Machine Learning From Scratch (Part -2)
(Demystifying the Mathematics behind Linear Regression using Gradient Descent)
Introduction
Mathematics and Programming are the two main ingredients that go into data science that every data practitioner needs to master to excel in this highly competitive field. But learning mathematics and practicing coding is more than what meets the eye.

That is why we have started this series, Machine Learning algorithms, from scratch. We will take you through the ambiguous forest of ML by breaking down each algorithm into its bare minimum mathematical concepts and NumPy-only implementations. By doing this, you will be able to learn mathematics and practice programming that is both concise and relevant to data science.
Journey so far
Previously we have discussed the mathematical intuition and python implementation of Least Squares Linear Regression.
Staying in the realm of linear regression today, we will start our discussion on “Gradient Descent Linear Regression.” The basic concepts of regression still apply, but the difference is that this algorithm will be multi-variate (more than one feature).
Linear Regression
Linear regression is the most straightforward ML algorithm to develop a relationship between the independent variable (X) and a dependent variable (Y).

Suppose we have multiple features or independent variables; keeping the model linear, we can calculate a slope for each independent variable. These “Slopes” are called the coefficients or weights of the regression model.

Since values of a particular coefficient will depend on all the independent variables, calling them “slopes” is not technically correct. Hence, the variable (w₁ to w₂) should be referred to as the weights of the model throughout. And the “intercept” (b) is referred to as bias.
We can still use the first equation as a standard equation while doing all the necessary derivations. Still, it is essential to know that there can be multiple independent variables in a regression problem and how to represent them.
Gradient Descent
Gradient descent is a stochastic approach to minimize the error generated in a regression problem. Therefore it is indeterministic, which means that in this method, we are trying to approximate the solution rather than find the exact closed-form solution.
Why do we use gradient descent when there is a closed-form solution available (Least Squares)
The answer is easy, “Computational Efficiency.”

In the Least Squares method, we use the formula (Multi-linear) for calculating the coefficients or weights of the model.
A closer inspection reveals that for every solution we have to find, we have to calculate the transpose and inverse of a matrix. Furthermore, calculating the transpose is fine but calculating the ‘Inverse of the given Matrix’ is computationally expensive.
We know that for a problem with “n” independent variables, the matrix will have “n*n” elements. The operation that will invert the “n*n” matrix has a complexity of O(n³).
And this little detail gives us the general case complexity for least squares: O(n³). This is fine for smaller problems, but the time complexity becomes a problem as the dimensionality increases.

In a Gradient Descent approach, the method is linear in “n” for a problem with dimensionality “K.” But we also need to iterate multiple times over the entire data set. which will add a constant to the complexity but regardless, the gradient descent solution will always be faster than.
TL;DR
Though least square is the definitive closed-form solution, it is way slower to compute when we deal with high-dimensionality datasets (which we often will in data science). Hence, gradient descent was developed to reduce the time complexity by sacrificing the closed form for a more iterative but faster method.
Math Behind Gradient Descent Linear Regression
The approach is simple,
- Initialize the weights and biases to zero.
- Use the current model to make predictions.
- Calculate the Error(Cost) from the prediction.
- Update the weights according to the Error.
- Repeat steps 2 to 4 until a satisfactory result is reached.
Now, to Implement the steps given above, we need to solve two critical problems:
- How to set up the Cost function (that will evaluate and represent the error/loss of the model)
- How to update the weights.
Let’s go through these steps one by one.
Cost Function
A Cost function is nothing but a function that can calculate the error for the model. And we know that error for a single prediction is calculated as the difference between the actual value and the predicted value.

We can now expand the predicted value term using the standard regression model discussed above.

To evaluate the cost function, we can square the error to eliminate the negative sign and then sum all the errors for all the predictions.

Furthermore, Since the sum of all the errors might get exceedingly large, we can normalize the value by dividing it by the number of samples in the dataset, which, let’s say, is “n.”

The Cost function we just derived is a widespread function used in machine learning, and it is called the Mean Squared Error or MSE.
Updating Weights
To update weights, we need to find two things:
- How much do we need to change and
- Do we need to increase or decrease(the direction of change)
These things can be extracted from the Gradient of the Cost Function.

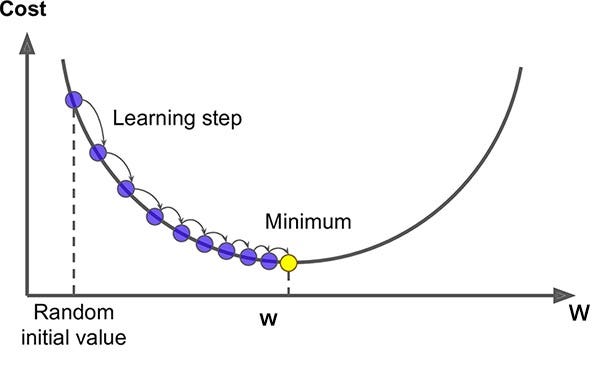{kind=link}
The direction of decreasing slope of the cost function will always point toward the minimum. And the value of the slope itself can be used as the distance from the minimum point. Because the slope is zero at the minimum, and it increases as we go farther away from the minimum.
So, we established that if we calculate the Gradient of the Cost Function, we can find the direction and degree by which we need to change the weights. Now, all that is left is to calculate the gradient itself.
Calculating Gradient with respect to weights
We will differentiate our cost function to the weights (w).
Don’t worry if you don’t know how to differentiate this equation; I’ll show all the steps here for mathematics nerds out there like myself. But the important takeaway for everyone will be the final outcome.
Finally, the outcome is
Calculating Gradient with respect to bias
Similarly like before, we will differentiate our cost function with respect to bias (b)
The final outcome
Ok, All the steps are done; just one more thing we can omit the “2” in both equations since a constant term does absolutely nothing, and we will also be implementing a learning rate in the algorithm.
Now, the gradient becomes:
Our Final Update Rule
We will simply scale the update rule with a constant learning rate (Lr). And this is our final update rule.
Conclusion
- That is it for this article; you just had a great deal of mathematics in this part of ML from Scratch. Congratulations on increasing your ML knowledge by a slight bit today.
- Since we have covered all the mathematics intuition behind Gradient Descent Linear Regression, in the next article, we will use all this knowledge and Implement the algorithm in python using only NumPy!
- Follow me for more upcoming data science, Machine Learning, and artificial intelligence articles.
Also, Do give me a Clap👏 if you find this article useful, as your encouragement catalyzes inspiration for and helps me to create more cool stuff like this.
Final Thoughts and Closing Comments
There are some vital points many people fail to understand while they pursue their Data Science or AI journey. If you are one of them and looking for a way to counterbalance these cons, check out the certification programs provided by INSAID on their website. If you liked this story, I recommend you to go with the Global Certificate in Data Science & AI because this one will cover your foundations, machine learning algorithms, and deep neural networks (basic to advance).