Elasticsearch ตั้งแต่เริ่มต้นยันใช้งานได้จริง

เชื่อว่าเกือบทุกคนที่ทำงานทางด้าน Back-end ย่อมมีโอกาสที่จะได้ใช้งาน Database ในการจัดเก็บ, Query, หรือ Search ข้อมูลไม่มากก็น้อย และหลายครั้งเราก็ต้องมานั่งกังวลว่า Database ที่เราเลือกใช้ หรือการออกแบบวิธีเก็บข้อมูลของเรานั้นจะส่งผลต่อการ query ข้อมูลมากน้อยเพียงใด เมื่อข้อมูลที่จัดเก็บมีปริมาณมากขึ้นเรื่อยๆ
Database ของเราจะสามารถ query ข้อมูลปริมาณมากได้หรือไม่….?
Database ของเรายังสามารถ query ข้อมูลได้เร็วอยู่ไหม….?
คำถามเหล่านี้จะคอยหลอกหลอน Back-end Developer มือใหม่จำนวนมาก ที่เพิ่งทำระบบหลังบ้านเสร็จแต่ก็ยังขาดความมั่นใจ เมื่อนึกได้ว่าระบบที่ตนสร้างนั้นจะต้องถูกใช้ในการบริหารจัดการข้อมูลปริมาณมาก ผมเองก็เคยเป็นหนึ่งในนั้น…จนกระทั่งผมได้รู้จักกับ Elasticseach
เพราะฉะนั้นบทความนี้เลยถูกเขียนขึ้นให้เพื่อคนที่มีปัญหาแบบเดียวกันนี้ สามารถเข้าใจว่า Elasticsearch คืออะไร ทำงานอย่างไร และใช้งานในการจัดเก็บและค้นหาข้อมูลปริมาณมากได้อย่างไร โดยบทความนี้จะอธิบายโดยอ้างอิงจาก Elasticsearch version 7.5 ซึ่งเป็น version ใหม่สุด ณ วันที่ผมเขียนบทความนี้
Elasticsearch คืออะไร ?
หลายคนอาจจะเคยได้ยินว่า Elasticsearch คือ Search engine นี่นา แล้วเกี่ยวอะไรกับ database สรุปแล้วมันคืออะไรกันแน่
จริงๆ แล้ว Elasticsearch นั้นเป็นได้ทั้ง Database และ Search engine ในเวลาเดียวกัน เราสามารถใช้มันเก็บข้อมูลโดยกระจายข้อมูลให้อยู่หลายๆ เครื่องหรือที่เรียกว่า Node ใน Cluster ของเราได้ โดยแต่ละ Node ของ Elasticsearch ที่แบ่งกันถือข้อมูลอยู่นั้น จะมีความสามารถในการ Search ไม่ว่าจะเป็นการ query ง่ายๆ ไปจนถึง Full text search แบบซับซ้อน โดยใช้ resource ในเครื่องของตนเพื่อช่วยกันค้นหาข้อมูล ทำให้การ search นั้นเสร็จได้ในเวลาอันรวดเร็ว และเมื่อไหร่ที่รู้สึกว่าการ search เริ่มใช้เวลานานเพราะข้อมูลมีจำนวนมากขึ้น เราก็สามารถเพิ่ม Node ใหม่เข้าไปใน Cluster ได้ โดย Elasticsearch จะกระจายข้อมูลไปยังเครื่องใหม่ให้อัตโนมัติ ทำให้เราสามารถ Scale up ตามปริมาณการใช้งานที่จะเกิดขึ้นในอนาคตได้
Elasticsearch ทำงานอย่างไร ?
หากคุณรู้จักหรือเคยใช้ MongoDB มาก่อน การทำความเข้าใจ Elasticsearch จะเป็นเรื่องง่ายมาก เพราะทั้งสองตัวนี้ต่างก็เก็บข้อมูลในรูปแบบ JSON Document เป็น Non-relational Database เหมือนกัน และมีความเป็น Schema-less เหมือนกัน แต่โครงสร้างและคำศัพท์ที่ใช้อาจจะต่างกันออกไปสักหน่อย โดย Keyword สำคัญของ Elasticsearch มีด้วยกัน 4 คำคือ Cluster, Node, Index, และ Shard ซึ่งสามารถแสดงเป็นภาพได้ดังนี้

Cluster คือกลุ่มของ Node ที่มี network เชื่อมถึงกันได้ โดย Node แต่ละอันที่อยู่ใน Cluster เดียวกันจะสามารถสื่อสารและส่งผ่านข้อมูลถึงกันได้
Node คือเครื่องคอมพิวเตอร์ที่ทำการลงโปรแกรม Elasticsearch ไว้ โดย Node จะสามารถใช้ resource ของเครื่องในการเก็บและ search หาข้อมูลที่เก็บอยู่ได้
Index เป็น configuration ที่ใช้กำหนดว่าข้อมูลจะถูกจัดเก็บใน Shard จำนวนกี่ Shard มี Replica shard จำนวนเท่าไหร่ เพื่อที่จะให้ข้อมูลนั้นสามารถกระจายไปอยู่หลายๆ Node และมีข้อมูลสำรองในกรณีที่มีบาง Node ล่มได้ นอกจากนี้ Index ยังเป็นที่เก็บค่าของ Mapping Type ซึ่งเป็นตัวกำหนดว่าในแต่ละ record ของข้อมูล มีรูปแบบการเก็บยังไง มี field อะไรบ้าง และ field ไหน type อะไร โดยผู้ใช้สามารถเลือกกำหนด Mapping Type เอง (Schema) หรือ ให้ Elasticsearch กำหนดให้ (Schema-less) เป็นราย field ก็ได้ ซึ่งถ้าจะให้เปรียบเทียบก็คล้ายกับ Table ใน SQL Database หรือ Collection ใน MongoDB นั่นเอง
Shard เป็นที่เก็บข้อมูลจริงๆ ของ Elasticsearch โดยข้อมูลจะถูกจัดเก็บในรูปแบบ JSON Document ซึ่ง Shard จะแบ่งได้เป็น 2 ชนิดคือ Primary shard และ Replica shard
Primary shard เป็นที่เก็บข้อมูลจริงที่จะถูกใช้เป็นหลัก โดยจำนวนของ Shard นี้ จะเป็นสิ่งตัดสินว่า Index ที่เราสร้างนั้นจะสามารถ scale ได้สูงสุดกี่เครื่อง เราสามารถสร้าง Index ที่มี Shard มากกว่าจำนวน Node ใน Cluster ไว้ก่อนได้ เช่น เราสร้าง Index ที่มี 5 Primary shard ใน Cluster ที่มีเพียง Node เดียว เมื่อเราเพิ่ม Node ใหม่เข้าไปใน Cluster ตัว Shard ของเราก็จะถูกกระจายไปในเครื่องใหม่ ซึ่งสามารถทำได้สูงสุด 5 เครื่องตามจำนวน Shard ที่เรามีนั่นเอง
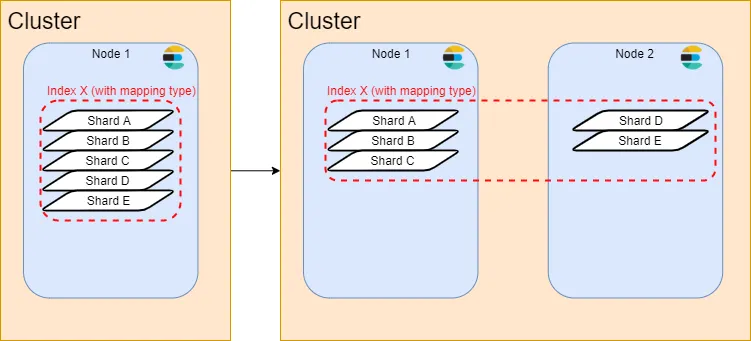
แต่การสร้าง Shard ใน Index นั้นไม่ฟรี หมายความว่ายิ่งปริมาณ Shard ใน Node นึงมีมากเท่าไหร่ มันก็ยิ่งกิน resource เครื่อง เมื่อเราทำการ search เยอะเท่านั้น จึงต้องคิดให้ดีก่อนว่าเราต้องการขยายเครื่องสูงสุดกี่เครื่อง เพื่อ Index นี้ แต่แน่นอนว่าถึงแม้เราจะกำหนดผิดไป Elasticsearch ก็มี Feature ให้เราสามารถสร้าง Index ใหม่แล้วโอนย้ายข้อมูลจาก Index เก่าไปได้ (Reindex) เช่นกัน
ส่วน Replica shard นั้นเป็น Shard ที่ copy ข้อมูลสำรองของ Primary shard จาก Node อื่นไว้ ในกรณีที่ Node นั้นล่ม Replica shard ก็จะทำหน้าที่แทน Primary shard ทำให้เราไม่สูญเสียข้อมูลไปนั่นเอง
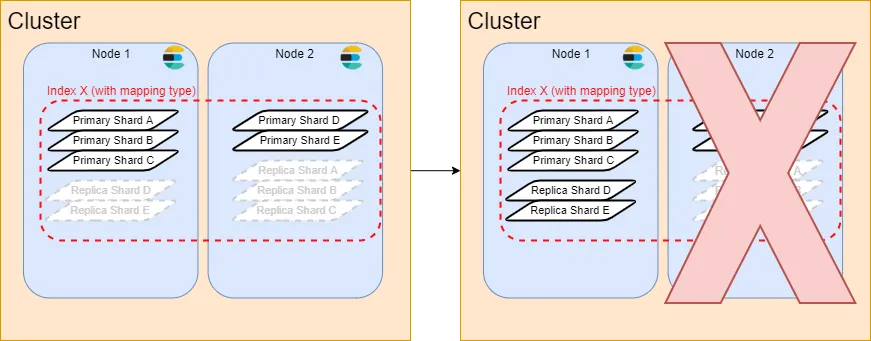
และทั้งหมดนี้ก็คือหลักการทำงานพื้นฐานของ Elasticsearch ที่เพียงพอต่อการเริ่มสร้าง Cluster Elasticsearch ด้วยตัวคุณเองแล้ว
มาลอง Setup Elasticsearch ด้วย Docker กัน
ในส่วนนี้ของบทความ จะเป็นการสาธิตวิธีการติดตั้ง Elasticsearch ซึ่งผมแนะนำว่าให้ลองทำตามไปด้วยเพื่อที่จะได้เข้าใจได้ง่ายขึ้น และเพื่อให้ง่ายต่อการสาธิต ในบทความนี้ ผมจึงใช้ Docker Compose ในการติดตั้ง Elasticsearch ซึ่งหากคุณมีความรู้หรือเคยใช้ Docker มาก่อนก็จะช่วยได้มาก แต่หากไม่รู้จักเลย ก็ยังสามารถทำตามบทความนี้ได้ เพียงแต่คุณจะต้องติดตั้ง Docker และ Docker compose ในเครื่องของคุณเสียก่อน โดยสามารถทำตามขั้นตอนจาก Link ด้านล่างเพื่อติดตั้งได้เลย
เมื่อติดตั้งเสร็จแล้วก็มาเริ่มกันเลย…
เริ่มจากสร้างไฟล์ docker-compose.yml ก่อน โดยมีเนื้อหาไฟล์ดังนี้
ไฟล์ docker-compose.yml ที่เราสร้างนี้ คือทั้งหมดที่เราต้องการในการติดตั้ง Cluster Elasticsearch ที่มีขนาด 2 Node ลงในเครื่องของเรา ซึ่งในความเป็นจริงแล้วแต่ละ Node ไม่ควรจะอยู่เครื่องเดียวกันเพราะมันจะแย่ง Resource ของเครื่องกันเอง แต่เพื่อความสะดวกในการสาธิตจึงขอละไว้ในฐานที่เข้าใจ
ก่อนที่เราจะสั่งรัน Docker compose ด้วย config นี้ เราควรทำความเข้าใจเสียก่อนว่า config นี้หมายความว่าอย่างไรบ้าง ซึ่งถึงแม้ config นี่จะดูยาว แต่จริงๆ ไม่ได้ยากอย่างที่คิด เพราะถ้าเราสังเกตดีๆ จะมีส่วนที่คล้ายกันอยู่ นั่นคือส่วนที่เป็น service ที่ชื่อว่า esnode1 และ esnode2 ซึ่งเป็นการบอกว่าเราจะทำการสร้าง 2 Node และแต่ละ Node จะ config ดังนี้ เพราะฉะนั้นถ้าเราเข้าใจแค่ esnode1 ก็เรียกว่าเข้าใจเกือบทั้ง config นี้แล้ว จึงขออธิบาย config ของ esnode1 ไล่ไปตามหมายเลขดังรูปข้างล่าง

- กำหนดว่า Elasticsearch Node นั้นเป็นเวอร์ชั่นอะไร โดยในตัวอย่างจะเป็นการติดตั้ง Version 7.5.1
- เป็นการกำหนดชื่อของ docker container ที่จะติดตั้ง Elasticsearch Node เอาไว้ ซึ่งถึงแม้จะเป็นชื่ออะไรก็ได้ แต่ก็ควรตั้งเป็นชื่อของ Node เพื่อไม่ให้สับสนภายหลังและเอาไว้ใช้ reference ได้อย่างถูกต้อง
- ชื่อของ Node โดยในที่นี้ ตั้งเป็น esnode1 และ esnode2 ซึ่งเป็นชื่อเดียวกันกับ container_name และแต่ละ Node มีชื่อไม่ซ้ำกัน
- ชื่อของ Elasticsearch Cluster ซึ่งแต่ละ Node ที่อยู่ใต้ Cluster เดียวกันควรจะใช้ชื่อเดียวกัน
- เป็นการบอก Elasticsearch Node ว่าให้ไปหา Elasticsearch Node อื่นๆ ที่ host ไหน โดยจะสังเกตได้ว่าใน config ของ esnode1 จะให้ไปหา esnode2 และกลับกัน esnode2 ก็ไปหา esnode1 ซึ่งจริงๆ แล้วควรใส่ hostname ของ Master Node ทั้งหมดที่มีใน Cluster นี้ และในกรณีนี้ที่ไม่ได้กำหนด port Elasticsearch จะทำการต่อไปที่ port 9300 ให้เอง
- เป็นการกำหนดว่า Node ไหนใน Cluster นี้จะสามารถเป็น Master Node ได้บ้างซึ่ง Master Node ก็คือ Node ที่คอยบริหารจัดการ Node อื่นๆ ใน Cluster เช่น ระบุสถานะของ Node ต่างๆ ว่ายังสุขภาพดีหรือไม่ หรือกำหนดว่า Shard ที่สร้างจะต้องเก็บไว้ที่ Node ไหนเป็นต้น ถึงแม้ตัวมันเองจะเป็น Master Node แล้วแต่ก็ยังใช้งานเป็น Node ที่เก็บ Data ไปพร้อมกันได้เช่นกัน โดยเราสามารถมี Master Node ได้มากกว่า 1 ตัวใน Cluster เผื่อในกรณีที่มี Master ตัวไหนล่มจะได้มีตัวอื่นขึ้นมาทำหน้าที่แทนได้ เหมือนใน config นี้คือทั้ง esnode1 และ 2 สามารถเป็น Master ได้ทั้งคู่
- เป็นการกำหนดให้ Memory ที่ถูกจองโดย Elasticsearch นั้น ไม่ถูก Swap out จากการที่ยังไม่ได้ใช้งานเป็นเวลานาน ทำให้ Elasticsearch ไม่ต้องเสียเวลาดึง Data กลับมาจาก Disk ใหม่อีกรอบซึ่งจะส่งผลต่อ Performance ของ Node ได้ ในส่วนนี้อาจจะไม่เข้าใจก็ไม่เป็นไรแค่ต้องใส่ไว้
- เป็นการกำหนดว่า เริ่มมา Elasticsearch Node นี้จะใช้ Memory เยอะขนาดไหน และได้สูงสุดเท่าไหร่ โดย Xms คือ Memory เริ่มต้น และ Xmx คือ Memory สูงสุด โดยใน config นี้จะใช้งาน Memory เริ่มต้นและสูงสุดเท่ากันคือ 512MB แต่หากเราต้องการเก็บข้อมูลเยอะและ Search ได้เร็วก็ควรเพิ่มค่านี้ขึ้นไปอีกนั่นเอง
- เป็นการบอก Docker ว่าให้ Node นี้สามารถเข้าถึง Memory ได้ไม่จำกัด (เท่าที่เครื่องจะมี)
- เป็นการ Map Directory ที่ Node นี้ใช้เก็บ Data เข้ากับ Volume ของ Docker ซึ่งถ้าไม่กำหนดไว้ ข้อมูลจะหายไปทุกครั้งที่เรา Restart container นี้ จะสังเกตได้ว่า Volume ของทั้งสองอันจะไม่เหมือนกัน คือ esnode1_data และ esnode2_data เพราะแต่ละ Node ก็ต้องมีที่เก็บข้อมูลของตัวเอง
- โดยปกติแล้วถ้าเราสร้างอะไรสักอย่างใน Docker ไว้ เราจะไม่สามารถเข้าถึง port ที่เปิดไว้ข้างในได้ จึงต้องทำการ Forward Port ออกมาก่อนโดย port ที่ใช้เข้าถึง Elasticsearch ก็คือ 9200 และในที่นี้เราก็ให้เชื่อมกับ port 9200 ภายนอก ซึ่งทำแค่กับ esnode1 อันเดียวก็เพียงพอแล้วเนื่องจากเราสามารถเข้าถึง Cluster ผ่านทาง Node ไหนก็ได้
- เป็นการกำหนด Network ของ Elasticsearch ให้ทั้ง esnode1 และ 2 อยู่วงเดียวกัน
ส่วนอื่นๆ ก็ไม่ได้เข้าใจยากแล้ว เนื่องจากเป็นแค่การประกาศชื่อ Network และ Volume ไว้ใช้งานด้านบนนั่นเอง
หลังจากที่เราเข้าใจแล้วก็มาเริ่มรัน Config โดยการเปิด console ไป directory ที่มี docker-compose.yml อยู่ และ run command
docker-compose upหลังจากรอสักพักให้ Elasticsearch เปิดเสร็จแล้ว ให้เราทดสอบว่า Elasticsearch ทำงานได้ไหม โดยการส่ง Get request หรือเปิด Browser ไปที่
หากการติดตั้งเป็นไปได้ด้วยดี คุณจะได้รับข้อความตอบกลับหน้าตาประมาณนี้
{
"name": "esnode1",
"cluster_name": "es-docker-cluster",
"cluster_uuid": "mFSvduweSxizd_UzyuQyuw",
"version": {
"number": "7.5.1",
"build_flavor": "default",
"build_type": "docker",
"build_hash": "3ae9ac9a93c95bd0cdc054951cf95d88e1e18d96",
"build_date": "2019-12-16T22:57:37.835892Z",
"build_snapshot": false,
"lucene_version": "8.3.0",
"minimum_wire_compatibility_version": "6.8.0",
"minimum_index_compatibility_version": "6.0.0-beta1"
},
"tagline": "You Know, for Search"
}ณ ขั้นตอนนี้ คุณสามารถใช้งานคำสั่ง Elasticsearch ได้ทั้งหมดแล้ว โดยให้ลองเข้าไปที่
จะพบกับรายการคำสั่งพื้นฐานของ Elasticsearch เช่น การแสดง Node ทั้งหมดใน Cluster เพื่อยื่นยันว่า Node ทั้งหมดเชื่อมต่อกันถูกต้อง โดยไปที่
http://localhost:9200/_cat/nodes?v
ถ้าหากคุณพบกับข้อความตอบกลับประมาณนี้

ยินดีด้วยตอนนี้คุณติดตั้ง Cluster Elasticsearch จำนวน 2 Node ในเครื่องของคุณสำเร็จแล้ว
วิธีสร้าง Index แรกของคุณ
อย่างที่ได้กล่าวไปก่อนหน้านี้ว่า Keyword สำคัญของ Elasticsearch มี 4 คำ ในตอนนี้เราได้จัดการกับ Cluster และ Node ไปแล้ว ในช่วงนี้ของบทความเราจะได้เริ่มลงมือสร้าง 2 ส่วนสุดท้ายกันซึ่งคือ Index และ Shard
ในการที่จะสร้าง Index นั้นสามารถทำได้โดยการส่ง PUT Request ไปที่ Elasticsearch โดยใช้ Path เป็นชื่อ Index ที่ต้องการ พร้อมกับ Request body ที่เป็น config ของ Index ซึ่งจะมีส่วนที่สำคัญดังนี้
PUT http://localhost:9200/INDEX_NAME{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 2
}
},
"mappings": {
"properties": {
"field1": {
"type": "text|keyword|integer|double..."
}
}
}
}
เริ่มจาก settings ของ index มี 2 ส่วนสำคัญคือ
number_of_shards คือจำนวน Primary shard ทั้งหมดของ Index นี้ อย่างที่ได้กล่าวไว้ก่อนหน้านี้ว่าเป็นส่วนที่กำหนดว่าเราสามารถให้ Index นี้ขยายไปได้มากที่สุดในกี่ Node จึงควรกำหนดไว้เผื่อในอนาคตมีการขยาย Cluster เพิ่มเติม แต่ก็ต้องไม่มากจนเกินไป เพราะอาจจะเป็นการแย่ง Resource ใน Node เดียวกันเองได้
ค่า number_of_shards นี้ไม่สามารถแก้ไขหลังจากสร้าง Index ไปแล้วได้ ยกเว้นว่าจะทำการ reindexใหม่
number_of_replicas คือจำนวน Replica ของ Index นี้ ซึ่งจำนวน Replica shard ที่ได้ จะสัมพันธ์กับจำนวน Primary shard เช่น หาก Index นี้มี Primary shard ทั้งหมด 3 shards แล้วเรากำหนด number_of_replicas เป็น 2 ก็จะเกิด Replica shard ทั้งหมด 6 shards นั่นเอง โดยค่าสูงสุดของ number_of_replicas นั้นไม่ควรเกิน จำนวน Node-1 เพราะจะทำให้ Replica shards ส่วนเกินมากองรวมกันใน Node นึง ส่งผลให้ Health Check ของ Elasticsearch เป็น Yellow (มีปัญหา) ได้
จำนวน number_of_replicas สามารถเปลี่ยนภายหลังจากที่สร้าง Index ไปแล้วได้
ในส่วนของ mappings นั้น เอาไว้ใช้กำหนด type ของแต่ละ field ในข้อมูลที่เราจะเก็บ ซึ่งจริงๆ เราจะไม่ใส่ไปเลยก็ได้ เพราะ Elasticsearch สามารถใช้งานแบบ Schemaless ได้ หรือจะใส่ไปแค่บาง field ก็ได้ซึ่งถ้าเกิดมี Field ใหม่เข้ามานอกเหนือจากที่กำหนดไว้ Elasticsearch ก็จะทำการเลือก type ให้เอง
ในขั้นตอนนี้เราจึงทดลองสร้าง Index โดยกำหนดแค่ number_of_shards และ number_of_replicas ไปแค่นี้ก่อน
PUT http://localhost:9200/my_index_1{
"settings": {
"index": {
"number_of_shards": 3,
"number_of_replicas": 1
}
}
}
หลังจากนั้นทดสอบว่า Index เราสร้างสำเร็จหรือไม่ โดยการเข้าไปที่ http://localhost:9200/my_index_1 แล้วเราจะเห็น Settings ของ Index ที่เราสร้างเช่นนี้
{
"my_index_1": {
"aliases": {},
"mappings": {},
"settings": {
"index": {
"creation_date": "1577175027439",
"number_of_shards": "3",
"number_of_replicas": "1",
"uuid": "84DScbOUQ6CtQlG2baBQMA",
"version": {
"created": "7050199"
},
"provided_name": "my_index_1"
}
}
}
}และเรายังสามารถเช็คดูได้ว่า Shard ของเรากระจายตัวอยู่ที่ Node ไหนบ้าง โดยการไปที่ http://localhost:9200/_cat/shards?v ซึ่งจะเห็นข้อมูลตอบกลับมาลักษณะแบบนี้

ซึ่งนำมาแสดงเป็นภาพได้แบบนี้

ถึงตรงนี้อาจจะสังเกตได้ว่าชื่อ Index คือ my_index_1 ซึ่งจริงๆ แล้วเราต้องการตั้งชื่อเป็น my_index (ไม่มี _1) แต่ที่เราสร้าง Index แบบนี้เพราะจริงๆ ในอนาคตเราอาจจะต้องการสร้าง Index อื่นมาใช้แทน หรือ reindex ใหม่ จึงควรสร้าง Index ด้วยชื่ออื่นแล้วค่อยสร้าง Alias เป็นชื่อที่เราต้องการชี้ไปที่ Index นั้น ทำได้โดยการส่ง Request
POST http://localhost:9200/_aliases
{
"actions" : [
{ "add" : { "index" : "my_index_1", "alias" : "my_index" } }
]
}ซึ่งทำให้เราสามารถใช้ชื่อ my_index แทนได้ โดยให้เราทดสอบด้วยการไปที่
http://localhost:9200/my_index
ก็จะเห็นผลลัพธ์แบบเดียวกันกับ
http://localhost:9200/my_index_1
หลังจากที่เราสร้าง Index แล้วก็ถึงเวลาที่จะเริ่มใส่ Data เข้าไปใน Index โดยวิธีการนั้น ให้เราส่ง Put Request ที่มี Body เป็น JSON ของข้อมูลที่เราต้องการ ซึ่งสรุปออกมาได้ดังนี้
POST http://localhost:9200/my_index/_doc
{
"KEY1" : "VALUE1"
}ให้เราลองใส่ข้อมูลโดยส่ง Request ตามนี้
POST http://localhost:9200/my_index/_doc
{
"user" : "tester",
"age" : 28,
"post_date" : "2019-11-25T06:30:35",
"message" : "ทดสอบใส่ข้อมูลลงไปใน Elasticsearch"
}ถ้าหากข้อมูลเข้าไปอย่างถูกต้องแล้ว เราจะสามารถ search ดูได้จากทาง Link นี้ http://localhost:9200/my_index/_search ได้ผลลัพธ์ตามตัวอย่างนี้

ซึ่งจริงๆ แล้วเราก็สามารถแก้ไขข้อมูลเดิมได้โดยการระบุ ID จาก field _id ก่อนส่ง JSON Body เข้าไปได้เช่นกัน
POST http://localhost:9200/my_index/_doc/DOC_ID
{
"user" : "realuser",
"age" : 12,
"post_date" : "2019-11-25T06:30:35",
"message" : "ทดสอบใส่ข้อมูลลงไปใน Elasticsearch"
}และหากต้องการที่จะลบข้อมูลออก ก็แค่เปลี่ยนจาก POST เป็น DELETE โดยที่ไม่ต้องส่ง JSON Body เข้าไป
DELETE http://localhost:9200/my_index/_doc/DOC_IDให้ลองใส่ข้อมูลทิ้งไว้สัก record นึง หากข้อมูลแสดงขึ้นมาอย่างถูกต้องแล้ว ให้เราลองกลับไปดู Settings ของ Index อีกครั้งที่ http://localhost:9200/my_index จะพบว่ามีรายชื่อ Field ที่เราใส่ข้อมูลเข้าไปแล้วแสดงขึ้นมาดังนี้

จะสังเกตได้ว่า แม้เราไม่ได้กำหนด type ไว้ก่อน แต่ Elasticsearch ก็สามารถ map type ให้เองได้อัตโนมัติ และผลลัพธ์ก็ค่อนข้างตรงไปตรงมา เช่น age เป็น long และ post_date เป็น date แต่จะมีเพียง message และ user ที่มี 2 type นั่นคือ text และ keyword ซึ่งจริงๆแล้ว string ใน Elasticsearch นั้นสามารถเก็บเป็น text หรือ keyword ก็ได้ ความต่างจะอยู่ที่ type text สามารถทำให้เรา search แบบ full text บน field นั้นได้แต่ keyword ไม่สามารถทำได้
Elasticserach เลยใส่มาทั้งสอง type ให้เราไปเลือกใช้เอง โดย type ปกติของ field message จะเป็น text และหากอยากใช้ keyword ก็สามารถเรียกใช้ได้ผ่าน field message.keyword
Type ที่ถูกกำหนดไปแล้วจะไม่สามารถเปลี่ยนภายหลังได้หากไม่ reindex ก่อน
เพื่อให้เห็นภาพชัดเจนขึ้น ผมจะทำการสาธิตโดยการ search จาก field message ที่เป็น type text ด้วยคำว่า “elasticsearch” โดยการเข้าไปที่ Link นี้
http://localhost:9200/my_index/_search?q=message:elasticsearch

จะเห็นว่าเจอข้อมูลที่เราใส่ไว้ แต่ถ้า search จาก type keyword โดยเข้าไปที่ Link นี้
http://localhost:9200/my_index/_search?q=message.keyword:elasticsearch

จะไม่เจอข้อมูลของเรา เพราะการ search ด้วยบางส่วนของข้อความนั้น เป็นการใช้ full text search นั่นเอง ถ้าหากต้องการ search ด้วย keyword ให้เจอก็จำเป็นต้องใส่ข้อความทั้งหมดแบบนี้
http://localhost:9200/my_index/_search?q=message.keyword:ทดสอบใส่ข้อมูลลงไปใน Elasticsearch
มาถึงตรงนี้หากเราต้องการใช้งานแค่ภาษาอังกฤษก็คงจะไม่มีปัญหาอะไร แต่เชื่อว่าหลายคนก็คงอยากเก็บข้อมูลภาษาไทยด้วย อย่างเช่นในตัวอย่างก็มีการใส่ข้อมูลที่เป็นภาษาไทยไว้ ซึ่งหากเราลอง search แบบ full text โดยใช้ภาษาไทยแบบนี้
http://localhost:9200/my_index/_search?q=message:ทดสอบ
ก็จะพบว่าเราไม่สามารถ search โดยใช้ภาษาไทยบางส่วนได้ ที่เป็นแบบนี้ เนื่องมาจากว่าปกติแล้ว field ที่เป็น type text จะมีการ process ข้อความด้วยสิ่งที่เรียกว่า Analyzer เพื่อเตรียมข้อมูลเก็บไว้หลังบ้านก่อนจะนำไปใช้ search จริงในภายหลัง การ process ที่ว่าก็เช่น ตัดคำ, ตัด Stop word, เปลี่ยนเป็น lowercase ซึ่งโดย Default แล้ว การตัดคำปกติของ Elasticsearch จะไม่รองรับภาษาไทย นั่นคือจะตัดแค่จาก space เพราะฉะนั้นเราจะสามารถ search แบบแบ่งตาม space เช่นนี้ได้
http://localhost:9200/my_index/_search?q=message:ทดสอบใส่ข้อมูลลงไปใน
แต่ไม่สามารถ search บางคำของข้อความภาษาไทยได้ ถ้าหากเราต้องการจะ search ภาษาไทยจริงๆ ก็จำเป็นที่จะต้องกำหนด Analyzer ใน field นั้นๆ ไว้ก่อน แต่ ณ ตอนนี้ field message ของเราถูก Index ไปแล้วว่าเป็น type text ที่ใช้ default analyzer ของ Elasticsearch การที่เราจะแก้ไขได้นั้น จึงจำเป็นที่จะต้อง Reindex เสียก่อน
Reindex นั้นถึงจะบอกว่าเป็นการแก้ไข Index แต่จริงๆ แล้วมันเป็นการให้เราไปสร้าง Index ใหม่ไว้ก่อน แล้วค่อย Copy ข้อมูลจาก Index เก่าของเราไปใส่ให้มากกว่า เพราะฉะนั้นเราต้องเริ่มจากการสร้าง Index ใหม่ชื่อ my_index_2 เสียก่อน ซึ่งก็ทำเหมือนครั้งแรก แต่ว่าครั้งนี้เราจะเพิ่ม Config ส่วน analyzer และ mappings เข้าไปด้วยตามนี้
PUT http://localhost:9200/my_index_2{
"settings": {
"index": {
"number_of_shards": "3",
"number_of_replicas": "1",
"analysis": {
"analyzer": {
"thai": {
"filter": [
"lowercase"
],
"tokenizer": "thai"
}
}
}
}
},
"mappings": {
"properties": {
"message": {
"type": "text",
"analyzer": "thai"
},
"user": {
"type": "text",
"analyzer": "thai",
"fields": {
"keyword": {
"type": "keyword",
"ignore_above": 256
}
}
}
}
}
}
ส่วนที่น่าสนใจใน Config นี้คือ เราได้เพิ่ม Custom Analyzer ของเราเข้าไปใหม่ที่มีชื่อว่า thai โดยเราได้กำหนดว่า Analyzer นี้จะ process ข้อความก่อน โดยการปรับข้อความเป็น lowercase และตัดคำด้วย Tokenizer ภาษาไทยของ Elasticsearch เอง นอกจากนี้ยังระบุว่าให้ใช้ Analyzer นั้นกับ field message และ user อีกด้วย แต่อาจจะต่างไปหน่อยตรงที่ครั้งนี้เรากำหนดให้ message มีแค่ type text เพราะเราคงไม่ได้ search message โดยใช้ type keyword เท่าไหร่ จึงดีกว่าถ้าเราช่วยประหยัด Resource ของเครื่องโดยการไม่กำหนดให้มันเป็น type keyword ไปด้วย
หลังจากที่ได้ Index ใหม่แล้ว เราก็สามารถใช้การ Reindex Copy ข้อมูลจาก my_index_1 มาใส่ได้ โดยการส่ง Request แบบนี้
PUT http://localhost:9200/_reindex{
"source": {
"index": "my_index_1"
},
"dest": {
"index": "my_index_2"
}
}
ให้ลองเข้าไปเช็คดูว่า my_index_2 ของเรามีข้อมูลเข้ามาครบแล้วหรือยัง ผ่านทาง
http://localhost:9200/my_index_2
ถ้าข้อมูลขึ้นมาครบแล้วก็เริ่มการเปลี่ยน Alias ของ my_index มาชี้ที่ my_index_2 ได้ โดยส่ง Request ให้ลบ Alias เก่าและเพิ่ม Alias ใหม่เข้าไปแบบนี้
POST http://localhost:9200/_aliases
{
"actions": [
{
"remove": {
"index": "my_index_1",
"alias": "my_index"
}
},
{
"add": {
"index": "my_index_2",
"alias": "my_index"
}
}
]
}ทีนี้หากเราลอง query โดยใช้บางส่วนของข้อความภาษาไทยอีกครั้ง ก็จะพบว่าผลลัพธ์ขึ้นมาแล้วอย่างถูกต้อง
http://localhost:9200/my_index/_search?q=message:ทดสอบ

หลังจากที่ทดสอบแล้วว่า index ใหม่ของเราทำงานอย่างถูกต้อง ก็ค่อยกลับไปลบ my_index_1 ที่ไม่ได้ใช้แล้วออกไปโดยการส่ง Delete Request ไปที่ url ของ Index ที่ต้องการลบ
DELETE http://localhost:9200/my_index_1เท่านี้เราก็เข้าใจวิธีสร้างและ config index ขั้นพื้นฐาน ซึ่งเพียงพอต่อการเริ่มนำไปเก็บข้อมูลได้แล้ว
เริ่มต้นการ Search แบบง่ายๆ
จริงๆ แล้วเราสามารถ Search ได้สองวิธีหลักๆ นั่นคือ
- Search โดยใช้ url ผ่าน GET Request
- Search โดยใช้ Request Body ผ่าน GET/POST Request
แต่ในบทความนี้จะอธิบายแค่การ Search แบบแรกเท่านั้น ซึ่งการ Search แบบนี้ เราพบเห็นบ้างแล้วในส่วนที่ผ่านมาของบทความ โดยในส่วนนี้เราจะใช้ Index my_index เพื่อสาธิตการ Search เพิ่มเติมแต่ก่อนหน้านั้นเราจะใส่ข้อมูลเพิ่มเข้าไปใน Index ที่ว่าก่อนโดยมีการส่งข้อมูลเข้าไปทีละหลายๆ record โดยใช้ Request นี้
POST http://localhost:9200/my_index/_bulkพร้อมกับ Request Body ดังนี้
พอข้อมูลเข้าไปแล้ว ก็มาเริ่มการ Search ได้เลย โดย Syntax มีดังนี้
GET http://localhost:9200/my_index/_search?q=QUERY_STRINGส่วน QUERY_STRING นั้นเราสามารถใส่เป็นคำค้นที่เราต้องการได้เลย เช่น
http://localhost:9200/my_index/_search?q=elasticsearch jane

Elasticsearch ก็จะทำการค้นหาจากหลายๆ field แล้วนำ record ที่ใกล้เคียงสุดมาจัดเรียงตาม _score ที่เป็นค่าที่บอกความใกล้เคียงกับการ search มาแสดงให้เราเห็น ซึ่งโดยปกติเราจะเห็นสูงสุด 10 records แต่ถ้าเราต้องการเห็นมากขึ้นหรือน้อยลงก็สามารถใส่ size และ from เพื่อทำ pagination เพิ่มเติมได้ เช่น เราอยากเห็น page ละ 2 record และอยากข้าม page แรกไปก็ทำได้เช่นนี้
http://localhost:9200/my_index/_search?q=elasticsearch jane&size=2&from=3

แต่ถ้าเราต้องการ search แบบระบุ field เลยก็สามารถทำได้โดยการใส่ query string เป็นชื่อของ field และค่าของ field ที่คั่นด้วย colon(:) สามารถใส่ AND, OR และ วงเล็บครอบได้เหมือนสมการคณิตศาสตร์
((FIELD_NAME:FIELD_VALUE AND FIELD_NAME:FIELD_VALUE) OR FIELD_NAME:FIELD_VALUE)เช่น ถ้าเราต้องการคนที่อายุ 22 และมี message ว่า elasticsearch ก็สามารถหาได้แบบนี้
http://localhost:9200/my_index/_search?q=message:elasticsearch AND age:22

หรือถ้าเราอยากเพิ่มคนที่อายุ 19 เข้าไปด้วยก็สามารถทำได้แบบนี้
http://localhost:9200/my_index/_search?q=(message:elasticsearch AND age:22) OR age:19

และถ้าเราอยากกลับด้านการ search ของเรา (NOT) ก็สามารถทำได้โดยการใส่เครื่องหมายลบ (-)
http://localhost:9200/my_index/_search?q=-((message:elasticsearch AND age:22) OR age:19)
เท่านี้ก็จะได้ผลลัพธ์ตรงกันข้ามกับการ search ก่อนหน้านี้แล้ว
นอกจากนี้เรายังสามารถ Search เป็นช่วงได้อีกด้วย โดยใช้ Syntax แบบนี้
ค้นหาตั้งแต่ START_VALUE ถึง END_VALUE
FIELD_NAME:[START_VALUE TO END_VALUE] ค้นหาตั้งสิ่งที่มากกว่า START_VALUE แต่น้อยกว่า END_VALUE
FIELD_NAME:{START_VALUE TO END_VALUE}ค้นหาตั้งแต่ START_VALUE ขึ้นไป
FIELD_NAME:[START_VALUE TO *]ค้นหาค่าที่น้อยกว่า END_VALUE ลงมา
FIELD_NAME:{* TO END_VALUE}
ตัวอย่างเช่นถ้าเราต้องการหาข้อมูลที่เก่ากว่าปี 2019
http://localhost:9200/my_index/_search?q=post_date:[* TO 2019-01-01}

และท้ายที่สุดถ้าหากเราอยากได้ผลลัพธ์เรียงตาม field ไหนสัก field ก็สามารถทำได้โดยการกำหนด parameter sort ซึ่งมี syntax ดังนี้
GET http://localhost:9200/my_index/_search?sort=FIELD_NAME:DIRECTIONโดย DIRECTION คือ asc (น้อยไปมาก) หรือ desc (มากไปน้อย)
เช่น ถ้าเราอยากให้ข้อมูลเรียงจากอายุมากไปน้อยก็ทำได้เช่นนี้
http://localhost:9200/my_index/_search?sort=age:desc

ยินดีด้วยเท่านี้คุณก็สามารถใช้งานการ Search ใน Elasticsearch ขั้นพื้นฐานทั้งหมดได้แล้ว ที่เหลือก็ขึ้นอยู่กับผู้ใช้ว่าต้องการจะ Search อะไรและนำ query ไหนมาผสมกันได้บ้าง การได้ลอง Search หลายๆ แบบในข้อมูลหลายๆ ประเภท ก็จะช่วยให้เราเกิดความชำนาญในท้ายที่สุดนั่นเอง
ถ้าหากคุณอ่านมาถึงตอนนี้ก็น่าจะเข้าใจได้ว่าจริงๆ แล้ว Elasticsearch ไม่ได้ยากอย่างที่คิด เพราะแค่เราทำความเข้าใจกับ Keyword สำคัญ คือ Cluster, Node, Index และ Shard ได้ ก็เพียงพอต่อการใช้งาน Elasticserach ในการเก็บข้อมูลจริงๆ อย่างที่เราต้องการได้แล้ว อีกทั้งการ Search ใน Elasticsearch นั้นก็ไม่ได้ยากจนเกินไป เราสามารถ Search ด้วยคำค้นที่เราต้องการไปเลย หรือจะระบุ Field อย่างละเอียดก็สามารถทำได้โดยง่ายเช่นกัน
แต่ทั้งนี้ Elasticserach ก็ไม่ใช่ Database หรือ Search Engine ที่ดีที่สุด ถ้าถามว่าอะไรคือสิ่งที่ดีที่สุดคำตอบก็คือ “ไม่มีสิ่งที่ดีที่สุด” แต่คำถามที่มีคำตอบ คงเป็นว่า อะไรคือสิ่งที่ “เหมาะสมที่สุด” ซึ่งคำตอบก็ขึ้นอยู่กับงานและประเภทของข้อมูลของเรา เพราะผู้เขียนเชื่อว่าทุกสิ่งที่ถูกสร้างมาย่อมมี Use case ที่เหมาะและไม่เหมาะกับมันนั่นเอง
ถึงแม้บทความนี้จะเพียงพอต่อการทำให้ Developer ที่ไม่รู้จัก Elasticsearch มาก่อนเลยสามารถเริ่มติดตั้งจนไปถึงเริ่มใช้งาน Elasticsearch ได้ แต่ทั้งหมดนี้ก็เป็นเพียงพื้นฐานของ Feature ใน Elasticsearch ซึ่งจริงๆ แล้ว ยังมี Feature ที่ดีและน่าสนใจอีกมากไม่ว่าจะเป็นการ Aggregate เพื่อนำข้อมูลไปสร้างเป็น Chart การเขียน Script เพื่อ Manipulate ข้อมูลของเรา หรือการใช้งาน Machine Learning ของ Elasticsearch และอื่นๆ อีกมากมาย ที่ไม่ได้กล่าวไว้ในบทความนี้ ถ้าหากสนใจก็สามารถตามไปอ่านเพิ่มเติมได้ที่
หากบทความนี้มีข้อผิดพลาดประการใดก็ขออภัยไว้ ณ ที่นี้ด้วย ถ้ามีโอกาสหน้าอาจจะได้เขียนเรื่องการ Aggregate ของ Elasticsearch เพิ่มเติม แล้วพบกันใหม่
ขอบคุณครับที่อ่านจนจบ

