Understanding Laravel Pipelines
Today we will talk about the Laravel Pipeline class. Many developers not known this gem because this feature is not documented on the website. However, this is a very useful feature for organizing huge methods.

Let’s start to explore the API documentation:
What is Pipeline?
In Laravel, the Pipeline class is implemented based on the Chain of Responsibility (aka CoR) design pattern.
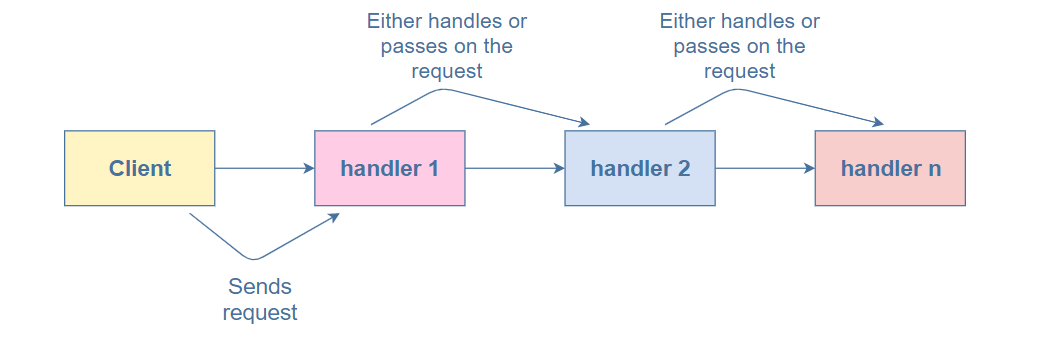
In summary; the pipelines take a job, process it, and forward it to the next pipeline.

In Laravel, the pipe class has two parameters: one of the data and the other is the forwarder (aka: next closure) callback. Each pipe class handles the given data and then forwards it to the next pipe class.
Chain of Responsibility Design Pattern
CoR is a behavioral design pattern. This pattern is process the given data with many handlers. When the request arrived at to pipe class, it processes the data and forwards the next one. The rule is simple.

Developers have used this pattern even if they don’t know its name. In the real world, the middleware layer is CoR.
Laravel Abstraction
The Pipeline is an abstracted CoR pattern. Laravel gives us some magic methods. Let’s meet them. The pipe class looks like that:
The $data can be any type. You can pass the Eloquent model or DTO etc...
In the above example, the $content will be passed to pipes in the defined order.
The default handler method is handle but you can change this with via the method. If you changed it, your pipe class must have the defined method.
And finally, Laravel gives us two options to us. If we use thenReturn it will return the data $contentwhen the pipeline is complete. You can also use the thenmethod instead. Here is an example:
Example Usecase
In this section, we’ll make a real-world example. Before saving the data, we will pass some business rules.
The pipeline classes will process the data. After processing the Pipeline returns the data and it will be saved with the Repository layer.
That’s it. As you can see, you can decide something in your pipe class. If passed your rules, the handler will work. Otherwise, you can pass the data to the next pipeline without manipulation.
In the pipeline, you can store data in your storage, you can send requests to API, or can change the original data.
Conclusion
This is not the only/correct way to solve problems. This is an idea for you. You can feel free to choose the correct way.
You can create small parts of business logic with Laravel’s pipeline instead of one big class or method. Easily maintained extendable and small test cases. It sounds pretty good.
If you liked this article, you can also check this one or our Insider Engineering blog.

{kind=link}