Deep Learning Book: Chapter 9— Convolutional Networks

This is going to be a series of blog posts on the Deep Learning book where we are attempting to provide a summary of each chapter highlighting the concepts that we found to be the most important so that other people can use it as a starting point for reading the chapters, while adding further explanations on few areas that we found difficult to grasp. Please refer this for more clarity on notation.
When discussing deep learning, two models have become the leading buzzwords — Convolutional Neural Networks, which are the topic of this post, and Recurrent Neural Networks, which will be discussed soon.
Convolutional networks are an example of the successful application of insights obtained by studying the brain. We will avoid reiteration, and direct the reader to a summary of the history of deep learning and how convolutional networks tie in, which can be found at the end of this chapter.
1. The Convolution Operation
The convolution operates on the input with a kernel (weights) to produce an output map given by:

Let us break down the formula. The steps involved are:
- Express each function in terms of a dummy variable τ
- Reflect the function g i.e. g(τ) → g(-τ)
- Add a time offset i.e. g(τ) → g(t-τ). Adding the offset shifts the input to the right by t units (by convention, a negative offset shits it to the left)
- Multiply f and g point-wise and accumulate the results to get output at instant t. Basically, we are calculating the area of overlap between f and shifted g

For our application, we are interested in the discrete domain formulation:


When the kernel is not flipped in its domain, we obtain the cross-correlation operation. The basic difference between the two operations is that convolution is commutative in nature, i.e. f and g can be interchanged without changing the output. Cross-correlation is not commutative. This difference is highlighted in the image below:

Although these equations imply that the domains for both f and g are infinite, in practice, these two variables are non-zero only in a finite region. As a result, the output is non-zero only in a finite region (where the non-zero regions of f and g overlap).
The intuition for convolution in 1-D can be extended to n-dimensions by nesting the convolution operations. Vincent Dumoulin and Francesco Visin provide an in depth analysis of how input and output shapes and computations are tied. Below is their visualization of a 2-D convolution operation:
The 1D convolution operation can be represented as a matrix vector product. The kernel marix is obtained by composing weights into a Toeplitz matrix. A Toeplitz matrix has the property that values along all diagonals are constant.


To extend this principle to 2D input, we first need to unroll the 2D input into a 1D vector. Once this is done, the kernel needs to be modified as before but this time resulting in a block-circulant matrix. What’s that?

A circulant matrix is a special case of a Toeplitz matrix where each row is a circular shift of the previous row. To see that it is a special case of the Toeplitz matrix is trivial.

A matrix which is circulant with respect to its sub-matrices is called a block circulant matrix. If each of the submatrices is itself circulant, the matrix is called doubly block-circulant matrix.
Now, given a 2D kernel, we can create the block-circulant matrix that will act allow matrix-vector implementation of convolution as below:

2. Motivation
Sparse Interactions
Each output unit is connected to (affected by) only a subset of the input units.

If there are m input units and n output units, a fully connected layer would require mn parameters (one per connection) and correspondingly the number of operations would scale as O(mn). On the other hand, if each output unit is sparsely connected to k input units, the layer requires kn parameters and O(kn) computations. In general, for a convolutional layer, the number of output units are a function of kernel size, stride and padding (discussed later). This actually makes n a function of m. Keeping this in mind O(mn) ~ O(m²) while O(kn) ~ O(km). By keeping k several orders of magnitude smaller than m, we see that the computational saving from sparse connections are huge.
As a practical example, consider a 3x3kernel operating on a black and white image of dimensions 224x224(this is a very standard setting of kernel size and image size, and can be seen in the first layer of the VGGNet). For same padding and stride as 1 (discussed in detail later), output size will also be 224x224. If this first layer were to be a fully connected layer, number of parameters would be ~2.5 billion (=224² x 224²). On the other hand, using a sparse layer with each output connected to 9(=3x3) inputs, the number of parameters is ~451 thousand (=224² x 9). In fact, a convolutional layer also incorporates parameter sharing (see below) and this number will decrease further.
Parameter Sharing
In the previous section, we saw that the output units are only connected to a small number of input units. In a convolutional layer, each kernel weight is used at every input position (except maybe at boundaries where different padding rules apply as discussed below), i.e. parameters used to compute different output units are tied together. By tied together, we mean that at all times their values are same. This means that even during training, they are updated by the same amount and by collecting the gradients from all output units.
Parameter sharing allows models to capture local connectivity while simultaneously computing the same features at different spatial locations. We will see the use of this property soon.
Here we make a short detour to section 5 for discussing locally connected layers and tiled convolution.
- Locally connected layer/unshared convolution: The connectivity graph of convolution operation and locally connected layer is the same. The only difference is that parameter sharing is not performed, i.e. each output unit performs a linear operation on its neighbourhood but the parameters are not shared across output units. This allows models to capture local connectivity while allowing different features to be computed at different spatial locations. This however requires much more parameters than the convolution operation.
- Tiled convolution is a sort of middle step between locally connected layer and traditional convolution. It uses a set of kernels that are cycled through. This reduces the number of parameters in the model while allowing for some freedom provided by unshared convolution.

The parameter complexity and computation complexity can be obtained as below. Note that:
- m = number of input units
- n = number of output units
- k = kernel size
- l = number of kernels in the set (for tiled convolution)

You can see now that the quantity of ~451 thousand parameters corresponds to the locally connected convolution operation. If we use a set of 200 kernels, the number of parameters for tiled convolution is 1.8 thousand. For a traditional convolution operation, this number is 9 parameters.
Equivariance
A function f is said to be equivariant to a function g if
f(g(x)) = g(f(x))
i.e. if input changes, the output changes in the same way.
Parameter sharing in a convolutional network provides equivariance to translation. What this means is that translation of the image results in corresponding translation in the output map (except maybe for boundary pixels). The reason for this is very intuitive: the same feature is being computed at all input points.
Note that convolution operation by itself is not equivariant to changes in scale or rotation. I’ve added a code snippet to demonstrate this. See the figure below that for more clarity on this:

3. Pooling
A convolutional layer can be broken down into the following components:
- Convolution
- Activation (detector stage)
- Pooling
The pooling function calculates a summary statistic of the nearby pixels at the point of operation. Some common statistics are max, mean, weighted average and L² norm of a surrounding rectangular window.
Pooling makes the representation slightly translation invariant, in that small translations in the input do not cause large changes in the output map. It allows detection of a particular feature if we only care about its existence, not its position in an image.

Pooling over feature channels can be used to develop invariance to certain transformations of the input. For e.g., units in a layer may be developed to learn rotated features and then pooled over. This property has been used in Maxout networks.

Pooling reduces the input size to the next layer in turn reducing the number of computations required upstream. Variable sized inputs are an issue when presented to a fully connected layer. To counter this, the pooling operation maybe performed on regions of the input (such as quadrants) thus allowing the model to work on variable sized inputs.
Theoretical guidelines for which pooling to use have been studied. Dynamic pooling has also been studied.
4. Convolution and Pooling as an Infinitely Strong Prior
What is a weight prior?
Assumptions about the weights (before learning) in terms of acceptable values and range are encoded into the prior distribution of the weights. A weak prior is has a high variance and shows that there is low confidence in the initial value of the weight. A strong prior is turn shows a narrow range of values about which we are confident before learning begins. An infinitely strong prior demarkates certain values as forbidden completely assigning them zero probability.
If we view the convolutional layer as a fully connected layer, convolution imposes an infinitely strong prior by making the following restrictions on the weights:
- Adjacent units must have the same weight but shifted in space.
- Except for a small spatially connected region, all other weights must be zero.
Likewise the pooling stage imposes an infinitely strong prior by requiring features to be translation invariant.
Insights:
- Convolution and pooling can cause underfitting if the priors imposed are not suitable for the task. As an example, consider this scenario. We may want to learn different features for different parts of an input. But the compulsion to used tied weights (enforced by standard convolution) on all parts of an image, forces us to either compromise or use more kernels (extract more features).
- Convolutional models should only be compared with other convolutional models. This is because other models which are permutation invariant can learn even when input features are permuted (thus loosing spatial relationships). Such models need to learn these spatial relationships (which are hard-coded in CNNs).
5. Variants of the Basic Convolution Function
In practical implementations of the convolution operation, certain modifications are made which deviate from the discrete convolution formula mentioned above:
- In general a convolution layer consists of application of several different kernels to the input. This allows the extraction of several different features at all locations in the input. This means that in each layer, a single kernel (filter) isn’t applied. Multiple kernels (filters), usually a power of 2, are used as different feature detectors.
- The input is generally not real-valued but instead vector valued (e.g. RGB values at each pixel or the feature values computed by the previous layer at each pixel position). Multi-channel convolutions are commutative only if number of output and input channels is the same.
- In order to allow for calculation of features at a coarser level strided convolutions can be used. The effect of strided convolution is the same as that of a convolution followed by a downsampling stage. This can be used to reduce the representation size.

- Zero padding helps to make output dimensions and kernel size independent. 3 common zero padding strategies are:
- valid: The output is computed only at places where the entire kernel lies inside the input. Essentially, no zero padding is performed. For a kernel of size k in any dimension, the input shape of m in the direction will become m-k+1 in the output. This shrinkage restricts architecture depth.
- same: The input is zero padded such that the spatial size of the input and output is same. Essentially, for a dimension where kernle size is k, the input is padded by k-1 zeros in that dimension. Since the number of output units connected to border pixels is less than that for centre pixels, it may under-represent border pixels.
- full: The input is padded by enough zeros such that each input pixel is connected to the same number of output units.
In terms of test set accuracy, the optimal padding is somewhere between same and valid.

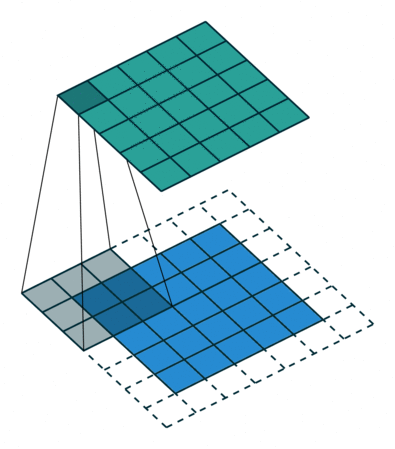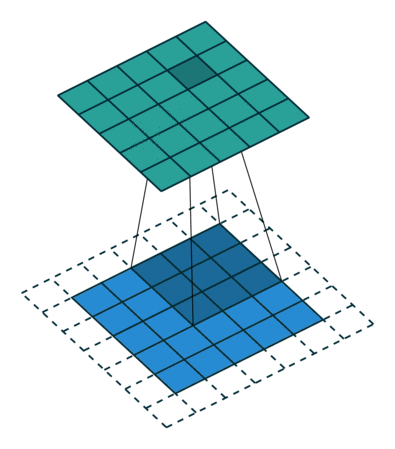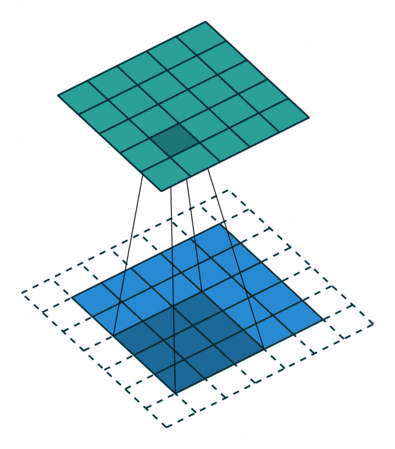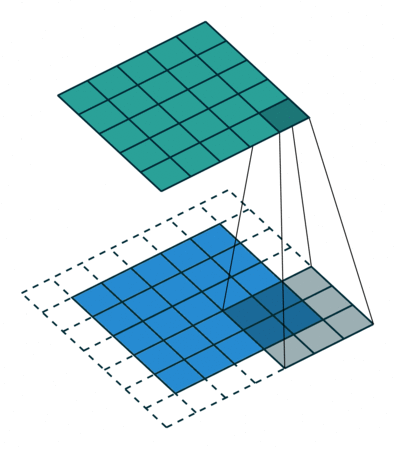

- Besides locally-connected layers and tiled convolution, another extension can be to restrict the kernels to operate on certain input channels. One way to implement this is to connect the first m input channels to the first n output channels, the next m input channels to the next n output channels and so on. This method decreases the number of parameters in the model without dereasing the number of output units.
- When max pooling operation is applied to locally connected layer or tiled convolution, the model has the ability to become transformation invariant because adjacent filters have the freedom to learn a transformed version of the same feature. This essentially similar to the property leveraged by pooling over channels rather than spatially.
- Bias terms can be used in different ways in the convolution stage. For locally connected layer and tiled convolution, we can use a bias per output unit and kernel respectively. In case of traditional convolution, a single bias term per output channel is used. If the input size is fixed, a bias per output unit may be used to counter the effect of regional image statistics and smaller activations at the boundary due to zero padding.
6. Structured Outputs
Convolutional networks can be trained to output high-dimensional structured output rather than just a classification score. A good example is the task of image segmentation where each pixel needs to be associated with an object class. Here the output is the same size (spatially) as the input. The model outputs a tensor S where S[i,j,k] is the probability that pixel (j,k) belongs to class i.
To produce an output map as the same size as the input map, only same-padded convolutions can be stacked. Alternatively, a coarser segmentation map can be obtained by allowing the output map to shrink spatially.
The output of the first labelling stage can be refined successively by another convolutional model. If the models use tied parameters, this gives rise to a type of recursive model as shownbelow. (H¹, H², H³ share parameters)

The output can be further processed under the assumption that contiguous regions of pixels will tend to belong to the same label. Graphical models can describe this relationship. Alternately, CNNs can learn to optimize the graphical models training objective.
Another model that has gained popularity for segmentation tasks (especially in the medical imaging community) is the U-Net. The up-convolution mentioned is just a direct upsampling by repetition followed by a convolution with same padding.

7. Data Types
The data used with a convolutional network usually consist of several channels, each channel being the observation of a different quantity at some point in space or time.
One advantage to convolutional networks is that they can also process inputs with varying spatial extents.
When the output is accordingly variable sized, no extra design change needs to be made. If however the output is fixed sized, as in the classification task, a pooling stage with kernel size proportional to the input size needs to be used.

8. Efficient Convolution Algorithms
In some problem settings, performing convolution as pointwise multiplication in the frequency domain can provide a speed up as compared to direct computation. This is a result from the property of convolution:


When a d-dimensional kernel can be broken into the outer product of d vectors, the kernel is said to be separable. The corresponding convolution operations are more efficient when implemented as d 1-dimensional convolutions rather than a direct d-dimensional convolution. Note however, it may not always be possible to express a kernel as an outer product of lower dimensional kernels.
This is not to be confused with depthwise separable convolution (explained brilliantly here). This method restricts convolution kernels to operate on only one input channel at a time followed by 1x1 convolutions on all channels of the intermediate output.
Devising faster ways of performing convolution or approximate convolution without harming the accuracy of the model is an active area of research.
9. Random and Unsupervised Features
To reduce the computational cost of training the CNN, we can use features not learned by supervised training.
- Random initialization has been shown to create filters that are frequency selective and translation invariant. This can be used to inexpensively select the model architecture. Randomly initialize several CNN architectures and just train the last classification layer. Once a winner is determined, that model can be fully trained in a supervised manner.
- Hand designed kernels may be used; e.g. to detect edges at different orientations and intensities.
- Unsupervised training of kernels may be performed; e.g. applying k-means clustering to image patches and using the centroids as convolutional kernels. Unsupervised pre-training may offer regularization effect (not well established). It may also allow for training of larger CNNs because of reduced computation cost.
Another approach for CNN training is greedy layer-wise pretraining most notably used in convolutional deep belief network. For example, in the case of multi-layer perceptrons, starting with the first layer, each layer is trained in isolation. Once the first layer is trained, its output is stored and used as input for training the next layer, and so on.
10. The Neuroscientific Basis for Convolutional Networks
Hubel and Wiesel studied the activity of neurons in a cat’s brain in response to visual stimuli. Their work characterized many aspects of brain function.
In a simplified view, we have:
- The light entering the eye stimulates the retina. The image then passes through the the optic nerve and a region of the brain called the LGN (lateral geniculate nucleus)
- V1 (primary visual cortex): The image produced on the retina is transported to the V1 with minimal processing. The properties of V1 that have been replicated in CNNs are:
- The V1 response is localized spatially, i.e. the upper image stimulates the cells in the upper region of V1 [localized kernel].
- V1 has simple cells whose activity is a linear function of the input in a small neighbourhood [convolution].
- V1 has complex cells whose activity is invariant to shifts in the position of the feature [pooling] as well as some changes in lighting which cannot be captured by spatial pooling [cross-channel pooling].
3. There are several stages of V1 like operations [stacking convolutional layers].
4. In the medial temporal lobe, we find grandmother cells. These cells respond to specific concepts and are invariant to several transforms of the input. In the medial temporal lobe, researchers also found neurons spiking on a particular concept, e.g. the Halle Berry neuron fires when looking at a photo/drawing of Halle Berry or even reading the text Halle Berry. Of course, there are neurons which spike at other concepts like Bill Clinton, Jennifer Aniston, etc.
The medial temporal neurons are more generic than CNN in that they respond even to specific ideas. A closer match to the function of the last layers of a CNN is the IT (inferotemporal cortex). When viewing an object, information flows from the retina, through LGN, V1, V2, V4 and reaches IT. This happens within 100ms. When a person continues to look at an object, the brain sends top-down feedback signals to affect lower level activation.
Some of the major differences between the human visual system (HVS) and the CNN model are:
- The human eye is low resolution except in a region called fovea. Essentially, the eye does not receive the whole image at high resolution but stiches several patches through eye movements called saccades. This attention based gazing of the input image is an active research problem. Note: attention mechanisms have been shown to work on natural language tasks.
- Integration of several senses in the HVS while CNNs are only visual.
- The HVS processes rich 3D information, and can also determine relations between objects. CNNs for such tasks are in their early stages.
- The feedback from higher levels to V1 has not been incorporated into CNNs with substantial improvement.
- While the CNN can capture firing rates in the IT, the similarity between intermediate computations is not established. The brain probably uses different activation and pooling functions. Even the linearity of filter response is doubtful as recent models for V1 involve quadratic filters.
Neuroscience tells us very little about the training procedure. Backpropogation which is a standard training mechanism today is not inspired by neuroscience and sometimes considered biologically implausible.

In order to determine the filter parameters used by neurons, a process called reverse correlation is used. The neuron activations are measured by an electrode when viewing several white noise images and a linear model is used to approximate this behaviour. It has been shown experimentally that the weights of the fitted model of V1 neurons are described by Gabor functions. If we go by the simplified version of the HVS, if the simple cells detect Gabor-like features, then complex cells learn a function of simple cell outputs which is invariant to certain translations and magnitude changes.
A wide variety of statistical learning algorithms (from unsupervised (sparse code) to deep learning (first layer features)) learn features with Gabor-like functions when applied to natural images. This goes to show that while no algorithm can be touted as the right method based on Gabor-like feature detectors, a lack of such features may be taken as a bad sign.

This concludes our discussion on one of the most important architectures that has caused a series of advancements in AI as described in Chapter 9. We hope that this gave you a good understanding of the basics of convolution, CNNs and the various tweaks that have been made to improve its performance. We’re sure that if you understand this post thoroughly, you won’t have a lot of difficulty in understanding various papers on CNNs. To stay updated with our posts, follow our publication, Inveterate Learner. If you’re looking for the summary of previous chapters or are more comfortable reading from a Jupyter Notebook, feel free to have a look over our repository here.
I think it’s important to reason from first principles rather than by analogy. With analogy, we are doing a thing because it’s like something else that was done by other people. With first principles, you boil things down to the most fundamental truths and then reason up from there.
- Elon Musk