Autocorrelação espacial
Um método espacial de análise de variáveis
O cálculo de correlação é um tópico de grande importância para estatísticos e cientistas de dados, pois permite descobrir se temos variáveis que têm uma tendência de crescimento parecida. As mais difundidas e utilizadas são a de Pearson e a de Spearman, pela facilidade em sua compreensão e cálculo.
Entretanto, existem fenômenos do mundo real que podem ser analisados a partir de tendências espaciais. Vamos tomar como exemplo a pluviometria no Brasil. Ao analisar o padrão de chuvas em um país de proporções continentais como o Brasil, é possível perceber que para cada estação do ano e para cada região do Brasil existe um padrão de chuvas diferente; como a região Norte, que devido à maior umidade costuma apresentar maiores patamares de precipitação anual.

Assim, se quiséssemos descobrir as melhores temporadas de plantio no território brasileiro, fatalmente precisaríamos levar em conta o fator espacial, não só do ponto de vista das chuvas, mas também de outras variáveis climáticas e demográficas. Gostaríamos de entender se em cada estação do ano existe uma tendência entre clima e espaço que favoreça, por exemplo, o desenvolvimento de alguma cultura específica em cada região do Brasil.
Esse exemplo motiva o tópico deste artigo, que é a autocorrelação espacial. Vou apresentar aqui os conceitos e as formulações que estão por trás desse método.
Então, vamos nessa!
Mas afinal, o que é autocorrelação espacial?
Trata-se de um método de correlação que considera a distribuição de variáveis do problema em um espaço físico considerado. É uma estatística muito útil quando desejamos considerar a distribuição espacial de determinadas variáveis do nosso problema. A ideia é determinar se valores similares se encontram agrupados, dispersos ou distribuídos aleatoriamente no espaço, ou seja, se existe alguma tendência desses valores no espaço.
Um exemplo sobre esse conceito é apresentado a seguir:

Se analisarmos o fenômeno de imigração na Itália em 2009, é possível perceber que existe uma tendência de crescimento das taxas de imigração da região sul da Itália (menores taxas) em direção à região norte (maiores taxas). Entretanto, existe alguma forma de quantificar esse grau de correlação?
Existe! E se chama índice de Moran ou simplesmente o Moran’s I. Vou mostrar a vocês como calculá-lo.
Coeficiente Moran’s I
O Moran’s I é uma estatística que corresponde ao coeficiente de correlação entre uma variável numa região e o valor dessa variável em seus vizinhos. Essa estatística pode tomar valores no intervalo [-1, 1], assim como os coeficientes de correlação de Pearson e Spearman.
Alguns passos devem ser executados para calcular o Moran’s I: definir vizinhança; compilar os valores dos vizinhos para cada região (esses valores são chamados de lag), e; calcular um coeficiente de regressão da nuvem de pontos variável x lag (variável).
Esses passos ficarão mais claros a seguir:
- Definindo vizinhança
O conceito de vizinhança entre regiões é um aspecto fundamental desse método, sendo o que o diferencia dos métodos de correlação citados inicialmente.
Diferentes abordagens podem ser utilizadas ao definir os vizinhos de uma região:
- Todas as regiões que fazem fronteira com a região considerada;
- Todas as regiões cujo centroide está a uma distância máxima preestabelecida do centroide da região considerada;
- Uma quantidade fixa K de regiões cujos centroides são os mais próximos (K-nearest neighbors) do centroide da região considerada.
Abaixo estão exemplificadas as definições de vizinhança listadas, utilizando como referência o estado de Goiás (GO):

2. Cálculo dos lags
Após definida a vizinhança, os valores da variável nos vizinhos são resumidos em uma única quantidade (por exemplo, a média de todos os valores). Esse valor é conhecido como lagging value (ou somente lag).
Suponhamos que estejamos estudando os índices pluviométricos anuais de cada estado brasileiro. Além disso, suponhamos que adotemos todos os estados limítrofes como vizinhança. Neste caso, tomando o estado de Goiás (GO) como referência, calculamos para o mês de maio de 2021 de acordo com os dados do INPE:

E temos também pluviometria(GO) = 36.4 mm. Assim, construímos o par
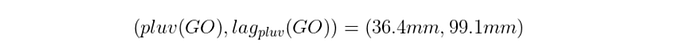
Obs.: Na prática, no cálculo do lag é feita uma ponderação pela distância entre os centroides. Não fizemos aqui para simplificar o cálculo do Moran’s I.
3. Calcular o coeficiente de regressão da nuvem de pontos variável x lag(variável)
Fazendo o mesmo com todos os estados brasileiros, é possível plotar o gráfico pluviometria x pluviometria_lag, ou seja, estamos verificando a relação entre a variável na região contra a variável nos vizinhos da região.
Uma vez tendo todos os pares (pluviometria, pluviometria_lag), traçamos a reta que melhor ajusta os pontos, minimizando o erro quadrático (na prática, calculamos uma Regressão Linear). A inclinação da reta mede se existe uma tendência entre pluviometria e pluviometria_lag, e a esse coeficiente damos o nome de Moran’s I. Veja a imagem a seguir:
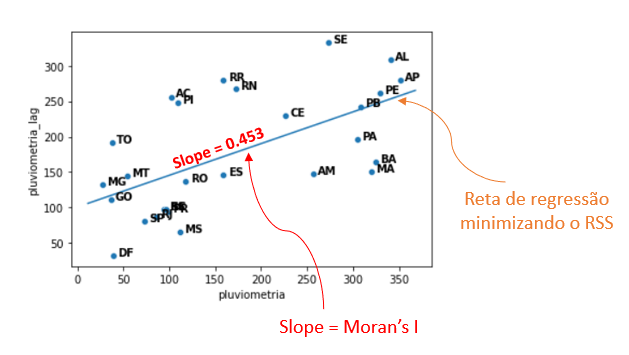
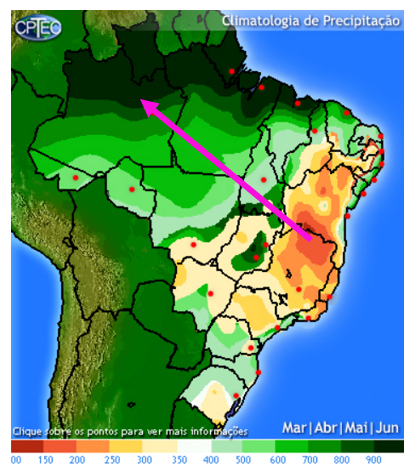
Foi obtido um valor de 0.453 para o Moran’s I, o que é um valor relativamente alto considerando o intervalo da métrica Moran’s I. De fato, ao observar o mapa do Brasil para maio de 2021, é possível verificar que existe uma tendência sudeste/nordeste (menos chuvas) — norte (mais chuvas) nos valores de pluviometria:
4. Interpretação do Moran’s I
A definição do cálculo do Moran’s I traz a seguinte interpretação:
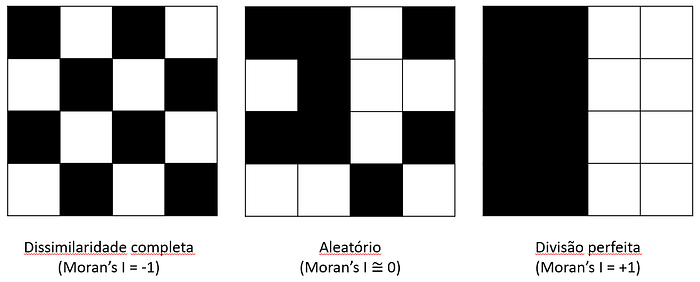
- Se Moran’s I ≅ 1, então os valores da variável em regiões vizinhas têm uma diferença pequena, o que indica que existe uma correlação entre a grandeza e a distribuição espacial dessa grandeza no espaço.
- Se Moran’s I ≅ 0, então os valores da variável em regiões vizinhas estão distribuídos de forma praticamente aleatória, sugerindo ausência de correlação espacial.
- Se Moran’s I ≅ -1, há uma dissimilaridade entre os valores da grandeza encontrados nas regiões e nos respectivos vizinhos.
Abaixo está uma imagem apresentando essa interpretação. No caso de dissimilaridade completa, notar que os vizinhos adjacentes têm cores opostas à casa de referência.
Tipos de análise
O Moran’s I pode ser calculado em dois tipos diferentes de análise.
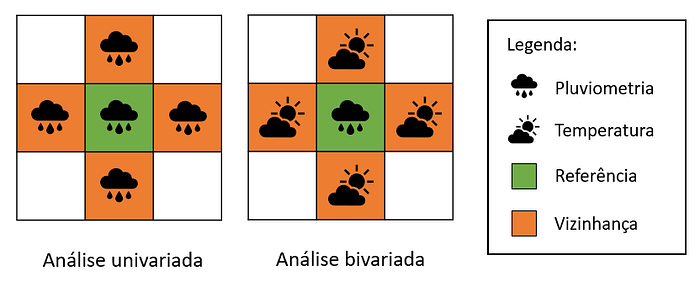
- Análise Univariada
No exemplo da pluviometria, foi feita uma análise univariada, pois comparamos a variável pluviometria com o lag espacial dela mesma (e por isso é chamada de autocorrelação espacial).
Nesta análise, o objetivo é descobrir se uma variável específica tem alguma tendência espacial (se ela tem alguma correlação com sua distribuição espacial).
2. Análise Bivariada
Na análise bivariada, por outro lado, é avaliado o grau de variação espacial de uma variável em relação a outra variável.
Deseja-se, com esse método, identificar se duas variáveis estão correlacionadas no espaço, ou seja, se seguem a mesma tendência espacial.
Poderíamos querer analisar, por exemplo, se existe essa correlação entre chuvas e temperaturas no território brasileiro no mês de maio de 2021. Neste caso, se tomássemos como referência o estado de Goiás, obteríamos a variável pluviometria nesse estado e compararíamos com o lag da variável temperatura nos estados em sua vizinhança.
Local Moran’s I
Até agora, foi calculado o Moran’s I global. Pegamos todos os pontos de dados que foram calculados para obter um índice que dá uma estimativa completa em todo o Brasil.
Também é possível (e recomendado) fazer a decomposição do Moran’s I de forma a construir uma medida localizada de autocorrelação, o que é chamado de Moran’s I Local. A ideia é encontrar hot spots e cold spots, que são regiões em que se encontram respectivamente pontos com maior e menor autocorrelação espacial. Com isso, conseguimos avaliar a variabilidade dos nossos pontos no gráfico variável x lag.
No caso, são definidos como hot spots as regiões em que “variável” e “lag” seguem a mesma tendência, ou seja, ambos são grandes (HH — High-High) ou ambos são pequenos (LL — Low-Low); e como cold spot as regiões que têm uma relação inversa entre “variável” e “lag” (HL — High-Low ou LH — Low-High).
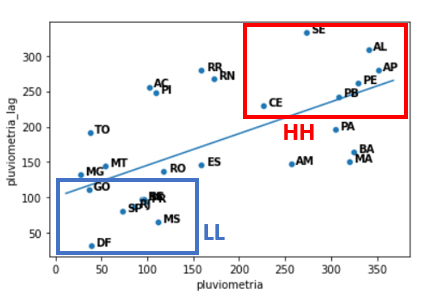
Esta análise, quando vista no mapa, também é chamada de LISA (Local Spatial Autocorrelation).
Conclusão
Vimos que o Moran’s I permite capturar correlações espaciais considerando a relação entre cada região e sua vizinhança. Também vimos como interpretá-lo, e sua relação com a distribuição das variáveis no espaço.
Espero que tenham gostado! ;)
Link para o repositório no GitHub com a análise pluviométrica (notebook: Pluviometria — maio de 2021.ipynb).
Qualquer opinião, resultado, conclusão ou recomendação expressa neste artigo é de responsabilidade do autor e não reflete necessariamente o ponto de vista do Itaú Unibanco S.A.
