Apache Iceberg Reduced Our Amazon S3 Cost by 90%

The new generation data lake table formats (Apache Hudi, Apache Iceberg, and Delta Lake) are getting more traction every day with their superior capabilities compared to Apache Hive. They enable cost-effective cloud solutions for big data analysis with ACID transactions, schema evolution, time travel, and more.
Table Formats
Table format technology is essential for big data environments to properly read, write and manage large datasets in distributed storage systems. Apache Hive was the go-to solution for the Hadoop era and facilitated analyzing data with its SQL interface. However, Apache Hive was designed with HDFS in mind, which does not translate well to object storage systems like Amazon S3.
On the contrary Apache Hudi, Apache Iceberg, and Delta Lake are designed with the modern cloud infrastructure in mind to perform better and cost less on the cloud with petabyte-scale datasets.

Cloud Competency
The main drawback of Apache Hive is the lack of grained metadata and relying on the directory listing the partitions with O(N) complexity for query planning. The table and partition metadata are stored in Hive Metastore backed by an RDBMS and it is required to be queried to find out which directories should be read for the requested data. Then, the directories are listed to find out the actual data files. The Hive Metastore and directory listing causes great bottlenecks with increased partition count on a table, especially given that the directory listing on object storage is actually scanning for files with a prefix and it is quite costly.
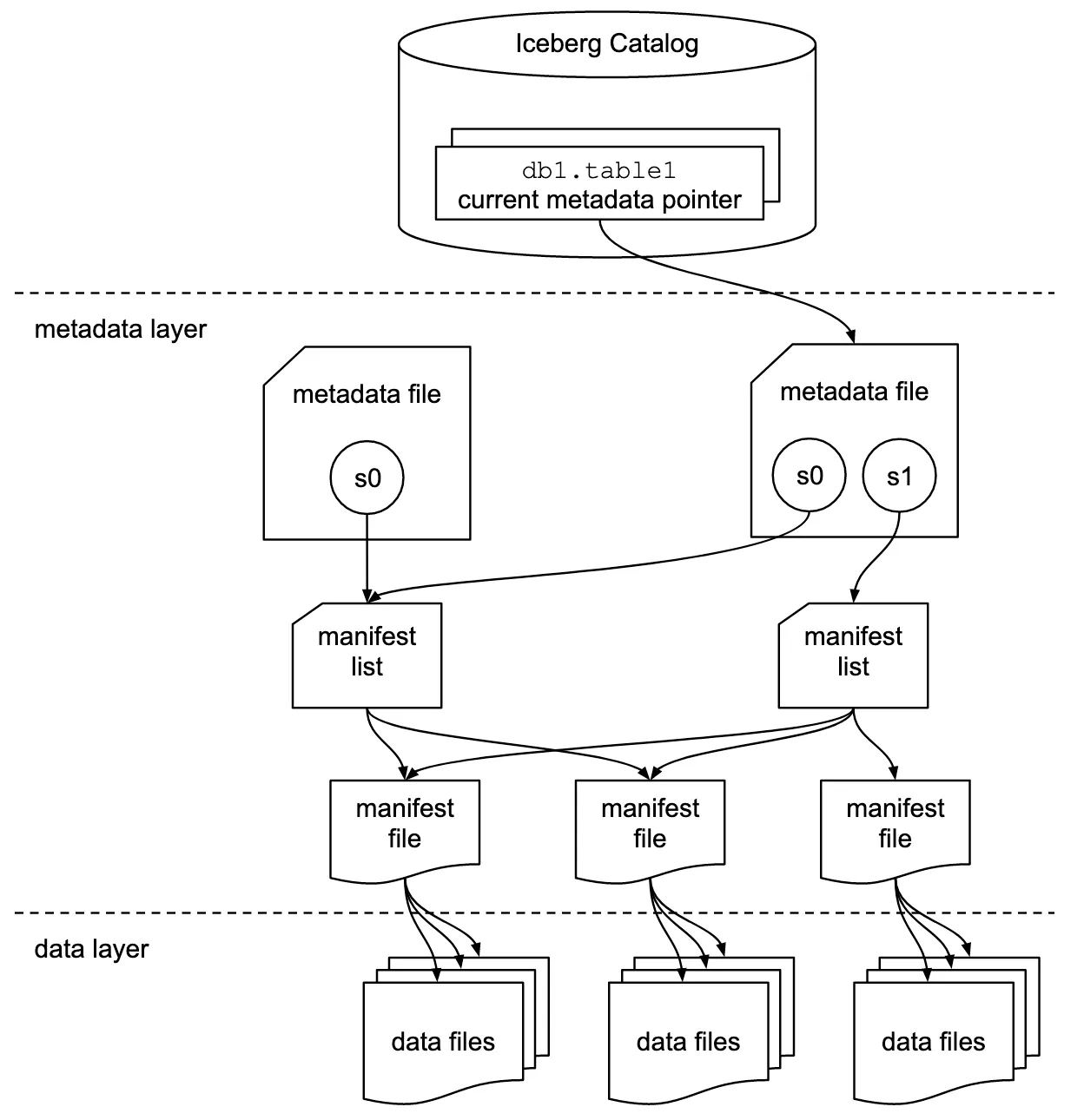
The next-generation table formats leverage metadata to do the heavy lifting. The metadata defines the table structure, partitions, and the data files that compose the table, eliminating the need to query a metastore and list directories. Apache Iceberg uses a snapshot approach and performs an O(1) RPC to read the snapshot file, therefore Apache Iceberg tables can scale easily without worrying about the performance with increased partition count.
Performance and Cost Effects
Apache Iceberg is designed for huge tables and is used in production where a single table can contain tens of petabytes of data. Another design goal is to solve correctness problems that affect Hive tables running in Amazon S3. Achieving these goals enables Iceberg to be a cost-effective solution on Amazon S3.
At Insider, we are using Amazon EMR for our Spark workloads that are performing heavy ETL and machine learning operations to fuel our product recommendation and predictive customer segmentation capabilities. Running these workloads as cost-effective as possible is always important for us. We value pushing our technology to the edge to achieve so. You can also read how Spark 3 helped us reduce our EMR costs. Migrating our Hive-backed data lake to Iceberg was a similar decision for us. Check out this blog post if you are interested in how we actually planned, architected, and performed the migration.

Our Hive tables were using Apache ORC file format with Snappy compression as it was the best option at the time we benchmarked it. During the benchmarking of the new generation table formats, we also benchmarked the file formats and compression algorithms. We ended up using Apache Parquet file format with Zstandard compression as the result of the benchmarks on our data. You can find one of the benchmarks in the figure above. Also, there is a great blog post by Uber describing cost efficiency for big data file formats, and it guided us a lot.
The reasons that cause Hive to have performance issues on the cloud also lead to extra costs. First, there is the cost of running an RDBMS for the Hive Metastore. Then, there is the cost of directory listings. Combined with the default 200 partitions of Spark and the small file problem, data file discovery and data reading are extremely costly. For us, it was five times the storage cost as can be seen in the figure below.

With Apache Iceberg, it is possible to configure the file size for a table with write.target-file-size-bytes parameter, which is 512MB by default. This results in merging data until the target limit and writing out big files to Amazon S3. Iceberg also has maintenance tools to compact data files to decrease the number of files. Having a few big files instead of a lot of small files helps in two ways.
- As each partition contains much fewer files, which are actually objects, querying a table reads much fewer objects. This reduces HeadObject and GetObject costs of Amazon S3 dramatically, which was around 90% in our case.
- There are much fewer object reading and file opening operations. Combined with the removed bottleneck of Hive Metastore for query planning, the Spark jobs are more performant, therefore, the EMR runtime decreases as well. In our case, we saved around 20% of EC2 and EMR costs.
Apache Iceberg is a great open table format for slowly changing big datasets. It is fairly easy to set up on Amazon EMR with a couple of lines of configuration. It is a cost-effective solution to use Amazon S3 for the data lake storage layer. Iceberg also provides a wide set of table management features such as schema evolution, hidden partitioning, time travel, and more. If you are using Apache Hive on AWS, you may consider trying out Apache Iceberg for performance and cost savings.
