Exploratory Analysis of Player Performance in the NBA: Who Should Get More Playing Time?
Kiran Pillai
INST414: Data Science Techniques

Introduction
In the NBA, effective allocation of player minutes can significantly influence a team’s success. Coaches often face the challenge of balancing star player workloads with the contributions of role players who may be hidden gems. This analysis answers the question:
Which NBA players are underutilized based on their per-minute performance metrics, and which deserve more playing time?
Stakeholder and Decision-Making
The primary stakeholders are NBA coaches, front-office analysts, and fantasy basketball managers. For coaches and analysts, identifying players who excel in limited minutes can inform decisions about rotation changes and minute allocations — improving overall team performance. Fantasy basketball managers can discover potential sleeper picks whose impact may increase if their playing time expands.
Data Source and Collection Process
The data was sourced from Kaggle: NBA Players Stats. This dataset includes per-game stats (points, rebounds, assists, etc.) and advanced metrics (Win Shares, Player Efficiency Rating). Relevant fields:
- Player: Player name.
- MP (Minutes Played per Game): Average playing time per game.
- PTS (Points per Game): Scoring output.
- AST (Assists per Game): Passing contributions.
- TRB (Total Rebounds per Game): Rebounding contributions.
The dataset was scraped and downloaded using Python’s BeautifulSoup library. The scraping process and scripts are available in my GitHub repository (NBA-data-PT).
Data Source and Collection Process
I obtained the dataset from Kaggle by downloading the CSV file directly from the “NBA Players Stats” dataset page. After downloading, I placed the file (nba_player_stats_2023.csv) into my project directory. Using Python’s pandas library, I loaded the dataset and prepared it for analysis. This approach ensures that the data is consistent, reliable, and easy to reproduce by anyone with access to the Kaggle link.
Data Cleaning and Common Issues
Before analysis, it was necessary to clean the data. I implemented a data cleaning script (data_cleaning.py) to:
- Remove rows with missing critical stats like MP, PTS, AST, and TRB.
- Convert columns to appropriate numeric types.
- Filter out players with extremely low minutes (e.g., fewer than 5 minutes per game) to avoid misleading per-minute metrics from tiny samples.
Common issues included missing values for players who barely played and inconsistent data types. I handled these by dropping incomplete rows and using pandas.to_numeric() to ensure numeric columns were correctly formatted.
The cleaning script (data_cleaning.py) is also included in my GitHub repository.
Exploratory Data Analysis (EDA)
To understand which players might be underutilized, I began by examining the relationship between playing time and scoring output. For instance, a scatter plot of Minutes Played (MP) vs. Points Per Game (PTS) can reveal players who are scoring efficiently even in fewer minutes.

From this plot, some players stand out as having high points per game despite playing fewer minutes. Notably, players such as Malik Monk and Immanuel Quickley appear to score efficiently in limited minutes, outperforming others with similar or greater playing time. This suggests that these players could contribute significantly more if granted additional playing time. The clustering in the middle of the plot indicates that most players perform near their expected scoring averages based on minutes played, but the outliers warrant further exploration as potential hidden gems for coaches and analysts.
Table Summary Findings
Beyond the initial scatter plot, I conducted a regression analysis to predict expected Points Per Game (PTS) based on Minutes Played per Game (MP). By comparing actual PTS to predicted PTS, I identified players whose actual scoring output significantly exceeds expectations. These players are flagged as “underutilized,” meaning they perform more efficiently on a per-minute basis than predicted by the model.
The table below highlights the top five underutilized players, as identified through this analysis:
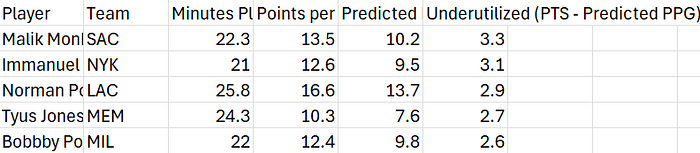
These players demonstrate actual point production that surpasses their predicted output based on their limited minutes. This finding suggests they may be underutilized within their current team roles. Increasing their playing time could potentially enhance overall team performance, a consideration for coaches and front-office analysts aiming to optimize rotations.
Limitations and Biases
Several limitations must be acknowledged:
- Per-Minute Stats Assumption: Players who excel in short bursts might not sustain their efficiency if given more minutes due to fatigue, defensive adjustments by opponents, or changes in their role.
- Contextual Factors: The data does not consider matchups, team strategies, or the quality of teammates and opponents. A player’s efficiency may be inflated by playing against second-string defenses.
- Lack of Defensive Metrics: Defensive impact is harder to quantify with basic stats. A player contributing modest offense but elite defense may not appear underutilized by this analysis.
- Season and Sample Size Variations: Data from a single season or short spans may not paint a complete picture of a player’s true capability.
GitHub Repository
By examining per-minute efficiency and predicted versus actual performance metrics, we identify players who appear underutilized. Coaches and analysts can consider granting these players more minutes, potentially enhancing their team’s performance. Fantasy basketball managers can monitor these players as potential breakout candidates.
For complete reproducibility, the code for this analysis, including data cleaning, EDA, and the table generation of underutilized players, is available in my GitHub repository.
