Shunt Connection for Speeding up Deep Neural Network
In order to automate drones for taking the decisions without human interactions, it should be embedded with the capability of “On-Device AI”. This concept helps the machines to take a decision during the run time on the basis of its previously done training. There are several machine learning algorithms which give training with optimized loss values. With the evolution of deep learning-based neural network models, it has become very efficient to perform training and learn from visual, textual, time-series data and serve the application.
The problem arises when the application is real-time (time-critical) by nature. For instance, if the application has to (a) Give ease to the user in their general-purpose work, like recommendation during online shopping, categorizing the image after capturing through the camera. (b) In defense, for identifying and categorizing the war tanks/ vehicles present in enemy territory by a fast-flying aerial drone. (c) In forest lives, for monitoring the animals in the forest by an aerial drone identifying and monitoring their health and presence, etc. These all applications desire for the neural network with the fast inference. Hence, this work targets for speeding up the inference and uses the fastest neural network (MobileNetV2) and reduces up to 40% of its total floating-point operations consequently giving direct speedup with no loss in performance.
The proposed method
The method introduces a new connection for skipping the computationally expensive blocks.
Shunt connection:

In order to compact the knowledge stored in vulnerable blocks (blocks with lesser knowledge quotient) of a given network, a new network is trained that should have parameters fewer than the parameters of vulnerable blocks which implies a fast response

time. This new network is supposed to learn the knowledge stored among vulnerable blocks by avoiding the redundancy and optimizing the sparsity. The newly trained network is location-dependent and needs to be trained for optimizing the knowledge between two particular locations in the network. The connection, which is used between two points of the network to serve the responsibility of imposing lesser computations imitates the shunting behavior of electric circuits. In circuits, shunting is used to facilitate by the lower impedance path in order to divert the route of the current. Logically, shunt connection is the combination of encoder and decoder, where input size to the encoder may not be same as output size of decoder, hence it slightly differs from the conventional encoder-decoder combination which aspires to maintain uniformity between input and output.

This subsection explains the proposed concept in five phases and three algorithms, Where Algorithm 1 depicts the main function and Algorithm 2, Algorithm 3 describes the way of locating vulnerable blocks and stacking the feature maps respectively.
Phase-A This phase is more like a prerequisite to the main idea of the work and supplies the trained basic model to the successive phase. The available dataset which is already segregated among training, validation and testing sets is exposed to the prescribed deep network (MobileNet-V2). The network is supposed to leverage all the hyperparameters as per standard so that the model should be able to reach the attainable global minima on validation data in affordable time on a particular experimental setup. The care taken at training should help the model to achieve the best generalization performance.
Phase-B This phase takes the pre-trained model as input from the previous step (Phase-A). It aims at locating the most vulnerable consecutive blocks of the given network, Fig. 2 represents the case where kth block is found as block with least knowledge quotient and (k − 1)th, kth, (k + 1)th blocks are selected as a set of blocks to be removed and termed here as vulnerable blocks. The term vulnerable is used here to refer the blocks which are contributing with least knowledge to the network. In order to identify the knowledge index of each block, an elimination procedure is followed. The procedure is based on the concept taken from the study of Veit et al. (2016), which claims that the effective depth of the network, measured at inferencing is found to be smaller than the original depth. Therefore, removal of a few blocks results in only a modest drop on the generalization accuracy. Based on the aforementioned idea this phase eliminates each block one at a time and rewires the connection to the next by jumping the current. The block which makes a relatively huge drop in accuracy is supposed to have high knowledge quotient and minute drop corresponds to least knowledge quotient. This method helps in giving insight about which blocks to jump while using Shunt connection.
Phase-C This phase takes the pre-trained network (from Phase-A), vulnerable locations (from Phase-B) and Training+Testing data including corresponding labels as inputs. The objective of the phase is to process input data and to collect stacks of corresponding feature maps before (FM 1 ) and after (FM 2 ) vulnerable blocks.
Phase-D The stacked feature maps (FM 1, FM 2 ) collected from the previous phase are leveraged to train a new network, which is a function of lesser computation complexity in comparison to skipped blocks. In order to serve the purpose, all the spatial dimensions of FM 1 and FM 2 are kept identical and are exploited as input and output of additionally incorporated tiny network of Encoder-Decoder type. The training of the network can be seen in ∧ Fig. 1. The introduced tiny network is trained using the standard backpropagation algorithm on given stacked feature maps FM 1 and FM 2 and builds a model termed as M_sh.

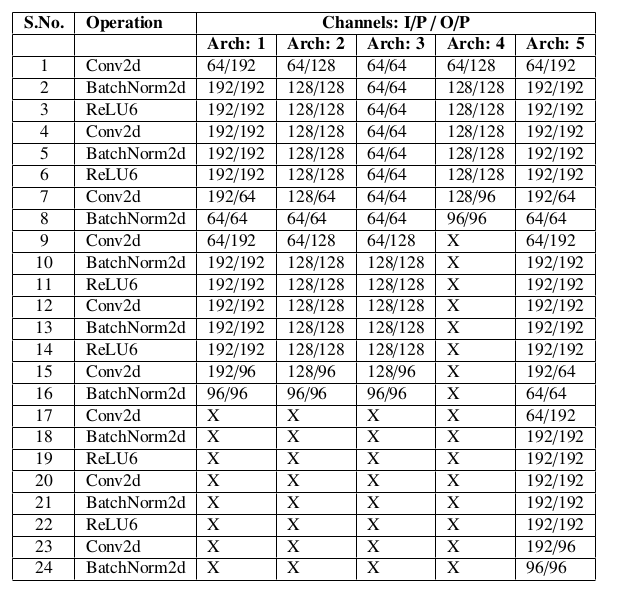
Training the connection:
Shunt connection is required to be trained. It takes feature maps from both the vulnerable locations corresponding to each input image and plugs-in to the connection for learning. If the sequential operations of the network generate ‘F’ number of feature maps while reaching the desired shunting locations then the input data volume for the shunt connection will be ‘F’ times number of input images to the main network. Shunt connection is actually a derivative of Encoder-Decoder with specified layers (Table 1, Fig. 4), where input values and output values corresponding to each layer represented in Fig. 4are the number of channels with respect to input feature maps and output feature map respectively. Shunt connection adjusts its parameters for mapping input feature maps to output feature maps (feature maps before and after the vulnerable blocks). In order to provide similar results as that of vulnerable blocks, this work uses a tiny convolution neural network as a basic unit of the encoder-decoder system. This system takes feature maps generated while entering the first vulnerable block of the main network as input and feature maps generated while exiting the last vulnerable block as output. In this work, Adam optimizer is used for reducing the mapping loss and training the weights.
Phase-E This phase takes original trained model M 1 from Phase- A and a tiny encoder-decoder model M sh from Phase-D as inputs and rewires both the models in a way to provide a new network M 2. This upgraded hybrid model is a compressed model which provides a faster response with a modest deviation in accuracy.
Results

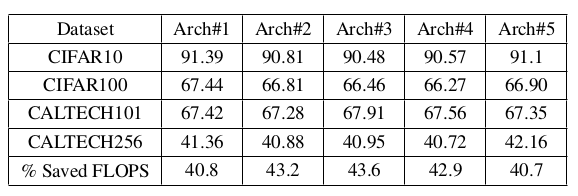
The proposed method is developed to reduce the floating-point operations of deep learning architecture. It includes the light-weighted combination of encoder-decoder (referred to as shunt connection) which is expected to have the knowledge same as of vulnerable blocks. The proposed method is fed with the pre-trained network prepared for a particular dataset.
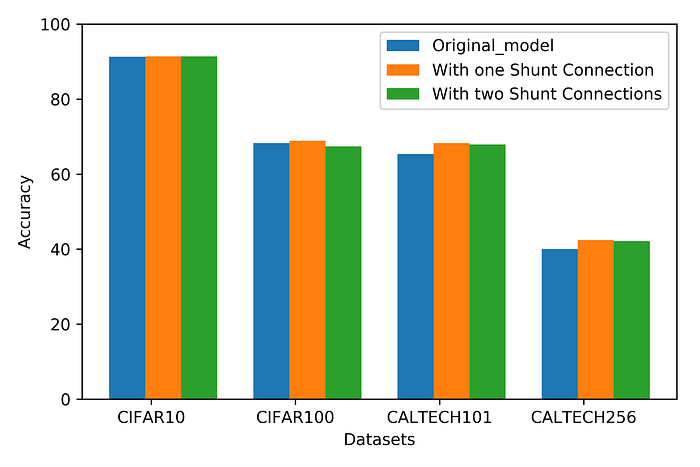
This work showcases two scenarios of having one shunt connection and having two shunt connections in the same network. The results from Table 2 show the performance of the single shunt connection over various datasets. It shows the working of a shunt connection against 6 contiguous blocks on MobileNet-V2 architecture for optimizing its floating-point operations up to 33.5% and its impact on the network performance. Whereas the performance of double Shunt connection can be witnessed from Table 3 which shows up to 43.6% reduction in floating-point operations. It is quite evident through experiments that removing the intermediate blocks from the pre-trained network does not mark much negative impression on accuracy and, it draws the interesting conclusion. This observation gets backed up by the working of residual connections, which help in training by skipping the intermediate blocks. Based on this observed insight a connection is tested on various datasets with the varying number of classes ranging from 10 to 257 and shown a competitive accuracy-regain with the optimized architecture. This regains in accuracy conceptualizes the idea of compressing the knowledge of multiple blocks in fewer blocks. Table 2 shows the detail of saved computations with the proposed method where it is conspicuous to adhere the operations with MACC (Multiplication and Accumulate) which is supposed to be the main convict of time complexity. The saving of computations mainly depends on the type and quantity of blocks to be removed. Since the idea is based on compressing the knowledge, therefore, additional compression will lead to high biases in the system hence, the decision of how many blocks should be removed is to be taken by keeping track of application’s demand and its tolerance with compromised accuracy.
Case Study
- Introducing case: In order to protect wild animals from diseases and trafficking, it is required to monitor them closely. Since it is difficult for humans to have closed eyes in the forest, therefore using AI is the prominent recommendation. The present case is about monitoring the wild animals in the forest, where a drone (unmanned vehicle), backed up with on-device AI, is supposed to monitor animals’ count in the forest. The drone is embedded with the camera, which is capable of clicking photos while being in motion, it has a decent processor and enough memory which makes it capable of executing the deep learning algorithm and performing the object detection/ classification tasks. The drone is to fly across the selected area of the forest and to identify and count the animals.
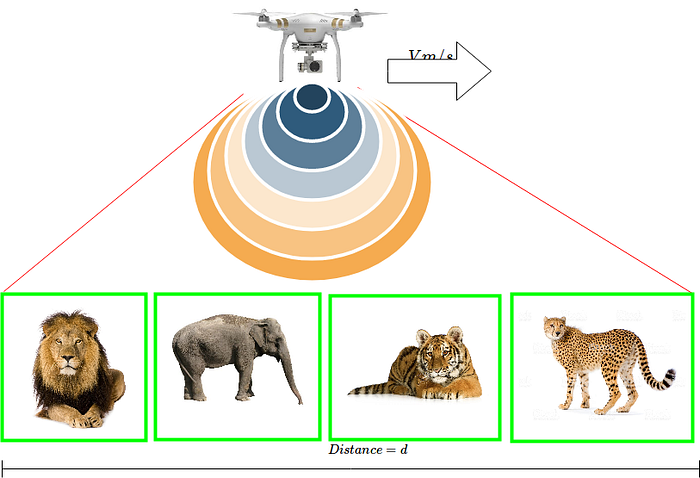
- Objective: The desired objective is to monitor every land of the targetted area and identify the presence of animals along with their count.
- The problem in detail: Drone flies with some velocity through aerial route across the targeted region of the forest and keeps clicking the photos, identifying the animals and maintaining their count. The problem arises when a drone flies across new objects (animals) when its computing unit is found busy in identifying the objects from previously taken image (because of inference time). Hence, currently taken images cannot be processed at run time and the situation leads to the unmonitored region.
- Shunt Connection: A promising solution: The area of the unmonitored region can be shrunk if it can reduce the inference time of used deep learning model. If the velocity of a flying drone is v mps, where for fastest drone v = 262 kmph or 72.7778 mps and if inferencing time of used deep network is 200 milliseconds then the distance traveled during this time d = 200 ∗ 10 −3 ∗ 72.78 = 14.5 meter. Whereas after reducing the flops
by 40%, inferencing time changes to 120 milliseconds. Hence, traveled distance is 120 ∗10 −3 ∗ 72.78 = 8.7 meter, giving the direct benefit of 5.8 meters extra monitored distance during the inferencing of one instance.
Conclusion
This work proposes a novel connection in deep learning architecture and showcases its working using four benchmark datasets (CIFAR10, CIFAR100, Caltech101, Caltech256). The proposed Shunt connection takes forward the concept of residual connection. The residual connection allows intermediate skipping throughout the network without making the results random.
The introduced connection helps in jumping the intermediate blocks of the network with the help of low-cost shunt connection. In this way, reducing the number of floating-point operations needed for inferencing consequently speeds up the network. The connection is specifically tested on an optimized state-of-the-art deep learning network MobileNet-V2. The architecture of the
the proposed connection is location-dependent and is tested maximally up to two disjoint locations, whereas connection for location#1 is proposed with 5 alternative architectures having a varying number of parameters.
The proposed method has the following limitations:
(a) The proposed connection works only with the models which are having residual connections.
(b) The method needs additional post-training efforts for optimizing the architecture.
(c) Finding the optimal, accurate architecture for the proposed connection needs additional experiments.
For more detail please follow the original paper:
B. Singh, D. Toshniwal and S.K. Allur, Shunt connection: An intelligent skipping of contiguous blocks for optimizing MobileNet-V2. Neural Networks (2019),
