Guide to Multimodal RAG for Images and Text

Multimodal AI stands at the forefront of the next wave of AI advancements. In fact, one of my generative AI predictions for 2024 is that multimodal models will move into the mainstream and become the norm by the end of the year. Traditional AI systems can typically only process a single data type, such as text, but take a look around you, the world is not unimodal. Humans interact with their environment using multiple senses, multimodal AI aims to emulate this perception in machines. Ideally, we should be able to take any combination of data types (text, image, video, audio, etc.) and present them to a generative AI model all at the same time.
Large Language Models (LLMs) of course have their limitations, such as a limited context window and a knowledge cutoff date. To overcome these limitations, we can use a process called Retrieval Augmented Generation (RAG) which consists of two key steps: retrieval and generation. Initially, relevant data is retrieved in response to a user’s query. Then, this data aids the LLM in generating a specific response. Vector databases support the retrieval phase by storing diverse data type embeddings, enabling efficient multimodal data retrieval. This process ensures the LLM can generate responses to a user’s query by accessing a combination of the most relevant text, image, audio, and video data.
In this article, we will dive into both phases of multimodal RAG, retrieval and generation. First we will walk through two multimodal retrieval methods that store and retrieve both text and image data using a vector database. Secondly, for the generation phase, we will use LLMs to generate a response based on the retrieved data and a user’s query.
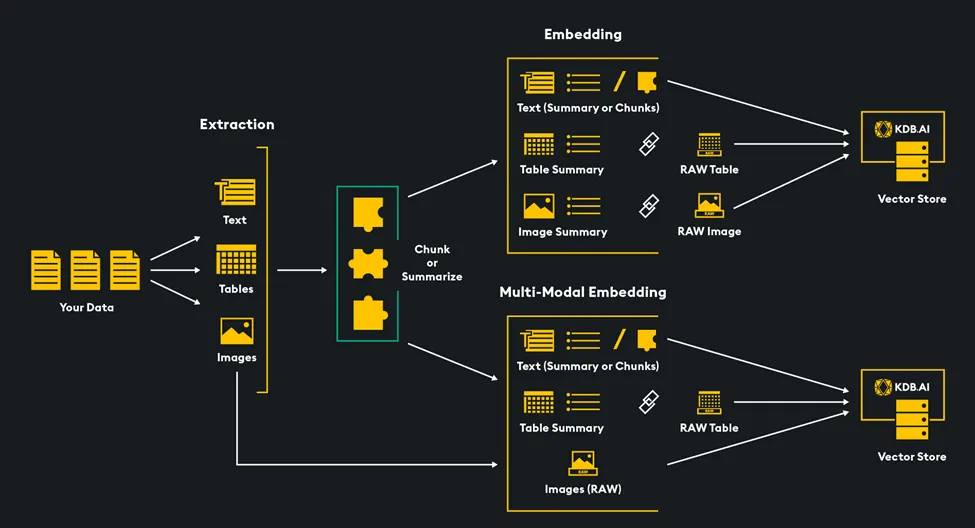
Retrieval Methods:
Our objective is to embed images and text into a unified vector space to enable simultaneous vector searches across both media types. We do this by embedding our data — converting data into numeric vector representations — and storing them in the KDB.AI vector database. There are several methods to do this and today we will explore two:
1. Use a multimodal embedding model to embed both text and images.
2. Use a multimodal LLM to summarize images, pass summaries and text data to a text embedding model such as OpenAI’s “text-embedding-3-small”.
By the end of this article we’ll cover implementing each method of multimodal retrieval in theory and code, using a dataset of animal images and descriptions. This system will allow queries to return relevant images and text, serving as a retrieval mechanism for a multimodal Retrieval Augmented Generation (RAG) application. Let’s get started!
Method 1: Use a Multimodal Embedding Model to Embed both Text and Images

A multimodal embedding model enables the integration of text, images, and various data types into a single vector space, facilitating cross-modality vector similarity searches within the KDB.AI vector database. A multimodal LLM can then be augmented with retrieved embeddings to generate a response and complete the RAG pipeline.
The multimodal embedding model we will explore is called “ImageBind” which was developed by Meta. ImageBind can embed several data modalities including text, images, video, audio, depth, thermal, and inertial measurement unit (IMU) which includes gyroscope and accelerometer data.
ImageBind GitHub Repository: https://github.com/facebookresearch/ImageBind
Let us walk through several code snippets outlining the use of ImageBind. See the full notebook here.
First, we clone ImageBind, import necessary packages, and instantiate the ImageBind model so that we can use it later on in the code:
!git clone https://github.com/facebookresearch/ImageBindimport pandas as pd
import os
import PIL
from PIL import Image
import torch
from imagebind import data
from imagebind.models import imagebind_model
from imagebind.models.imagebind_model import ModalityType
os.chdir('./ImageBind')
!pip install .device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Instantiate the ImageBind model
model = imagebind_model.imagebind_huge(pretrained=True)
model.eval()
model.to(device)Next, we need to define functions to help us use ImageBind on our data, extract the multimodal embeddings, and read text from a text file:
#Helper functions to create embeddings
def getEmbeddingVector(inputs):
with torch.no_grad():
embedding = model(inputs)
for key, value in embedding.items():
vec = value.reshape(-1)
vec = vec.numpy()
return(vec)
def dataToEmbedding(dataIn,dtype):
if dtype == 'image':
data_path = [dataIn]
inputs = {
ModalityType.VISION: data.load_and_transform_vision_data(data_path, device)
}
elif dtype == 'text':
txt = [dataIn]
inputs = {
ModalityType.TEXT: data.load_and_transform_text(txt, device)
}
vec = getEmbeddingVector(inputs)
return(vec)
# Helper function to read the text from a file
def read_text_from_file(filename):
try:
# Open the file in read mode ('r')
with open(filename, 'r') as file:
# Read the contents of the file into a string
text = file.read()
return text
except IOError as e:
# Handle any I/O errors
print(f"An error occurred: {e}")
return NoneNow let’s set up an empty data frame to store file paths, data types, and embeddings within. We will also get a list of paths of the images and texts we will be storing in the vector database:
#Define a dataframe to put our embeddings and metadata into
#this will later be used to load our vector database
columns = ['path','media_type','embeddings']
df = pd.DataFrame(columns=columns)
#Get a list of paths for images, text
images = os.listdir("./data/images")
texts = os.listdir("./data/text")Time to loop through our images and texts and send them through our helper functions which will embed the data with ImageBind:
#loop through images, append a row in the dataframe containing each
# image's path, media_type (image), and embeddings
for image in images:
path = "./data/images/" + image
media_type = "image"
embedding = dataToEmbedding(path,media_type)
new_row = {'path': path,
'media_type':media_type,
'embeddings':embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
#loop through texts, append a row in the dataframe containing each
# text's path, media_type (text), and embeddings
for text in texts:
path = "../data/text/" + text
media_type = "text"
txt_file = read_text_from_file(path)
embedding = dataToEmbedding(txt_file,media_type)
new_row = {'path': path,
'media_type':media_type,
'embeddings':embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)We now have a data frame that contains the path, media type, and multimodal embeddings for all of our data!
Next, we will set up our KDB.AI vector database. You can signup for free at KDB.AI, and get an endpoint and API key.
# vector DB imports
import os
from getpass import getpass
import kdbai_client as kdbai
import time
#Set up KDB.AI endpoing and API key
#Go to kdb.ai to sign up for free if you don't already have an account!
KDBAI_ENDPOINT = (
os.environ["KDBAI_ENDPOINT"]
if "KDBAI_ENDPOINT" in os.environ
else input("KDB.AI endpoint: ")
)
KDBAI_API_KEY = (
os.environ["KDBAI_API_KEY"]
if "KDBAI_API_KEY" in os.environ
else getpass("KDB.AI API key: ")
)
#connect to KDB.AI
session = kdbai.Session(api_key=KDBAI_API_KEY, endpoint=KDBAI_ENDPOINT)To ingest our data into the KDB.AI vector database, we need to set up our table schema. In our case, we will have a column for file path, media_type, and the embeddings. The embeddings will have 1024 dimensions, because that is the dimensionality output by ImageBind. The similarity search method is defined as ‘cs’ or cosine similarity, and the index is simply a flat index. Each of these parameters can be customized based on your use-case.
table_schema = {
"columns": [
{"name": "path", "pytype": "str"},
{"name": "media_type", "pytype": "str"},
{
"name": "embeddings",
"pytype": "float32",
"vectorIndex": {"dims": 1024, "metric": "CS", "type": "flat"},
},
]
}Ensure a table does not exist with the same name and then create a table called “multi_modal_demo”:
# First ensure the table does not already exist
try:
session.table("multi_modal_demo").drop()
time.sleep(5)
except kdbai.KDBAIException:
pass
# Create the table called "metadata_demo"
table = session.create_table("multi_modal_demo", table_schema)Load our data into our KDB.AI table!
#Insert the data into the table, split into 2000 row batches
from tqdm import tqdm
n = 2000 # chunk row size
for i in tqdm(range(0, df.shape[0], n)):
table.insert(df[i:i+n].reset_index(drop=True))Great work, we have loaded multimodal data into our vector database. This means that both text and image embeddings are stored within the same vector space. Now we can execute multimodal similarity searches.
We will define three helper functions. One to transform a natural language query into an embedded query vector. Another to to read text from a file. Lastly, one to help us cleanly view the results of the similarity search.
# Helper function to create a query vector from a natural language query
def QuerytoEmbedding(text):
text = [text]
inputs = {
ModalityType.TEXT: data.load_and_transform_text(text, device)
}
vec = getEmbeddingVector(inputs)
return(vec)
# Helper function to view the results of our similarity search
def viewResults(results):
for index, row in results[0].iterrows():
if row[1] == 'image':
image = Image.open(row[0])
display(image)
elif row[1] == 'text':
text = read_text_from_file(row[0])
print(text)
# Multimodal search function, identifies most relevant images and text within the vector database
def mm_search(query):
image_results = table.search(query, n=2, filter=[("like", "media_type", "image")])
text_results = table.search(query, n=1, filter=[("like", "media_type", "text")])
results = [pd.concat([image_results[0], text_results[0]], ignore_index=True)]
viewResults(results)
return(results)Let us do a similarity search to retrieve the most relevant data to a query:
#Create a query vector to do similarity search against
query_vector = [QuerytoEmbedding("brown animal with antlers").tolist()]
#Execute a multimodal similarity search
results = mm_search(query_vector)The results!! We retrieved the three most relevant embeddings. Turns out it works pretty well, returning a text description of deer, and two pictures of antlered deer:

Method 2: Use Multimodal LLM to Summarize Images & Embed Text Summaries

Another way to approach multimodal retrieval and RAG is to transform all of your data into a single modality: text. This means that you only need to use a text embedding model to store all of your data within the same vector space. This comes with an additional cost of initially summarizing other types of data like images, video, or audio either manually or with an LLM.
With both text and image summaries embedded and stored in the vector database, multimodal similarity search is enabled. When the most relevant embeddings are retrieved, we can pass them to an LLM for RAG.
Now that we have a high level understanding of this method, it’s time to dive into some code! View the full notebook here for the details.
To get started we need a method to summarize images. One way to approach this is to encode an image in ‘base64’ encoding, and then send that encoding to a LLM like “gpt-4-vision-preview”.
import base64
# Helper function to convert a file to base64 representation
def encode_image(image_path):
with open(image_path, "rb") as image_file:
return base64.b64encode(image_file.read()).decode('utf-8')
# Takes in a base64 encoded image and prompt (requesting an image summary)
# Returns a response from the LLM (image summary)
def image_summarize(img_base64,prompt):
''' Image summary '''
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": prompt},
{
"type": "image_url",
"image_url": {
"url": f"data:image/jpeg;base64,{img_base64}",
},
},
],
}
],
max_tokens=150,
)
content = response.choices[0].message.content
return content
To embed text, whether from a file or from an LLM generated summary, a embedding model like “text-embedding-3-small” can be used:
def TexttoEmbedding(text):
embeddings = openai.Embedding.create(
input=text,
model="text-embedding-3-small"
)
embedding = embeddings["data"][0]["embedding"]
return(embedding)Now let’s set up an empty data frame to store file paths, data types, raw text, and embeddings within. We will also get a list of paths of the images and texts we will be storing in the vector database:
#Define a dataframe to put our embeddings and metadata into
#this will later be used to load our vector database
columns = ['path','media_type','text','embeddings']
df = pd.DataFrame(columns=columns)
#Get a list of paths for images, text
images = os.listdir("./data/images")
texts = os.listdir("./data/text")Loop through the text and image files, sending them through our helper functions to be embedded. Append a new row to the data frame for each text and image file with corresponding path, media_type, text (or summary), and embeddings:
# Embed texts, store relevant info in data frame
for text in texts:
path = "./data/text/" + text
media_type = "text"
text1 = read_text_from_file(path)
embedding = TexttoEmbedding(text1)
new_row = {'path': path,
'media_type':'text',
'text' : text1,
'embeddings': embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)
# Encode images with base64 encoding,
# Get text summary for encoded images,
# Embed summary, store relevant info in data frame
for image in images:
path = "./data/images/" + image
media_type = "images"
base64_image = encode_image(path)
prompt = "Describe the image in detail."
summarization = image_summarize(base64_image,prompt)
embedding = TexttoEmbedding(summarization)
new_row = {'path': path,
'media_type':'image',
'text' : summarization,
'embeddings': embedding}
df = pd.concat([df, pd.DataFrame([new_row])], ignore_index=True)We now have a data frame that contains the path, media type, text, and embeddings for all of our data! We will now set up our vector database (see method 1) and create a table with the following schema:
table_schema = {
"columns": [
{"name": "path", "pytype": "str"},
{"name": "media_type", "pytype": "str"},
{"name": "text", "pytype": "str"},
{
"name": "embeddings",
"pytype": "float32",
"vectorIndex": {"dims": 1536, "metric": "CS", "type": "flat"},
},
]
}
# First ensure the table does not already exist
try:
session.table("multi_modal_demo").drop()
time.sleep(5)
except kdbai.KDBAIException:
pass
# Create the table
table = session.create_table("multi_modal_demo", table_schema)Let’s populate our table:
#Insert the data into the table, split into 2000 row batches
from tqdm import tqdm
n = 2000 # chunk row size
for i in tqdm(range(0, df.shape[0], n)):
table.insert(df[i:i+n].reset_index(drop=True))Our vector database has been loaded with all of our data, we can try similarity search:
query_vector = [TexttoEmbedding("animals with antlers")]
results = table.search(query_vector, n=3)
viewResults(results)The results show that this method also works for multimodal retrieval!
Multimodal RAG
Each of these methods could act as the retrieval phase within a multimodal RAG pipeline. The most relevant pieces of data (both text or images) can be returned from the vector search and then injected into a prompt to send to the LLM of your choice. If using a multimodal LLM, both text and images can be used to augment the prompt. If using a text based LLM, simply pass in the text as is, and text descriptions of images.
The below architecture shows the high level flow of RAG:
- Ingest your data, chunk/summarize, embed
- Store embeddings in the vector database
- User query is embedded and used for semantic similarity search against the vector database
- Most relevant data is retrieved! (Text and Images in the case of multimodal RAG)
- Retrieved data and the user’s query are sent to the LLM
- The LLM generates a response for the user, using the retrieved data as context to answer the user’s query

After using the retrieval methods described in this article, you can pass retrieved data in the form of text or images to an LLM for generation to complete the RAG process. In the below example, we pass in a list of retrieved text data and the user’s prompt — the function builds a query and sends it to the LLM to then return a generated response.
For generation with a multimodal LLM that accepts both text and images as input, see the below code snippet that uses Google’s Gemini Vision Pro model:
import google.generativeai as genai
genai.configure(api_key = os.environ['GOOGLE_API_KEY'])
# Use Gemini Pro Vision model to handle multimodal inputs
vision_model = genai.GenerativeModel('gemini-1.5-flash')
# Generate a response by passing in a list containing:
# the user prompt and retieved text & image data
response = vision_model.generate_content(retrieved_data_for_RAG)
print(response.text)For generation with a text based LLM where we pass image summaries and text directly into the LLM, see the below code snippet that uses “OpenAI’s gpt-4-turbo-preview” model:
# Helper function to execute RAG, we pass in a list of retrieved data, and the prompt
# The function returns the LLM's response
def RAG(retrieved_data,prompt):
messages = ""
messages += prompt + "\n"
if retrieved_data:
for data in retrieved_data:
messages += data + "\n"
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{
"role": "user",
"content": [
{"type": "text", "text": messages},
],
}
],
max_tokens=300,
)
content = response.choices[0].message.content
return contentConclusion
The integration of various data types, such as text and images, into LLMs enhances their ability to generate more wholistic responses to a user’s queries. This article highlights the role that vector databases like KDB.AI have as the core of multimodal retrieval systems, enabling the coupling of relevant multimodal data with LLMs for RAG applications. Today we focused on images and text, but there is potential to bring together more types, opening up even greater horizons for new AI applications. This concept of multimodal RAG is an early, but important stride towards mirroring human-like perception in machines.
Connect with me on LinkedIn!

Sources:
https://github.com/facebookresearch/ImageBind
https://platform.openai.com/docs/guides/embeddings
https://ai.google.dev/models/gemini
https://github.com/google/generative-ai-docs/blob/main/site/en/tutorials/python_quickstart.ipynb
