PinnedAniket RaoHow we won Dukaan over5 meetings. 1 month. From introductions, to a demo, and ultimately winning Dukaan over. Subhash and his team’s velocity on decision-making,Sep 21, 2022Sep 21, 2022
PinnedPiyush VermaSample vs Metrics vs CardinalityWhen dealing with Time Series databases, I always got confused with Sample vs Metrics vs Cardinality. Here’s an explanation as I have…Aug 22, 2022Aug 22, 2022
PinnedPiyush VermaYour Percentiles are incorrect P99 of the times.Why is it important to understand percentiles in depth? Because one of the critical Indicators, Latency, is measured in percentiles.Nov 21, 20201Nov 21, 20201
Akash SaxenaObservability — That Last 9TL;DR: A stitch in time, saves 9. A discussion on the key blocks of observability.Sep 30, 2022Sep 30, 2022
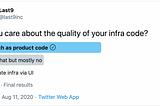
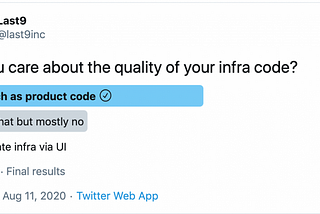
Piyush VermaMuch that we’ve gotten wrong about Site Reliability EngineeringAn illustrated summary of Developers to DevOps to Site Reliability EngineeringNov 19, 2020Nov 19, 2020
Piyush VermaRoot Cause Analysis For Reliability: A Case StudyWikipedia defines Root Cause Analysis (RCA) as “a method of problem-solving used for identifying the root causes of faults or problems.”Nov 3, 2020Nov 3, 2020