entrada é a saída da camada anterior e sua saída são N neurônios, com N sendo a quantidade de classes do seu modelo para finalizar a classificação.
Na Prática!
Abaixo apresento um código simples de exemplo para a construção de um modelo usando CNNs. No código utilizo o Tensorflow, um framework de machine learning, com o Keras, uma API de alto nível para redes neurais. Neste exemplo uso o conjunto de dados Cifar-10 com 60.000 imagens de 32x32 dimensões e dez classes.
import matplotlib.pyplot as plt
import numpy as np
import tensorflow as tf
from keras.models import Sequential
from keras.layers import Dense
from keras.layers import Flatten
from keras.layers import Dropout
from keras.optimizers import SGD
from keras.layers.convolutional import Conv2D
from keras.layers.convolutional import MaxPooling2D
from keras.utils import np_utils
# Loading the CIFAR-10 datasets
from keras.datasets import cifar10batch_size = 32
n_classes = 10
epochs = 40(x_train, y_train), (x_test, y_test) = cifar10.load_data()height = x_train.shape[1]
width = x_train.shape[2]# Validation dataset splitting
x_val = x_train[:5000,:,:,:]
y_val = y_train[:5000]
x_train = x_train[5000:,:,:,:]
y_train = y_train[5000:]print('Training dataset: ', x_train.shape, y_train.shape)
print('Validation dataset: ', x_val.shape, y_val.shape)
print('Test dataset: ', x_test.shape, y_test.shape)
Training dataset: (45000, 32, 32, 3) (45000, 1)
Validation dataset: (5000, 32, 32, 3) (5000, 1)
Test dataset: (10000, 32, 32, 3) (10000, 1)
# Printing some images
cols=2
fig = plt.figure()
print('training:')
for i in range(5):
a = fig.add_subplot(cols, np.ceil(n_classes/float(cols)), i + 1)
img_num = np.random.randint(x_train.shape[0])
image = x_train[i]
id = y_train[i]
plt.imshow(image)
a.set_title(label_names[id[0]])
fig.set_size_inches(8,8)
plt.show()fig = plt.figure()
print('validation:')
for i in range(5):
a = fig.add_subplot(cols, np.ceil(n_classes/float(cols)), i + 1)
img_num = np.random.randint(x_train.shape[0])
image = x_val[i]
id = y_val[i]
plt.imshow(image)
a.set_title(label_names[id[0]])
fig.set_size_inches(8,8)
plt.show()fig = plt.figure()
print('test:')
for i in range(5):
a = fig.add_subplot(cols, np.ceil(n_classes/float(cols)), i + 1)
img_num = np.random.randint(x_train.shape[0])
image = x_test[i]
id = y_test[i]
plt.imshow(image)
a.set_title(label_names[id[0]])
fig.set_size_inches(8,8)
plt.show()

# Convert labels to categorical
y_train = np_utils.to_categorical(y_train, n_classes)
y_val = np_utils.to_categorical(y_val, n_classes)
y_test = np_utils.to_categorical(y_test, n_classes)# Datasets pre-processing
x_train = x_train.astype('float32')
x_val = x_val.astype('float32')
x_test = x_test.astype('float32')
x_train /= 255
x_val /= 255
x_test /= 255
Este modelo conta com cinco camadas de convoluções e duas camadas de rede fully connected. O otimizador utilizado é o Stochastic Gradient Descent (SGD) com learning rate de 0.01.
def create_model():
model = Sequential()
model.add(Conv2D(filters=128, kernel_size=(3, 3), input_shape=(height, width, 3), strides=1, padding='same', activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(filters=128, kernel_size=(3, 3), strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Dropout(0.25))
model.add(Conv2D(filters=64, kernel_size=(2, 2), strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=(1,1)))
model.add(Conv2D(filters=32, kernel_size=(2, 2), strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=(1,1)))
model.add(Conv2D(filters=32, kernel_size=(2, 2), strides=1, activation='relu'))
model.add(MaxPooling2D(pool_size=(1,1)))
model.add(Dropout(0.25))
model.add(Flatten())
model.add(Dense(64, activation='relu'))
model.add(Dense(n_classes, activation='softmax'))
return modeldef optimizer():
return SGD(lr=1e-2)model = create_model()
model.compile(optimizer=optimizer(),
loss='categorical_crossentropy',
metrics=['accuracy']
)
model.fit(x_train, y_train, batch_size=batch_size, epochs=epochs, validation_data=(x_val,y_val),verbose=1)
model.summary()
O comando summary() mostra algumas informações sobre as camadas do seu modelo. Podemos ver as dimensões de cada camada e os parâmetros aprendidos em cada etapa.

scores = model.evaluate(x_test, y_test, verbose=0)
print("Accuracy: %.2f%%" % (scores[1]*100), "| Loss: %.5f" % (scores[0]))Como resultado desse modelo temos:
Accuracy: 75.24% | Loss: 0.71711
Apesar da acurácia desse modelo nesse dataset ser de apenas 75%, com CNNs mais complexas a acurácia atingida no Cifar-10 pode chegar a 95%. Esse link mostra as redes que obtiveram resultados com as mais altas acurácias em cima do Cifar-10.
Deixo aqui alguns links de referências usados por mim para escrever este artigo, de onde também peguei algumas imagens. Recomendo a leitura de todos (;
— Stanford CS class CS231n: Convolutional Neural Networks for Visual Recognition : http://cs231n.github.io/
— A Beginner’s Guide To Understanding Convolutional Neural Networks: https://adeshpande3.github.io/adeshpande3.github.io/A-Beginner%27s-Guide-To-Understanding-Convolutional-Neural-Networks/
— Neural Networks and Deep Learning Book: http://neuralnetworksanddeeplearning.com/chap6.html
— Machine Learning Guru Blog: http://machinelearninguru.com/computer_vision/basics/convolution/convolution_layer.html
